
Title
- M3D-VTON: A Monocular-to-3D Virtual Try-On Network (2021)

Abstract
- 3D 가상 시착은 온라인 쇼핑에 대한 직관적이고 현실적인 시각을 제공하며, 엄청난 상업적 가치를 가지고 있음.
- 하지만 기존의 3D 가상 시착 방법들은 주로 주석이 달린 3D 인체 형태와 의상 템플릿에 의존하므로, 실제 상황에서의 응용에 제한이 있음.
-> 2D 가상 시착 방법은 옷을 입은 인체를 빠르게 조작할 수 있는 대안을 제공하지만, 풍부하고 현실적인 3D 표현이 부족함.
- 논문에서는 2D와 3D 방법 모두의 장점을 기반으로 하는 새로운 Monocular-to-3D Virtual Try-On Network (M3D-VTON)을 제안함.
🤜 이 네트워크는 2D 정보를 효율적으로 통합하고, 2D 표현을 3D로 전환하는 매핑을 학습하여, 목표 의류와 사람 이미지만을 입력으로 사용하여 3D 시착 메시를 복원함.
- 제안된 M3D-VTON에는 세 가지 모듈이 포함됨.
1) 초기 전체 신체 깊이 맵을 추정하고, 두 단계의 warping procedure를 통해 2D 의류-사람 정렬을 완성하는 Monocular Prediction Module (MPM)
2) 초기 신체 깊이를 정제하여 더욱 자세한 주름과 얼굴 특성을 생성하는 Depth Refinement Module (DRM)
3) warped 의류와 목표가 아닌 신체 부분을 결합하여 결과를 정제하는 Texture Fusion Module (TFM). 또한 각 사람 이미지가 앞면과 뒷면 깊이 맵과 연관된 고품질의 Monocular-to-3D 가상 시착 데이터셋을 구축함.
- 광범위한 실험들은 제안된 M3D-VTON이 주어진 의류를 입은 3D 인체를 매력적인 상세 정보와 함께 조작하고 복원할 수 있으며, 다른 3D 방법들보다 효율적임을 보여줌.
1. Introduction
가상 시착의 중요성
- 가상 시착(Virtual Try-On)은 온라인 쇼핑에서 중요한 부분이 되어왔음.
- 사용자가 온라인으로 의상을 시착해보며 적절한 선택을 할 수 있게 해주기 때문
- 이와 관련하여 이미지 기반 가상 시착 연구는 목표 인물에 상점 의류를 맞추는 것을 목표로 하며, 대부분의 연구들은 Thin Plate Spline (TPS) 변환을 활용하여 옷과 인물 간의 정렬과 융합을 달성
기존 연구의 한계
- 기존의 가상 시착 연구는 주로 2D 이미지에 중점을 둠. 그러나 2D 방법론은 3D 세계의 복잡한 신체 동작과 의상의 상호 작용을 완벽하게 반영하지 못함.
3D의 필요성
- 3D 방법론은 사용자의 실제 신체와 의상 간의 상호 작용을 더 잘 반영할 수 있음.
- 그러나 단안 카메라 이미지에서 3D 정보를 복원하는 것은 어려운 작업임.
본 연구의 제안
- 2D/3D 방법의 위의 제한을 해결하기 위해, 본 논문에서는 2D 이미지 기반 가상 시착과 3D 깊이 추정을 통합하여 최종 3D 시착 메시를 재구성하는 경량화되면서도 효과적인 Monocular-to-3D Virtual Try-On Network (M3D-VTON)을 제안함.
🤜 이 방법은 사용자의 3D 신체 모델과 의상의 3D 모양을 추정하여, 사용자에게 의상을 시착하게 된다.
- M3D-VTON은 세 가지 모듈로 구성되며, 이 중 첫 번째 파트는 Monocular Prediction Module (MPM)로, TPS 변환의 파라미터를 회귀시키고, 상점 의류와 호환되는 조건부 사람 segmentation을 예측하며, 전체 신체 깊이 맵을 추정하는데 사용
- 새로운 합성 3D 가상 시착 데이터셋인 MPV-3D를 구축하였으며, 다른 3D 시착 방법과 비교하여 M3D-VTON은 상세한 신체 형태와 현실적인 텍스처 색상을 복원하면서 계산 효율성이 더 높음.
2. Related Work
2.1. 2D Virtual Try-on
- 2D Virtual Try-on의 목적은 목표 의류를 참조 인물에 전송하는 것임.
기존연구
- 많은 연구들이 비강성 TPS 변환을 활용하여 매력적인 가상 시착 결과를 얻음.
- 대부분의 연구는 VITON을 기반임.
VITON은 TPS로 상점 의류를 warping한 후 최종 시착 결과를 렌더링하는 대략적으로 세밀한 구조를 제안
CP-VTON은 기하학적 매칭 모듈을 추가로 훈련시키고 의류와 인물을 더 잘 결합하기 위해 합성 마스크를 사용함.
VTNFP는 합성 가이드로서 신체 segmentation을 활용하여 더욱 선명한 피부 질감을 생성
ACGPNv은 warping과정을 안정화하기 위해 TPS 매개변수에 대한 2차 제약을 제안
본 연구의 차별점
-> 앞서 언급된 방법들의 장점을 상속받을 뿐만 아니라 현실적인 3D 옷을 입은 인체를 생성하여, 단안에서 3D로의 가상 시착에 대한 경제적인 해결책을 제공해줌.
2.2. 3D Virtual Try-on
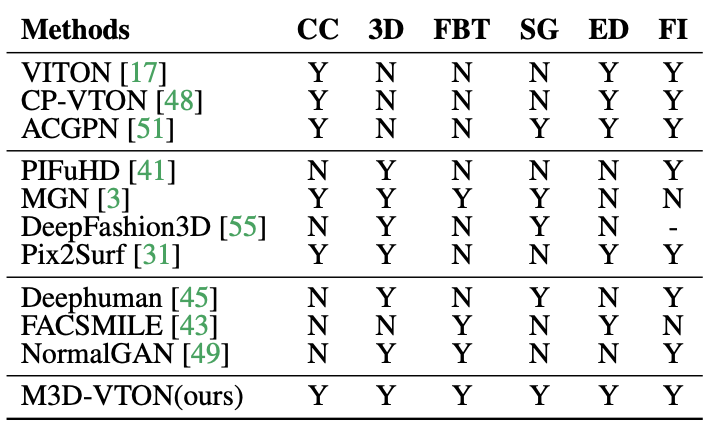
- 3D 인체 재구성 및 성능 캡처 작업에 비해, 복잡한 옷의 변형으로 인해 3D 가상 시착은 더욱 도전적임.
기존연구
PIFuHD: 실제 옷 디테일을 생성하는 고품질의 단일 뷰 3D 인체 재구성 파이프라인을 제공하지만, 의류 전송을 수행할 수 없음.
MGN: SMPL 모델 위에 의류 기하학을 예측하며, 계층적 표현 덕분에 다양한 신체 형태와 포즈를 착용할 수 있음. 그러나 미리 정의된 디지털 옷장에서 의류로 제한됨.
DeepFashion3D: 더 도전적인 옷 재구성을 위해 더 많은 3D 의류 데이터를 제공
Pix2Surf: 2D 의류 실루엣과 3D 의류 표면의 UV 맵 사이의 밀집 대응을 학습하여 SMPL 모델에 더 많은 야외 의류 이미지를 전송하려고 했음.
하지만 DeepFashion3D와 Pix2Surf 모두 신체 텍스처를 표시할 수 없음.
제한점
- 기존 방법들은 훈련을 위해 스캔된 3D 데이터셋이 필요함.
- 이는 제안된 고품질 합성 데이터셋과 비교하여 수집하는 데 비용이 많이 필요함.
본 연구의 장점
- 옷을 입은 신체 형태와 텍스처 모두를 복구할 수 있으며, 3D 시착에 대한 더 실용적인 해결책을 제공해줌.
2.3. Human Depth Estimation
- 깊이 맵을 예측하여 형태의 상세 정보를 더 잘 포착하기 위해 non-parametric 3D human reconstruction이 제안됨.
기존연구
Moulding Humans: 단일 RGB 이미지에서 전면과 후면의 깊이 맵을 추정하여 텍스처가 없는 3D 인체를 생성
FACSMILE: 비슷한 접근법을 사용하지만 지역 깊이 상세 정보를 조각하는 데 정상 제약을 추가하지만, 옷을 고려하지 않은 알몸을 조작함.
DeepHuman: 정상 맵을 활용하여 추정된 깊이를 세밀화하지만, 실제 응용 프로그램에 제한이 있는 전면 신체 부분만 생성함.
NormalGAN: 정상 맵에 조건을 부여한 적대적 학습 프레임워크를 추가로 사용하여 텍스처가 있는 3D 인체를 복구함. 그러나 NormalGAN은 비싼 깊이 센서를 사용하여 수집해야 하는 지상 진실 깊이 맵을 입력으로 필요로 함.
본 연구의 장점
- M3D-VTON은 고품질 합성 데이터에서 훈련되며, 옷을 고려한 인체 조작을 허용함.
3. M3D-VTON

- 3D 가상 시착을 용이하게 하기 위해, 의류 이미지 사람 이미지 를 입력으로 받아 옷을 바꾸고 사람의 정체성을 유지한 3D 시착 메시 를 재구성하는 새로운 Monocular-to-3D Virtual Try-On Network (M3D-VTON)을 제안
- M3D-VTON은 다음과 같이 구성됨.
1) Monocular Prediction Module (MPM)
-
과정: 의류를 제거하여 의류에 중립적인 사람 표현 를 얻음. -
작업: 상점 의류 를 자기 적응 사전 정렬을 통해 왜곡된 의류 로 변형하고, 사람 segmentation 를 예측하며, 초기 이중 깊이 맵 를 추정함.2) Depth Refinement Module (DFM)
-
입력: 더블 깊이 맵 , 왜곡된 의류 , 보존된 인물 부분 , 그들의 그림자 정보
-
기능: 새로운 깊이 gradient 제약을 포함하여 초기 깊이 맵을 세밀화하고 더 많은 지역적인 세부 사항(옷 주름, 얼굴 구조 등)을 생성함.3) Texture Fusion Module (TFM)
과정: MPM에서의 의미론적 레이아웃을 지침으로 사용하여 왜곡된 옷과 보존된 텍스처 정보를 융합하여 결과 를 렌더링함.
결과: 와 세밀화된 깊이 맵 이 공간적으로 정렬되면 RGB-D 표현을 형성하며, 색칠된 포인트 클라우드를 직접 얻고, 목표 옷을 착용하고 정체성이 보존된 3D 옷을 입은 인간 를 얻기 위해 그것들을 삼각화함.
3.1. Monocular Prediction Module
3.2. Depth Refinement Module
3.3. Texture Fusion Module
4. Experiments
4.1. Dataset Generation
- MPV-3D, 기존의 MPV 데이터셋을 기반으로 함.
- 다양한 포즈와 상의 의류를 포함하는 인물 이미지를 포함. 그리고 총 6566개의 의류-인물 이미지 쌍이 있으며, 각 인물 이미지는 전면과 후면 깊이 맵과 연결됨.
- MPV 데이터셋의 전면 인물 이미지에 PIFuHD를 적용하여 깊이 맵을 얻음.
- 학습용 데이터 5632개, 테스트 데이터 934개로 구성됨.
4.2. Implementation Details
- MPM은 DRM 및 TFM의 입력을 제공하기 때문에 별도로 훈련되며, DRM과 TFM은 함께 훈련됨.
- 각 모듈은 Adam 최적화를 사용하여 100 에포크 동안 훈련됨. 초기 학습률은 0.0002이며 마지막 50 에포크에서 0으로 선형 감소함. + batch크기: 8
- Pytorch로 구현되었고, 단일 NVIDIA 2080ti GPU에서 훈련됨.
- 테스트 중에는 대상 의류가 인물의 의류와 다르며, inference은 end-to-end로 수행됨.
4.3. 2D Try-on Comparison with SOTA methods

- 현존하는 최첨단 2D 시착 방법들인 VITON, CP-VTON, CP-VTON+, ACGPN과 비교함.
VITON: 의류의 텍스처 세부 사항이 부족하며, 자체 은폐 사례에서 팔을 합성하지 못함.
CP-VTON 및 CP-VTON+: 의류 텍스처를 더 잘 보존하지만, 의류가 신체 부분에 의해 가려질 때 잘 작동하지 않음.
ACGPN: 완전한 팔을 합성하지 못하며, 세그먼테이션 추정 네트워크에 의해 도입된 확률성 때문에 옷 지역에 아티팩트를 합성할 수 있음.
M3D-VTON: 두 단계 왜곡 전략 덕분에 의류 텍스처를 더 정확하게 보존하며, 조건부 segmentation 및 신체 깊이 맵의 협력적 지침을 통해 신체 부분을 정확하게 합성함.

- 2D 시착 방법과의 양적 비교 결과임.
- 공정한 비교를 위해, 전체 신체 시착 결과를 다른 방법처럼 상반신만 보이도록 자르고 크기를 조정
- M3D-VTON은 가장 낮은 FID와 가장 높은 인간 평가 점수를 얻음. 그 SSIM 점수는 최고 성능 모델과 동등함.
4.4. 3D Try-on Comparison with SOTA methods

- 본 연구는 단안에서 3D 가상 시착 설정을 탐구하는 첫 번째 작업이므로, 3D 시착 비교를 수행하기 위해 세 가지 혼합 모델을 설계함.
- CP-VTON을 사용하여 2D 가상 시착 결과를 얻은 다음, PIFu, NormalGAN, Deephuman과 같은 최첨단 3D 인간 재구성 방법을 사용하여 3D 시착 메쉬를 생성함.
CP-VTON+PIFu: 신빙성 있는 3D 형상 결과를 생성하지만 불안정한 암시적 텍스처 색상 추론 때문에 세부 텍스처를 복구하지 못함.
NormalGAN: 2D 이미지를 메쉬 텍스처로 직접 설정함. 그러나, 그것은 뒷모습을 추론하기 위해 노이즈가 있는 실제 깊이 맵을 입력으로 필요로 하며, M3D-VTON보다 더 현실적이지 않은 3D 인물을 생성함.
M3D-VTON: 하나의 모델 내에서 더 현실적인 3D 인물을 생성하고 세부 텍스처를 보존함.
-> M3D-VTON은 주어진 MPV-3D 이미지 쌍에 대해 약 4초 동안 실행되며, 다른 순수 3D 가상 시착 방법이나 3D 인간 재구성 방법보다 훨씬 빠르고 효율적임.
5. Conclusion
- 2D 정보에서 3D 시착 메시를 생성하기 위해 2D와 3D 접근법의 장점을 모두 활용하는 계산 효율적인 Monocular-to-3D Virtual Try-On Network (M3D-VTON)를 제안
- M3D-VTON은 3D 시착 작업을 2D 시착과 신체 깊이 추정 문제로 분해함.
- 더 현실적인 텍스처 융합 결과를 얻기 위해, M3D-VTON은 두 단계 왜곡 전략과 segmentation 및 detailed depth maps을 사용한다.
- 더욱 상세한 깊이 맵을 생성하기 위해 새로운 깊이 그라디언트 제약을 도입
- 이 연구는 단안 3D 가상 시착 작업에 대해 더 빠르고 경제적인 해결책을 제공해줌.
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
- 저자는 2D 정보만을 사용하여 3D 가상 시착 메시를 생성하는 새로운 Monocular-to-3D Virtual Try-On Network (M3D-VTON)을 제안.
- 이 방법은 기존의 2D 및 3D 접근 방식의 장점을 모두 활용하며, 목표로 하는 옷과 사람 이미지만을 입력으로 사용하여 3D 시착 메시를 재구성하려는 시도를 함.
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
- Monocular Prediction Module (MPM)
: 초기 전체 몸 깊이 맵을 추정하고, 두 단계 왜곡 절차를 통해 2D 옷-사람 정렬을 수행
- Depth Refinement Module (DRM)
: 초기 몸 깊이를 세밀화하여 더 자세한 주름과 얼굴 특성을 생성
- Texture Fusion Module (TFM)
: 왜곡된 옷과 비-목표 몸 부분을 융합하여 결과를 정제
- 어느 프로젝트에 적용할 수 있는가?
- 3D 가상피팅
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- VITON, CP-VTON, CP-VTON+, ACGPN: 2D 가상 시착 방법에 관한 연구
- PIFu, NormalGAN, Deephuman: 3D 인간 재구성에 관한 연구.
- SMPL 모델, Multi-Garment Net, PIFuHD: 3D 가상 시착 및 인간 모델링 관련 연구.
- 느낀점은?
📚 References
논문

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊