Kafka를 띄워보자!!
필자는 AWS의 환경에서 Kafka를 띄우기로 하여 AWS에서 제공해주는 Kafka Cluster인 MSK를 활용하였습니다.
MSK의 설정하는 과정을 아래의 그림과 함께 설명해드리겠습니다.
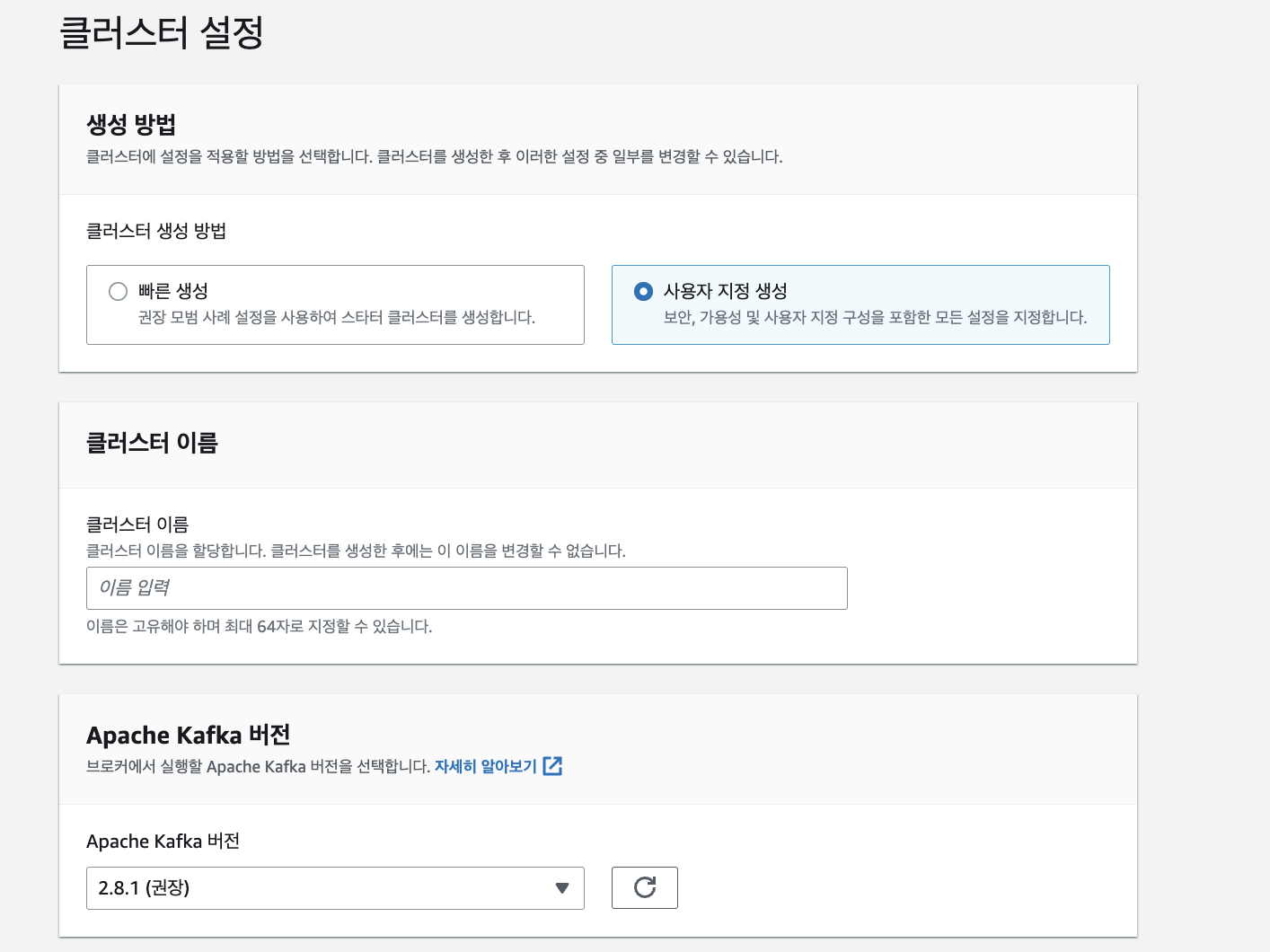
-
필자는 사용자 지정 생성 방식으로 MSK를 생성하였습니다.
그 다음 클러스터의 이름을 만들고, Kafka의 버전을 선택합니다.
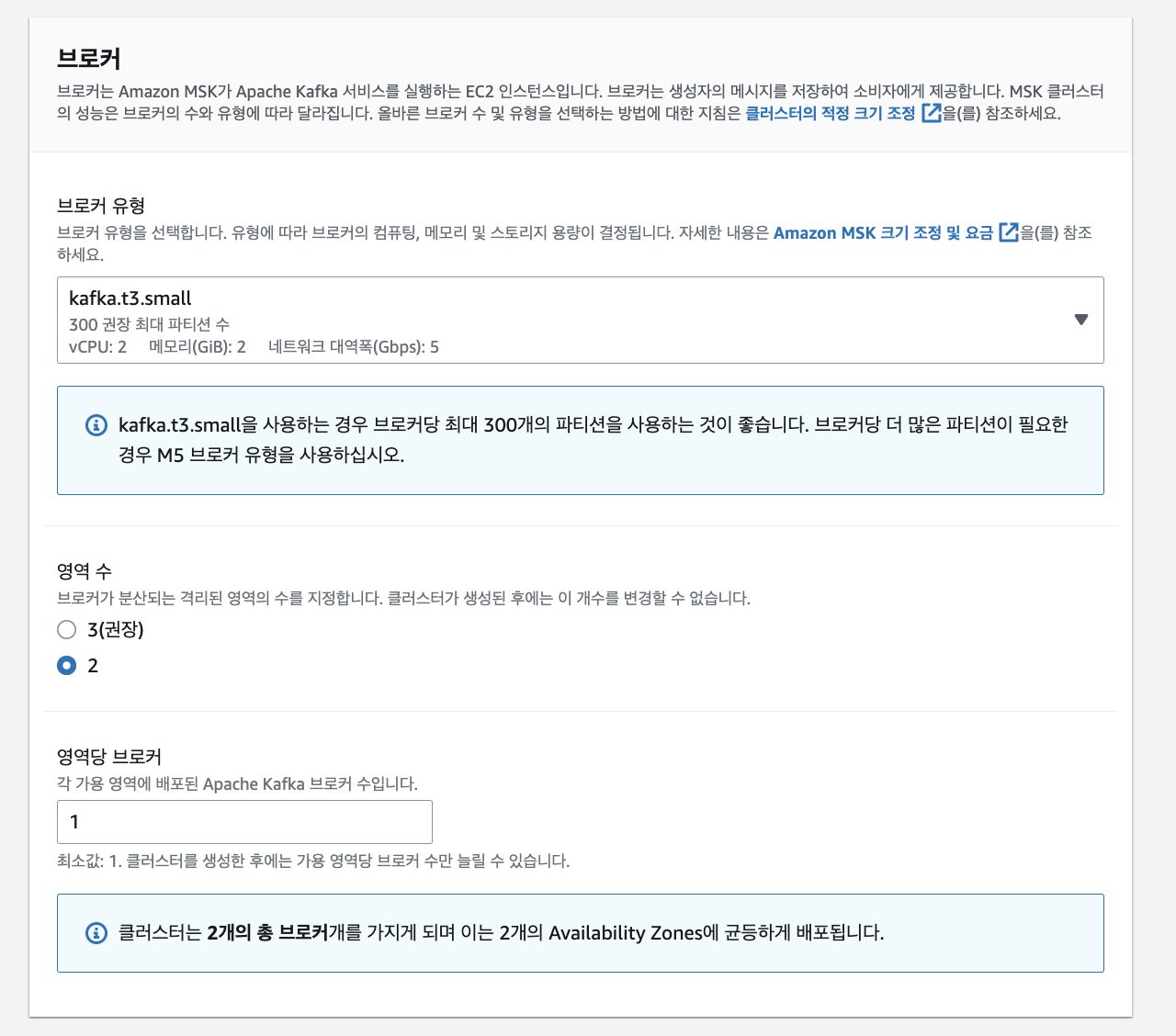
-
그 다음은 브로커 설정입니다.
AWS에서는 브로커의 Type을 고를 수 있는데 브로커의 CPU와 메모리를 설정할 수 있습니다. Test용이기에 제일 작은 small 유형으로 만들었고, 그 다음 영역 수를 선택합니다. 참고로 영역 수는 Subnet보다 작아야합니다.
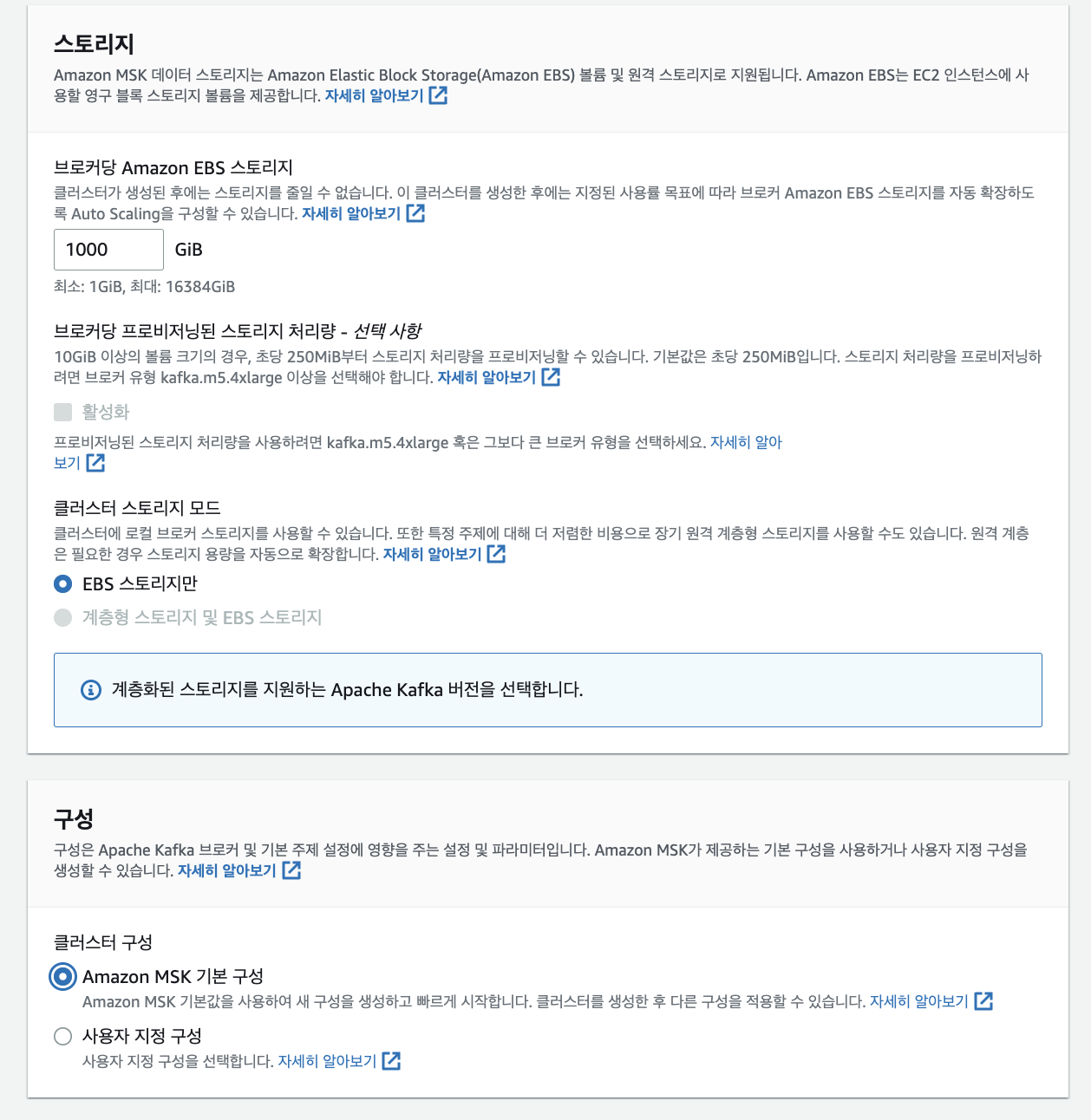
-
그 다음 스토리지 및 구성은 AWS의 기본 구성에 따라 진행하였습니다.
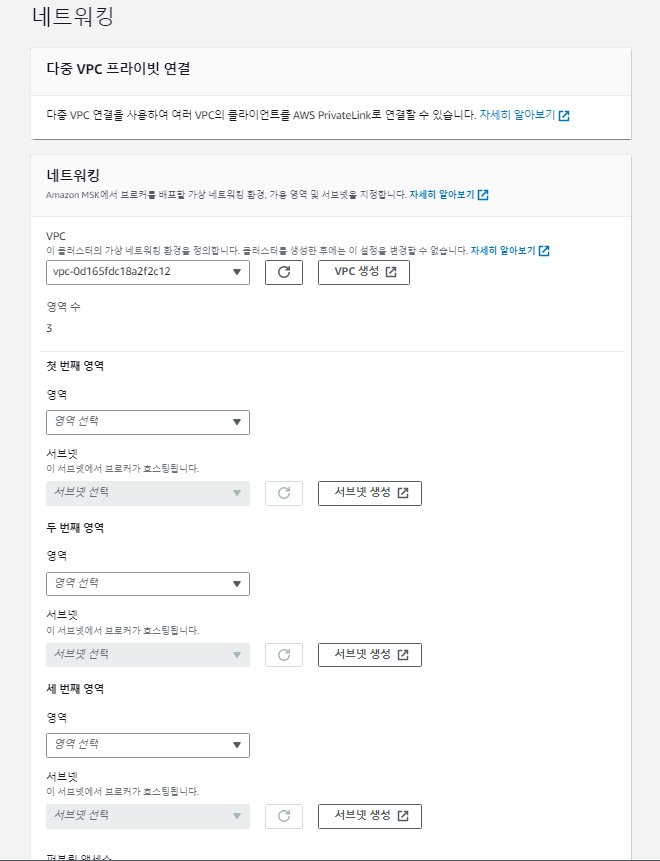
-
다음 버튼을 누르시면 이제 어떤 VPC와 Subnet을 이용할 것인지 설정하는 페이지가 나타납니다.
여기서 주의할 점은 맨 위에 보시면 프라이빗이라는 단어가 보이실껍니다. AWS MSK는 기본적으로 프라이빗한 클러스트를 구축하므로 외부에서 직접적으로 접속을 못합니다.물론 퍼블릭 엑세스를 직접 허용하는 방법도 있지만 필자는 그 방법보다 추후에 설명드릴 EC2를 띄운 후 Kafka Client로 접속하였습니다. (이 부분을 다음 글에서 보여드릴 예정이니 그 때 한번 더 보시면 이해하시기 편할 것입니다.)
-
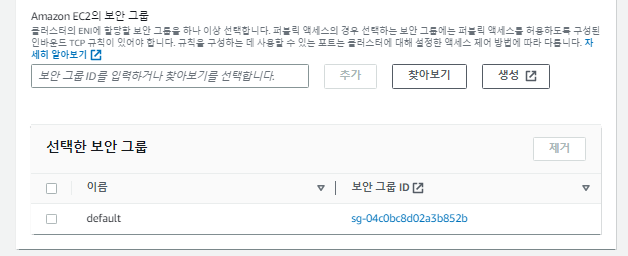
그 다음은 보안 그룹을 설정하는 부분입니다. 이 부분에서 어떠한 트래픽들은 허용하고 차단할지 설정해주시면 됩니다.
-
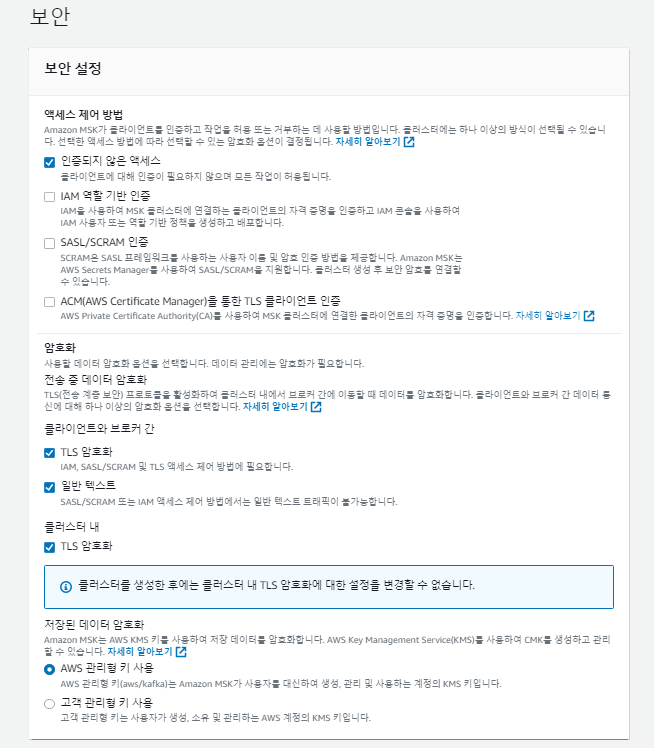
이번에는 클러스터 자체에 대한 보안을 설정하는 부분입니다. 여러 방법으로 인증하는 방법들이 있는데 필자는 Test 및 개발 용도이기에 모든 작업이 허용되게 끔 엑세스 설정을 하였고, 암호화 기법에는 일반텍스트 허용까지 체크해 주었습니다.
나중에 엔드포인트 생성을 위해 일반텍스트 체크를 해주시면 그 엔드 포인트를 통해 클라이언트와 연결을 할 수 있으므로 생성해주시는게 편합니다.
-
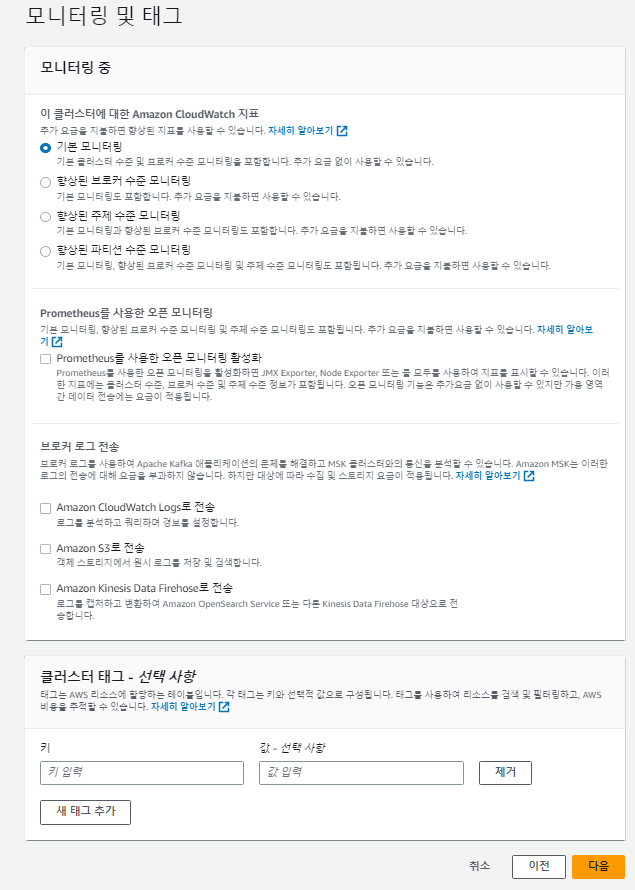
마지막으로는 MSK에 대한 로그 및 모니터링을 위한 설정입니다. AWS는 기본적인 모니터링도 제공하지만 추가적으로 프로메테우스나 S3 등으로 모니터링 및 로그를 수집할 수 있는 기능도 제공합니다. 필자는 기본으로 제공하는 것만 사용하였습니다.
-
이 부분까지 끝나면 클러스터에 설정한 조건들을 마지막으로 보여주고 클러스터 생성을 하겠냐는 페이지가 나옵니다. 한 번 더 검토하시고 생성 버튼을 눌러주시면 생성이 됩니다!!!!
아 이 때 대략 15분 정도 걸린다고 하지만 실제로 30분 정도 걸리시니 다른 작업을 하시거나 커피 한잔 드시고 계시면 되겠습니다.
글을 마무리 지으며
이번 글에서는 AWS MSK를 통해 kafka를 띄우는 법을 보았습니다. 다양한 블로그들을 보면 대부분 Docker로 로컬에서 kafka를 띄우시는데 필자는 ELK와 연동을 위해 AWS MSK를 활용해 보았습니다!!!
다음 글에서는 이제 EC2에서 kafka client를 통해 제대로 MSK가 동작하는지 확인 할 예정입니다.
긴 글 읽어주셔서 정말 감사하고 끝까지 봐주셨으면 좋겠습니다 ㅎㅎ
