[논문리뷰 | Speech] HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units (2021) Summary
2
[논문리뷰]
목록 보기
25/42
Title
- HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units

Abstract
📌 문제정의
- 자기 지도학습을 통한 음성 표현 학습에는 세 가지 고유한 문제가 있었음.
- 각 입력 발화에 여러 소리 단위가 포함되어 있음.
- 사전 학습 단계에서 입력 소리 단위에 대한 어휘가 없음.
- 소리 단위는 명확한 분할 없이 다양한 길이를 가지고 있음.
📌 제안 방법
- 이 문제를 해결하기 위해, BERT와 유사한 예측 손실에 대한 정렬된 Target Label을 제공하는 offline clustering를 활용하는
Hidden-Unit BERT (HuBERT)방법을 제안함.
- 핵심은 마스크된 영역에만 예측 손실을 적용하는 것임.
이로 인해 모델의 연속 입력에 대한 결합된 음향 및 언어 모델을 학습하게 됨.
- HuBERT는 지정된 군집 레이블의 본질적인 품질보다는 비감독 군집화 단계의 일관성에 주로 의존함.
📌 실험 결과 및 성과
- 간단한 k-means 클러스터링을 사용하여, HuBERT 모델은 Librispeech와 Libri-light 벤치마크에서 최첨단 wav2vec 2.0 성능에 부합하거나 향상시킴.
- 1B 매개 변수 모델을 사용하여, HuBERT는 더 어려운 dev-other 및 test-other 평가 하위 집합에서 최대 19% 및 13%의 상대적 WER 감소를 보여줌.
1. Introduction
📌 서론
- 인간이 첫 언어를 배우는 것처럼 청취와 상호 작용을 통해 음성과 오디오 표현을 학습하는 것은 많은 연구 프로그램의 핵심 목표였음.
- 고품질 음성 표현은 말한 내용의 다양한 측면과 감정, 주저함, 중단과 같은 방식으로 전달되는 비어휘 정보를 포함함.
- 전체 상황의 이해를 달성하기 위해서는
웃음, 기침, 입 끝말이기, 배경 소음등과 같은 구조적인 잡음을 모델링해야 함.
📌 자기 지도 학습의 필요성
- 고품질 표현의 필요성은 입력 신호 자체에서 학습 프로세스를 주도하는 목표를 추출하는 자기 지도 학습의 연구를 촉진
- 이러한 방식은 훈련 중 언어 자원에 의존하지 않아 보다 보편적인 표현을 학습할 수 있음.
📌 Pseudo-Labeling(PL)과 self supervised representations
- Pseudo-Labeling은 라벨이 없는 음성과 오디오를 활용하는 주요 접근법이었으며 1990년대 중반부터 성공적인 응용이 있었음.
- 이는 student model이 teacher model을 단순히 모방하도록 강제하지만, 자기 지도 전제 작업은 모델이 학습된 잠재 표현에 훨씬 더 많은 정보의 비트를 압축하여 전체 입력 신호를 표현하도록 강제하는 장점이 있음.
- Pseudo-Labeling에서는 teacher model의 지도 데이터가 전체 학습을 단일 하류 작업을 향하도록 만드는 반면, 자기 지도 특징은 다양한 하류 응용 프로그램에 대한 더 나은 일반화를 보여주는 등의 장점이 있음.
📌 Hidden unit BERT (HuBERT)
- 이 모델은 양쪽 모두의 특징, 즉 음향 및 언어 모델을 학습하도록 강제됨.
- 이 작업을 통해 중요한 통찰력을 얻게 되며, 이는 모델이 입력 데이터의 순차적 구조를 모델링하는 데 중점을 둘 수 있도록 함.
2. Method
2.1. Learning the Hidden Units for HuBERT
-
배경
- 전통적인 음향 모델은 텍스트와 음성 쌍에 대해 학습되며 강제 정렬을 통해 각 프레임에 대한 의사-음성 레이블을 제공합니다. 반면, 자기 지도 학습 설정은 음성 데이터만을 사용합니다 -
Hidden Units
- 간단한 이산 잠재 변수 모델들 ex)k-means와가우시안 혼합 모델 (GMMs)은 기본 음향 유닛과 무시할 수 없는 상관 관계를 보이는 Hidden Units를 추론함.
- 그래픽 모델 or 더 강력한 신경망 모델로 분포를 파라미터화함으로써 더 진보된 시스템들은 더 나은 음향 유닛 발견 성능을 달성할 수 있음.
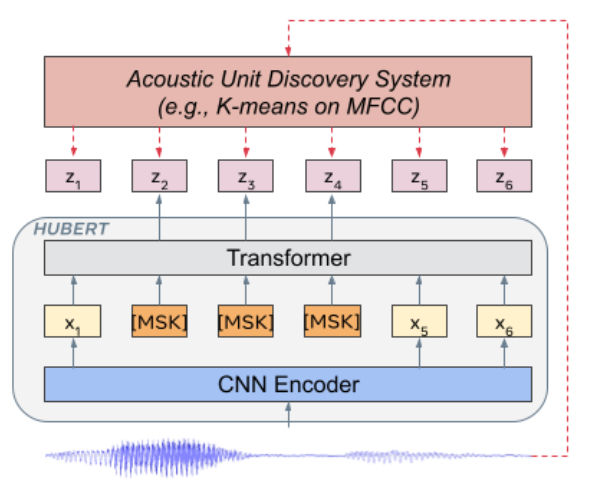
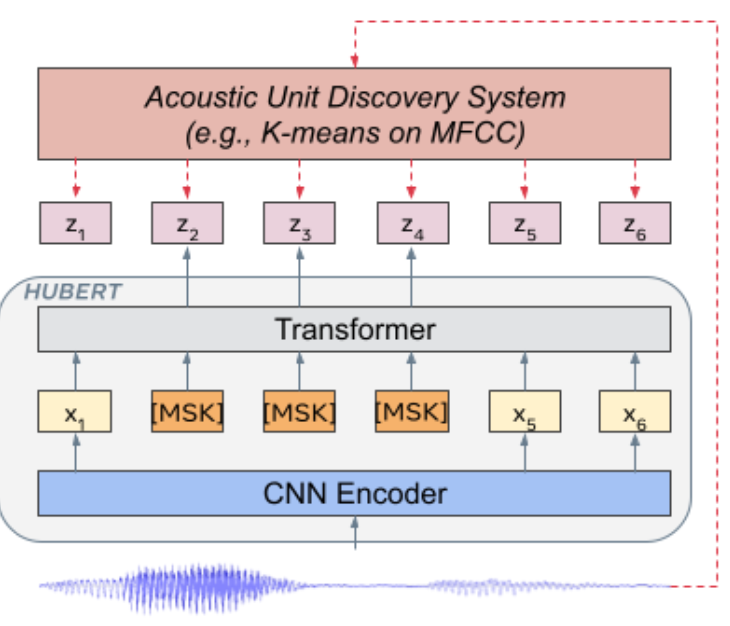
- HuBERT 방식은 하나 이상의 K-means Clusterinig 반복으로 생성된 Masked된 프레임의 숨겨진 클러스터 할당을 예측함.
- acoustic unit 모델은 frame 타켓을 제공
- 는 프레임의 음성 발화를 나타내며, 발견된 Hidden Units은 로 표시됨.
- 여기서 각 는 class 범주 변수임.
- 는 클러스터링 모델, k-means임.
2.2. Representation Learning via Masked Prediction

3. Related Work
4. Experimental Details
4.1. Data
- 비지도 학습용 데이터
- LibriSpeech 오디오의 전체 960시간 사용.
- Libri-light 오디오의 60,000시간 사용.
두 데이터 모두 LibriVox 프로젝트에서 파생되며, 자원봉사자가 인터넷에서 제공하는 저작권이 없는 오디오북의 영어 녹음을 포함
- 지도 학습용 데이터
다음 다섯 가지 파티션 사용
- Libri-light 10분
- 1시간, 10시간 분할
- LibriSpeech 100시간 (train-clean-100) - 960시간 (train-clean-100, train-clean-360, train-other-500 합친 것).
- 세 Libri-light 분할은 LibriSpeech 교육 분할의 하위 집합이며, 각각 train-clean의 오디오의 절반과 train-other-500의 다른 부분을 포함
5. Results
5.1. Main Results - Low-and Hight-Resource Setups
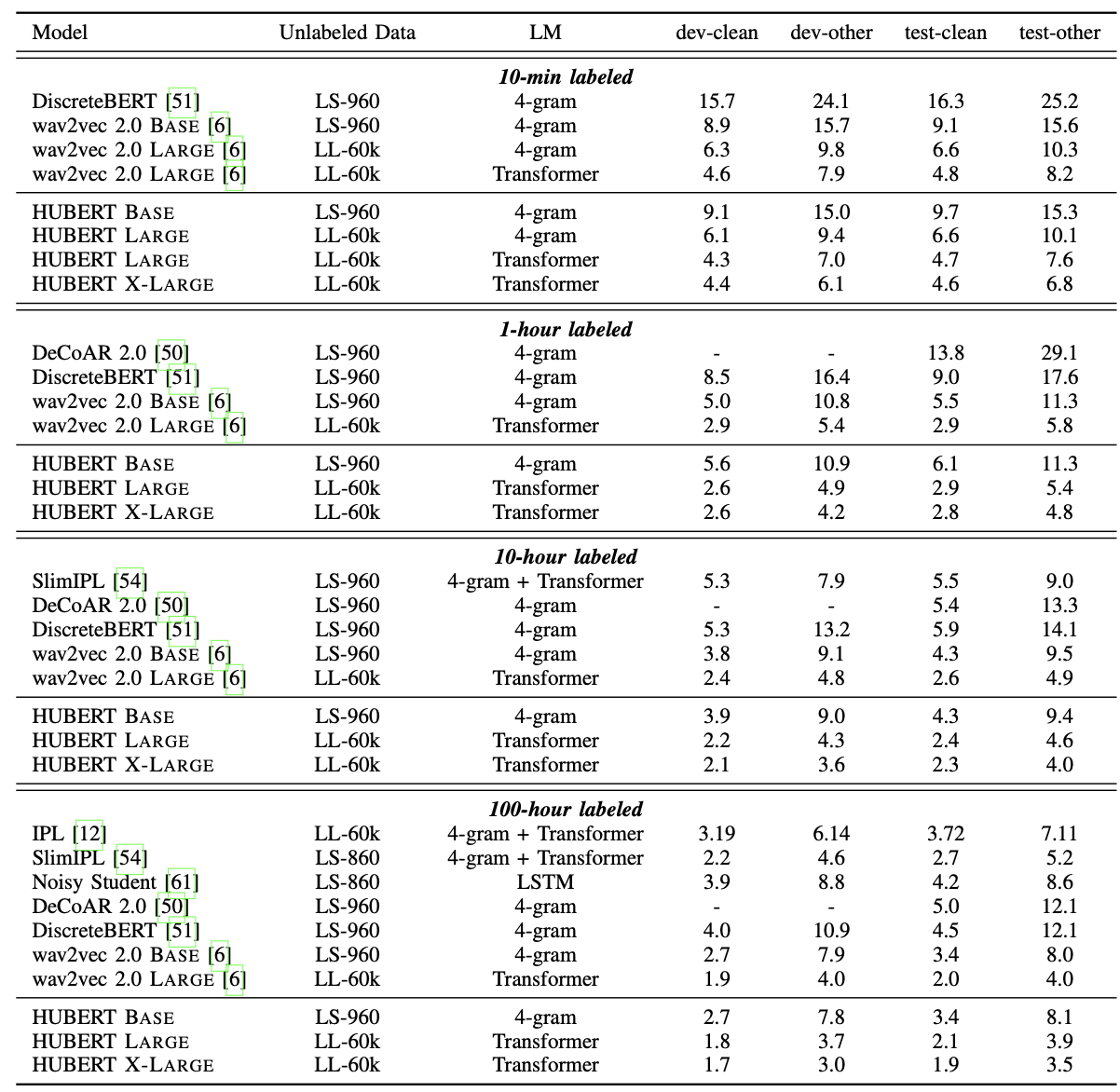
- 레이블이 부착된 데이터로 사전 학습된 모델을 미세 조정(fine-tuning)함: 10분, 1시간, 10시간, 100시간.
- HuBERT의 자기 지도 학습(pre-training) 방법의 확장성을 보여줌.
- HuBERT LARGE 모델은 레이블이 붙은 데이터로 단 10분만으로 test-clean 세트에서 WER 4.7%, test-other 세트에서 WER 7.6%를 달성할 수 있음.
- 1B 파라미터로 모델 크기를 더 확장하면, HuBERT X-LARGE 모델은 test-clean에서 WER 4.6%, test-other에서 WER 6.8%로 더 줄일 수 있음.
다른 연구와의 비교를 확인해보면,
- HuBERT는 DiscreteBERT를 모든 설정에서 크게 앞섬.
- 두 모델 모두 발견된 유닛의 마스크된 예측으로 거의 동일한 목표로 훈련됨.
- 정보 손실을 피하기 위해 모델의 입력으로 파형(waveform)을 사용하는 것이 중요하다는 것과, 제안된 반복적 개선(iterative refinement)이 결국 더 나은 유닛을 학습한다는 두 가지 주요 사실을 나타냄.
960시간 Librispeech 데이터에서의 HuBERT 모델 미세 조정 결과
- HuBERT는 지도 및 자체 교육 메서드의 최신 기술을 능가하고 있음.
- 그러나 미세 조정과 자체 교육을 결합하는 방법보다 뒤쳐짐.
- 사전 훈련된 HuBERT 모델이 의사 라벨링에 사용되는 사전 훈련된 모델과 동등하거나 나을 것으로 기대됨.
5.2. Analysis: K-Means Stability
목적
- 발견된 유닛의 마스크된 예측이 효과적인 이유를 이해하기 위해 k-평균 클러스터링 알고리즘의 안정성을 조사.
특징 고려
- 39차원 MFCC 특징
- 첫 번째 반복의 HuBERT-BASE 모델의 6번째 트랜스포머 계층에서의 768차원 출력.
k-평균 클러스터링 상세
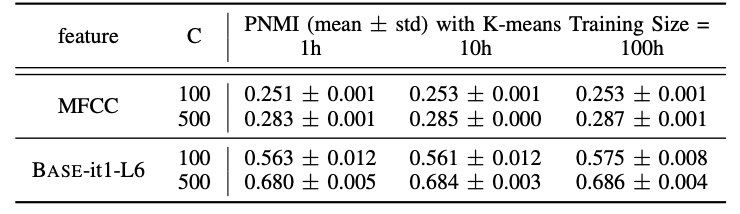
- K = {100,500} 클러스터 고려
- LibriSpeech 훈련 분할에서 샘플링된 {1, 10, 100} 시간의 음성에 적합.
- 각 하이퍼파라미터 및 특징 조합에 대해 10번 시행
결과
- k-means 클러스터링은 다양한 하이퍼파라미터와 특징에 걸쳐 작은 표준 편차를 갖기 때문에 합리적으로 안정적
- k-means 모델에 사용되는 데이터의 양을 늘리면 일반적으로 PNMI가 향상되지만, 획득은 최대 0.012만큼임.
- PNMI 점수는 HuBERT 특징에서 클러스터링할 때 MFCC 특징에서 클러스터링하는 것보다 훨씬 높으며, 500 클러스터에서 더 큰 차이를 보임.
6. Conclusion
- HuBERT는 연속 입력의 마스크된 세그먼트의 K-means 클러스터 할당을 예측하는 음성 표현 학습 방법을 제시
- Librispeech 960시간과 60,000시간 Libri-light pre-training 설정에서 모든 10분, 1시간, 10시간, 100시간, 그리고 960시간의 fine-tuning 서브셋에 걸쳐 최첨단 시스템과 동일하거나 이를 초과함.
- 이전 반복에 대해 학습된 잠재 표현을 사용하여 K-means 클러스터 할당을 반복적으로 개선함으로써 표현의 품질이 크게 향상
- uBERT는 최대 13%의 WER 감소를 보이는 1B 트랜스포머 모델로 잘 확장됨.
- 미래 연구 방향은 다음과 같음.
-> 단일 단계로 구성되는 HuBERT 훈련 절차를 개선하려는 계획임. 또한 그 표현의 높은 품질을 고려하여 ASR 이외의 다양한 하류 인식 및 생성 작업에 HuBERT 사전 훈련 표현을 사용할 계획임.
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
- 저자는 연속적인 음성 입력의 마스크된 segment의 K-means 클러스터 할당을 예측하는 새로운 음성 표현 학습 방법인 HuBERT를 제안하고자 함.
- 주요 목표는 최신의 다른 자기 감독 학습 방법과 비교하여 HuBERT의 성능을 입증하는 것
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
- HuBERT의 핵심적인 요소는 K-means 클러스터링을 사용하여 마스크된 음성 세그먼트에 대한 클러스터 할당을 예측하는 것
- 이 방법은 연속된 음성 입력의 특성과 그 안에 포함된 다양한 음성 단위를 고려하여 설계.
- 또한, HuBERT는 반복적인 정제 과정을 통해 K-means 클러스터 할당을 개선하며, 이 과정은 모델의 잠재 표현을 사용함.
- 어느 프로젝트에 적용할 수 있는가?
- HuBERT는 음성 인식(Speech Recognition)에 직접 적용될 수 있는데, 특히 라벨이 없거나 제한된 양의 데이터로 음성 모델을 훈련하려는 프로젝트에 적합함.
- 또한, 다양한 음성 기반의 하위 작업, 예를 들면, 스피커 인식, 감정 인식 등에 적용될 수 있는 특징 추출기로 사용될 수 있음.
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- wav2vec 2.0
- DeCoAR 2.0
- DiscreteBERT
- 느낀점은?
- corpur는 무엇을 썼는지?
- 미리 학습을 위해 LibriSpeech의 전체 960시간 오디오와 Libri-light의 60,000시간 오디오를 사용함.
- 두 데이터 세트 모두 LibriVox 프로젝트에서 파생되었으며, 이 프로젝트는 인터넷의 자원 봉사자들에 의해 저작권이 만료된 오디오북의 영어 녹음을 포함함.
- 특화 도메인은?
- 음성 인식
- 사용된 데이터는 주로 영어 오디오북 녹음으로, 특정한 업계나 전문 분야보다는 일반적인 음성 데이터를 대상으로 함.
- 임베딩 방식은?
- HuBERT의 핵심 아이디어는 K-means 클러스터링을 사용하여 발견된 음성 단위의 마스크된 세그먼트를 예측하는 것.
- 논문에서 제안한 방법은 음성 데이터의 연속적인 세그먼트를 마스킹하고, 이 마스크된 세그먼트의 K-means 클러스터 할당을 예측하는 것을 중점으로 함.
- 또한, 반복적인 정제 과정을 통해 K-means 클러스터 할당을 개선.
-> 이 정제는 이전 반복의 모델에서 학습된 잠재 표현을 사용하여 이루어짐.
📚 References
논문

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊