[논문리뷰 | CV] Learning Character-Agnostic Motion for Motion Retargeting in 2D (2019) Summary
[논문리뷰]

Title
- Learning Character-Agnostic Motion for Motion Retargeting in 2D

Abstract
- 이 연구는 인간의 움직임을 분석하는 것이 컴퓨터 비전 & 그래픽스에서 다양한 응용분야를 가진 어려운 작업임을 주장함.
- 컴퓨터 애니메이션에서 중요한 것 중 하나는 한 수행자에서 다른 수행자로의 retargeting of motion임.
- 사람들이 3차원에서 움직이지만 대부분의 인간 움직임은 비디오를 사용하여 캡처되며, 기존의 재타켓팅 방법을 적용하기 전에 2D에서 3D 포즈 & 카메라 복구가 필요함.
- 본 논문에서는 3D 포즈 & 카메라 매개 변수를 재구성할 필요 없이 다른 인간 수행자 간에 비디오로 캡처된 움직임을 재타켓팅하는 새로운 방법을 제시함.
-
핵심 아이디어는 심층 신경망을 훈련 시켜 2D 포즈의 시간적 sequence를 세 가지 요소로 분해하는 것임.
(1) 움직임
(2) 골격
(3) 카메라 뷰 각도
-> 이러한 표현을 추출한 후 움직임을 새로운 골격 및 카메라 뷰와 재결합하고, 합성 데이터 세트에서의 기준과 비교하여 재타켓팅된 시간적 sequence를 디코딩할 수 있음. -
이 연구의 프레임워크는 3D 재구성을 우회하여 인간의 움직임을 robustly하게 추출하는 데 사용될 수 있고, 야생에서의 비디오에 적용될 때 기존의 재타켓팅 방법을 능가함.
- 성능 복제, 비디오 주도 만화 및 움직임 검색과 같은 추가 응용 프로그램도 가능함.
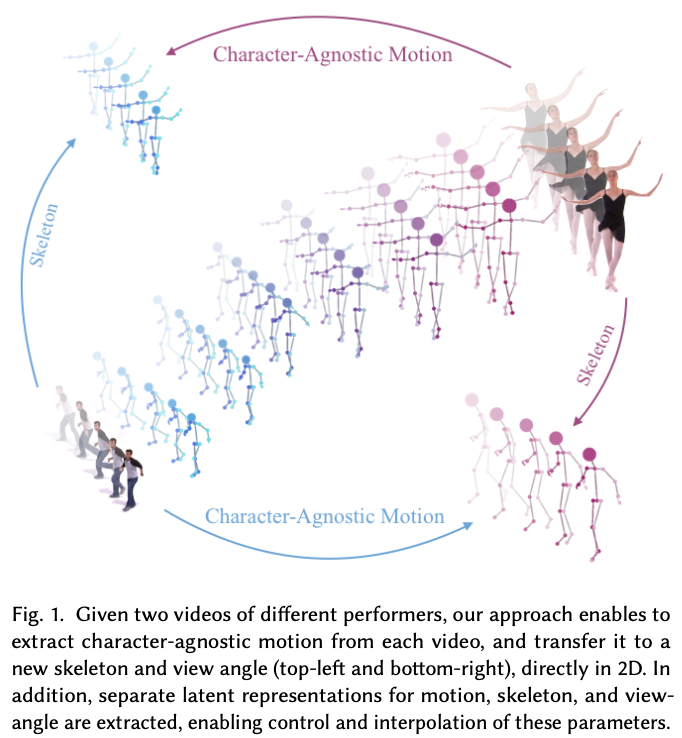
- 위의 그림처럼 서로 다른 두 수행자의 비디오에서 캐릭터에 구애받지 않는 움직임을 추출하고, 이를 새로운 골격과 시야 각도로 직접 2D에서 전송할 수 있음.
- 움직임, 골격, 카메라 각도에 대한 별도의 잠재 표현이 추출되어 매개변수의 제어와 보간이 가능함.
1. Introduction
- 모션의 이해와 합성은 컴퓨터 애니메이션에서 중요한 연구 주제였음.
- 인간의 움직임은 4D entity로, 관절의 위치 or 각도와 같은 포즈의 시간 순서로 표현되고 이러한 표현은 골격과 그 기하학적 특성에 크게 의존함.
-> 따라서 서로 다른 골격을 가진 두 사람이 동일한 움직임을 수행하면 그 표현은 크게 달라짐.
- 주요 아이디어는 깊은 신경망을 훈련시켜 retargeting of 2D motion을 수행하여, 이 과정에서 세 개의 잠재 구성 요소를 추출하는 것임.
(1) 골격과 시야에 독립적인 움직임의 인코딩
(2) 수행자의 골격을 인코딩하는 정적 구성 요소
(3) 시야 각도를 인코딩하는 구성 요소
-> 이러한 잠재 구성 요소는 새로운 움직임을 생성하게 위해 재결합되고, 손실이 계산되며 최적화됨.
- 아키텍처는 2D 관절 위치의 입력 sequence를 분해하는 세 개의 Encoder와 그러한 구성 요소로부터 sequence를 재구성하는 Decoder로 구성됨.
- 네트워크는 3D 데이터의 2D 투영을 이러한 세 가지 속성으로 분해하도록 훈련되며, 이는 새로운 조합을 형성하기 위해 섞이고 재구성됨.
- 결론적으로, 이 연구는 특정 부분 작업에 대해 전체 3D 재구성을 엄격하게 요구하지 않는 깊은 네트워크가 더 나은 해결책이 될 수 있음을 보여줌.
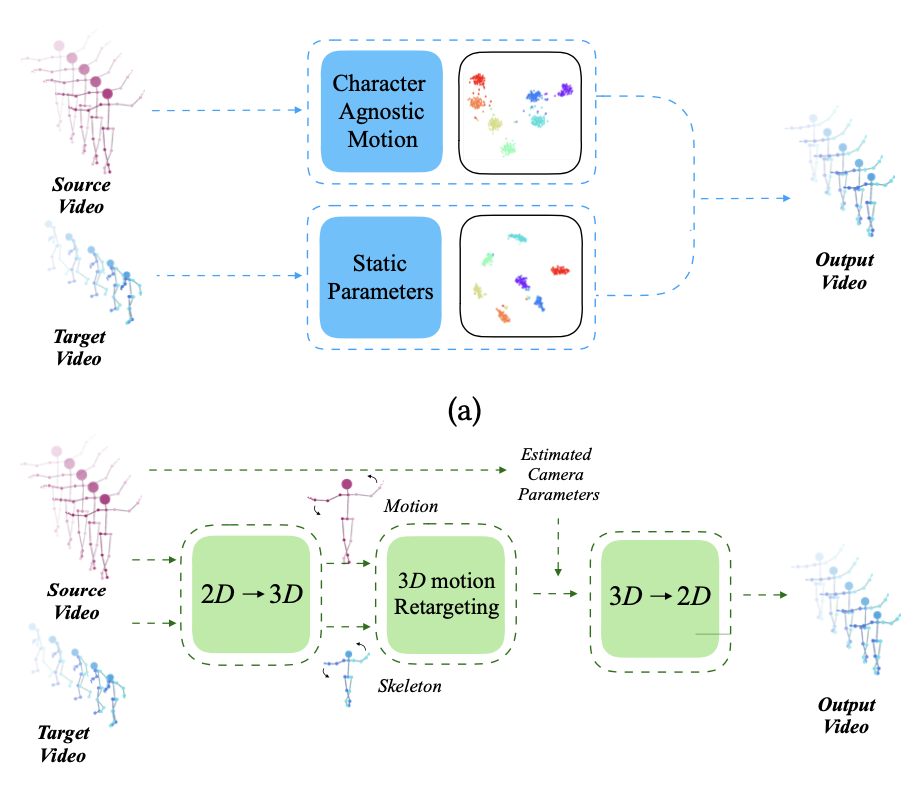
- 네트워크는 정적 잠재 구성요소(Character-agnostic motion)와 함께 동적인 캐릭터-중립적인 잠재 모션 표현(Static Parameters)을 학습함.
- 모호한 2D에서 3D 포즈 & 카메라 파라미터 추정의 필요성을 우회하면서 2D 영역에서 직접 모션 재타켓팅이 가능해짐.
2. Related Work
2.1. Motion Representation
- Müller는 일관된 모션 클래스를 표현하는 방법을 제안
- Bernard는 모션을 계층적 구조로 표시하는 Motion-Explorer를 개발함.
- Wu와 Hu는 계층적 신체 부위에서의 모션 클러스터링에 중점을 둠.
- Chen은 데이터 추상화를 위해 HAP 기술을 도입했고, Aristidou는 3D 데이터의 모션을 잠재 공간에 매핑하였음.
- Tulyakov는 GAN을 사용하여 모션과 콘텐츠를 제어하는 방법을 탐구
- Holden은 모션의 3D 표현을 학습하기 위해 자동 인코더를 사용함.
- 이 연구들은 모션 데이터의 복잡성과 다양성을 표현하고 분석하는 새로운 방법들을 제시하였음.
2.2. Motion Retargeting
- 시스템은 사람들의 비디오에서 모션을 추출하여 지도 학습 2D retargeting of motion을 수행함.
- 기존의 대부분의 모션 리타게팅 방법은 3D에서 작동하는 반면, 몇 가지 중요한 3D 기반 방법론이 있었음.
- 우리의 접근법은 깊은 네트워크의 능력을 활용하여 2D 입력과 출력 사이의 매핑을 학습하며, 2D 데이터에서 3D 인간 포즈와 카메라 포즈 복구의 필요성을 우회함.
- Peng 등은 비디오에서 물리적으로 시뮬레이트된 캐릭터가 스킬을 학습할 수 있는 방법을 제안했으며, 그들의 결과는 3D 포즈 추정의 정확도에 크게 의존
3. Motion Learning Framework
- 이 연구는 2D 관절 위치를 분해하고 재구성하는 신경망을 사용함.
- 이 네트워크는 세가지 특징 공간으로 입력을 인코딩하는데, 이에는
동적 모션,골격 정보,시점 정보가 포함됨.
모션은시간에 따라 달라지며, 나머지 두 특징은 고정된 잠재 공간에 있음.
- 학습은 합성 데이터셋을 사용하며, 실제 움직임의 기준 정보 없이 진행됨.
- 네트워크는 제공된 모션 샘플을 분해하고 섞은 다음 재구성하여, 각 컴포넌트가 의도된 정보를 올바르게 인코딩하도록 함.
3.1. Network Architecture
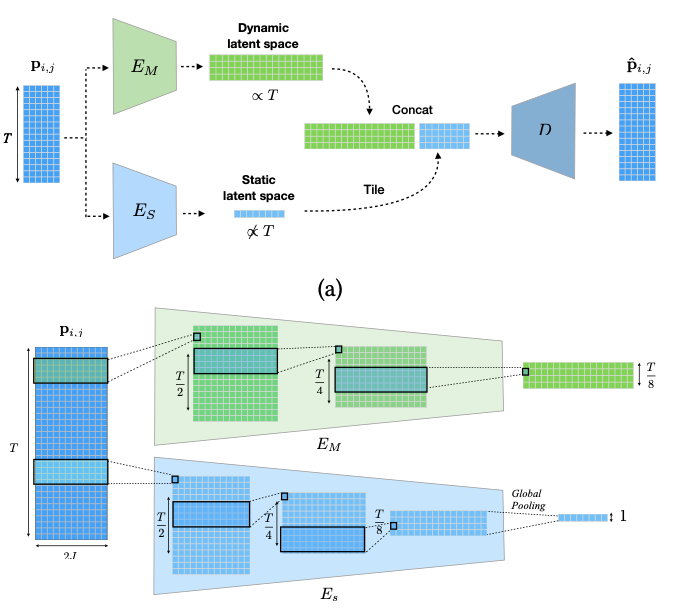
- 이 프레임워크는 두 개의 Encoder,
EM과ES를 사용하여동적(시간에 따라 변하는) 특징과정적(시간에 독립적인) 특징을 별도의 잠재 공간으로 인코딩함.
- sequence를 Decoder D로 디코딩하기 위해, 정적 잠재 특징은 시간 축을 따라 타일링되고, 채널 축을 따라 모션 잠재 특징과 연결됨.
EM은 시간 차원에서stride 2를 가진 1차원 합성곱 레이어를 사용하여 입력 샘플의 지속 시간에 따라 크기가 변하는 잠재 모션을 생성하고,ES에서는 시간 축을 따라global pooling layer를 사용하여 그것을 축소하여 고정 크기의 잠재 벡터를 생성함.
- 네트워크 구조는 두 가지 주요 특성인
동적및정적을 추출하기 위해 두 개의 Encoder를 사용함.
- 시점과 골격을 하나의 정적 속성으로 간주함.
-
각 데이터 샘플은 두 개의 Encoder, EM 및 ES,를 통해 병렬로 인코딩되며, 그 결과는 Decoder D로 전달됨.
-
EM Encoder는 시간 정보를 보존하도록 설계되어 입력 샘플의 지속 시간에 따라 크기가 달라지는 잠재 모션을 생성함.
- 반면
ES Encoder는 시간 축을 축소하여 입력 시퀀스 길이와 무관한 고정 크기의 잠재 벡터를 생성함.
-> 두 잠재 특성은 Decoder D로 전달되기 전에 결합됨.
3.2. Decomposition and Re-composition
- 네트워크의 구조는 지속 시간에 따라 달라지는 동적 특징과 정적 특징을 명확하게 분리하지만, 이 자체로는 동적 특징이 골격/시점에 무관한 움직임을 반드시 인코딩한다는 것을 보장할 수 없음.
-> 동적-정적 분해가 있을 수 있기 때문
- 네트워크가 원하는 분해를 수행하도록 강제하기 위해, 이 연구는 다양한 캐릭터에 적용되고 다른 시점으로 투영될 때 유사한 움직임이 어떻게 보이는지 보여주는 합성 데이터로 네트워크를 교육함.
핵심 아이디어는 여러 종류의 잠재 움직임과 정적 파라미터 조합을 사용하여 해당 지상 진실 샘플을 재구성할 수 있어야 한다는 것

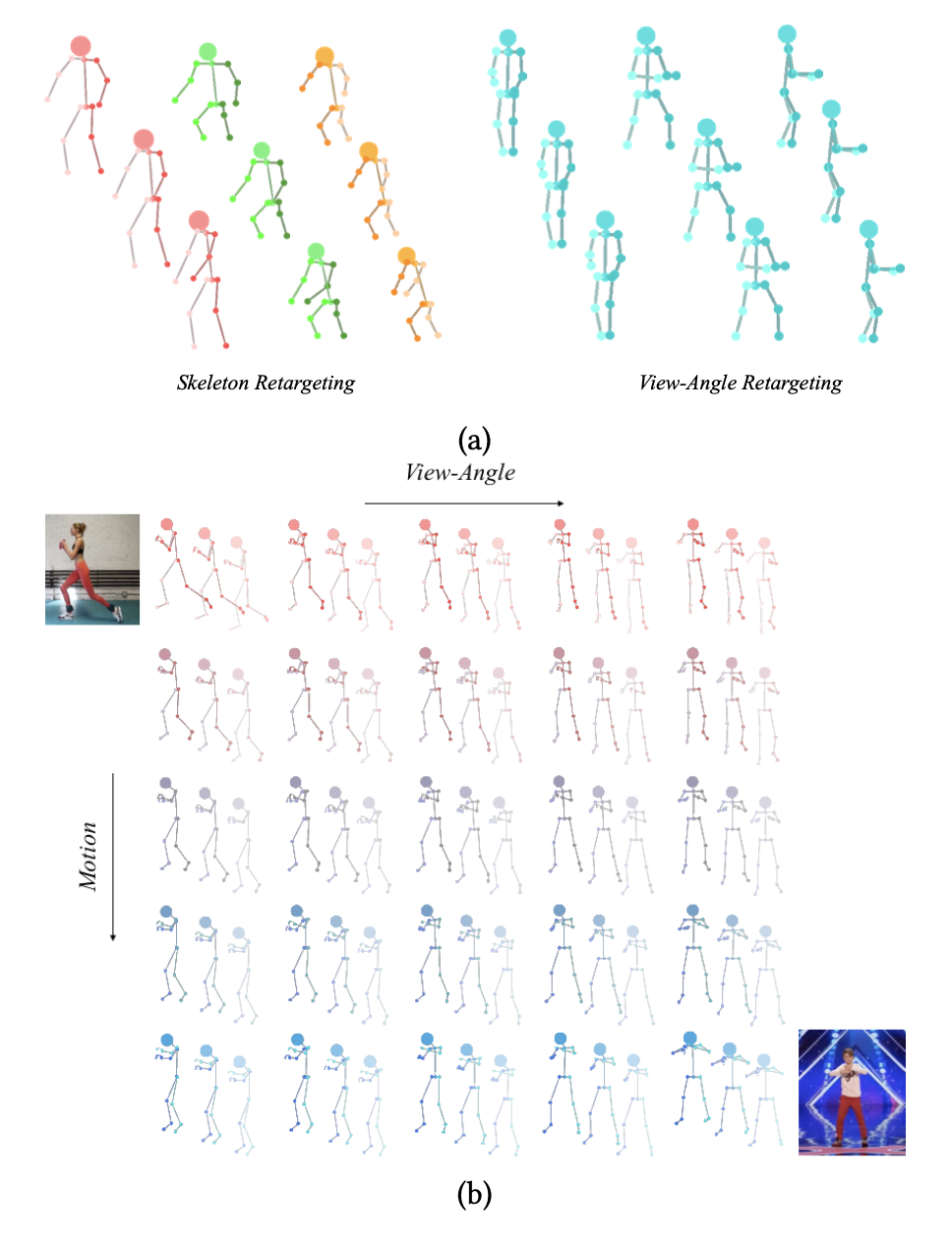
- 세 개의 별도의 잠재 공간으로 모션을 분해하여 리타겟팅과 보간을 수행하는 방법을 보여줌.
(a) 다양한 골격 및 다른 시점으로의 모션 리타겟팅,
(b) 시점과 모션 간의 보간 표현.
- 다른 골격 or 다른 시점으로 모션을 재타켓팅하거나 골격, 시점 및 모션을 지속적으로 보간하는 것과 같은 조작이 가능해짐.
3.3. Training and Loss
- 세 가지 구성요소로 구성된 손실함수를 사용함
(1) cross reconstruction loss
(2) triplet loss
(3) foot velocity loss
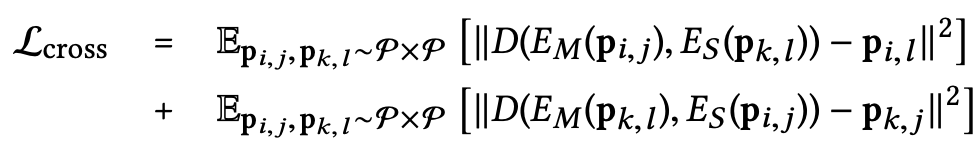
- 위에는
cross reconstruction loss임.
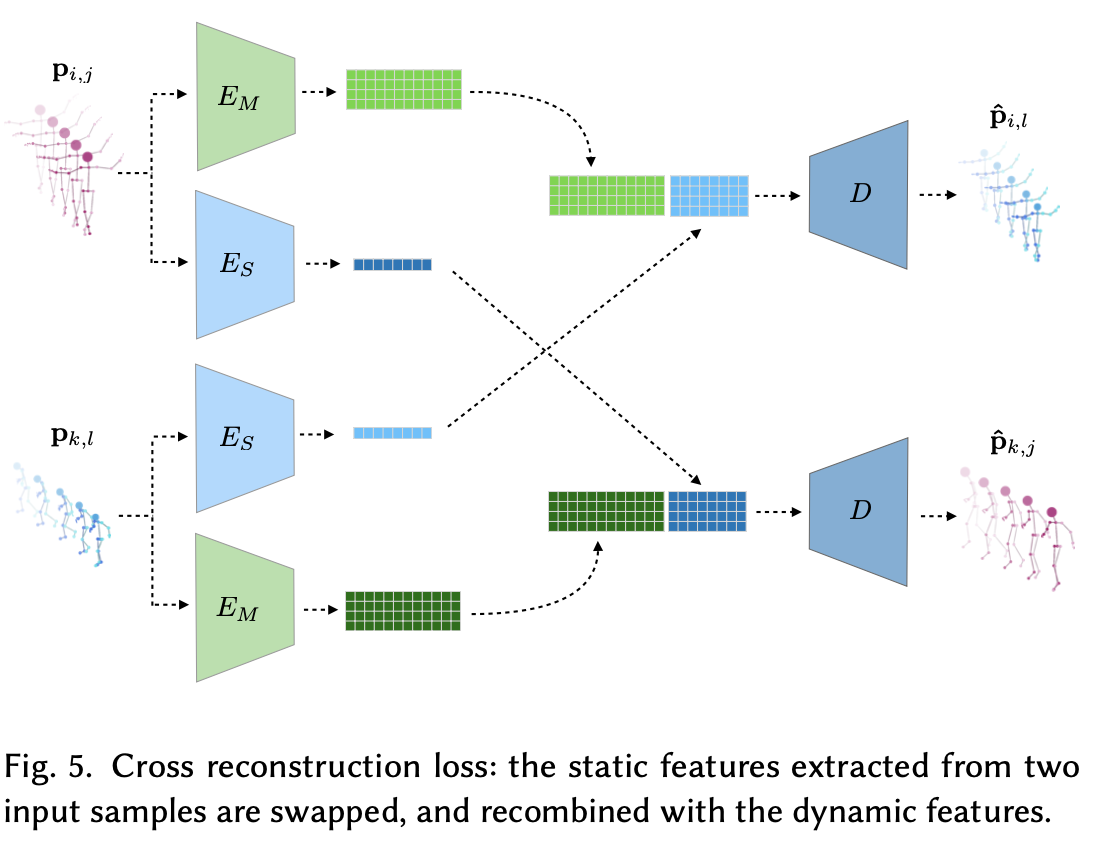
- 네트워크를 다양한 쌍의 교차 구성을 재구성하도록 교육함.
- 각 반복에서 훈련 데이터셋 P에서 무작위로 두 샘플을 추출하고, Encoder로 그것들을 분해하고 Decoder를 사용하여 새로운 조합을 재구성함.
- 각 epoch에서 추출된 쌍의 수는 훈련 데이터의 샘플 수와 동일함.
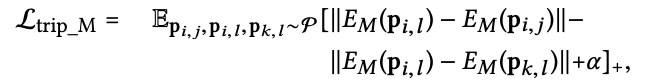
- 위에는
triplet loss임.
- 유사한 움직임을 가진 sample을 동일한 영역에 mapping하고, 움직임 잠재 공간에 직접 triplet loss을 적용함.
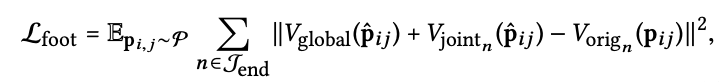
- 위에는
foot velocity loss임.
- 만약에 reconstruction loss만을 사용하면, 실험에서는 손과 발에서 더 큰 오차가 나타나며, 이는 잘 알려진 foot skating phenomenon을 초래함.
-> 이유는 네트워크가 원래의 포즈를 재구성하기 위해 훈련되었더라도, 몸의 나머지 부분에 더 큰 영향을 미치는 중요한 중앙 관절 위치에 노력을 기울이려고 할 것이기 때문임.
- foot sliding artifacts를 수정하거나 캐릭터의 손을 물체를 잡도록 안내하는 데 필수적인 끝 효과기의 전역 위치를 명시적으로 제약해야함.
3.4. Motion Datset

- 데이터셋은 Mixamo (Adobe Systems)의 3D 애니메이션 컬렉션을 사용하여 2D Motion으로 구축함.
- 이 컬렉션에는 약 2,400개의 고유한 motion sequence가 포함되어있고, 기본 행동(점프, 킥, 걷기 등)과 다양한 댄스 동작(삼바, 힙합 등)이 포함되어 있음.
- 이러한 움직임은 71개의 고유한 캐릭터에 적용될 수 있고, 인간의 골격 토폴로지는 공유하지만, 몸의 모양과 비율에서 차이가 있을 수 있음.
-> 이 움직임은 AutoDesk의 3D retargeting of motion 알고리즘인 Human-IK(Montgomery 2012)를 사용하여 다양한 캐릭터에 자동으로 적용됨.
- 3D 관절 위치를 다양한 카메라 시점으로 투영하여 데이터 샘플을 생성함.
-> 결과적으로 500,000개 이상의 샘플로 구성된 풍부한 라벨링된 데이터셋을 얻게 되며, 이는 다양한 캐릭터의 골격이 어떻게 다른 시점에서 나타나는지를 보여줌.
- 데이터 전처리를 위해, 모든 프레임에서 모든 관절 위치에서 루트 위치를 전역적으로 빼고, 지역적으로(관절 별) 평균 관절 위치를 빼고 표준 편차로 나눔.
-> 이 연산은 가역적이므로 원래의 sequence는 복구 후에 복원될 수 있음.
3.5. Implementation Details
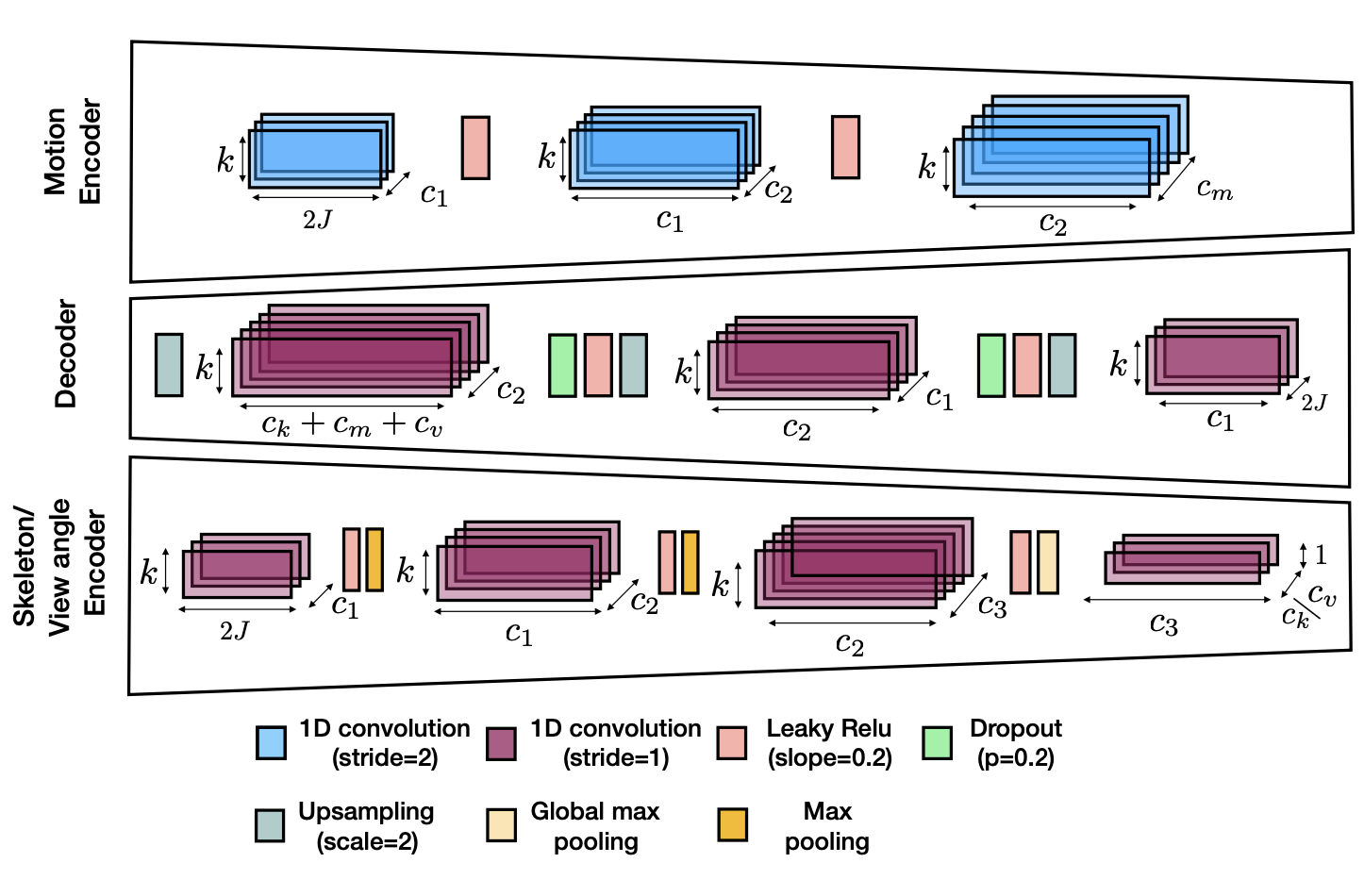
- 구현은 3개의 Encoder(모션, 골격, 시점)와 하나의 Decoder로 구성되며, 2개의 정적 Encoder(골격, 시점)는 동일한 구조를 공유함.
- Encoder의 합성곱 Layer는 stride=2를 사용하여 시간 축을 downsampling함.
- Decoder에서는 stride=1의 합성곱 다음에 최근접 이웃 upsampling을 사용하여 시간 정보를 복원함.
🤜 대칭적 구현이 복구에서 작은 시간적 지터링을 초래한다는 것을 발견함.
- 기울기가 0.2인 Leaky ReLU, 과적합을 억제하기 위한 Dropout Layer(0.2) 및 고정 크기의 시간 독립적인 잠재 벡터의 채널 수를 더 줄이기 위한 Kernel=1의 합성곱을 사용함.
- 신경망의 가중치를 최적화하기 위해, AmsGrad 알고리즘(Adam 적응형 경사 하강 알고리즘의 변형)을 사용함.
4. Supporting videos in the wild
- 이 네트워크는 깨끗한 합성 데이터에서 훈련되었기 때문에 테스트 시 실제 비디오에 모델을 강건하게 만들기 위한 훈련 향상 방법을 설명함.
- 이는 data augmentation, artificial noise,data from real videos 등이 있음.
(1) data augmentation
1.1. Temporal Clipping
: motion 클립의 길이가 고정되어 있을 필요는 없지만, 훈련 중 고정된 창 크기를 가지면 batch를 사용할 수 있어 속도 향상됨.
1.2. Scaling
: 다양한 스케일을 사용하여 카메라 간의 거리 차이를 모델링함.
1.3. Flipping
: 좌우를 뒤집어 확장된 골격을 얻음.
(2) artificial noise
- 2D 포즈 추정 알고리즘이 실제 비디오에 적용될 때 잡음과 누락된 관절을 포함할 수 있기 때문에 input에 artificial noise를 추가하고 관절을 무작위로 설정하여 좌표를 zero로 만듬.
(3) from real videos
- 훈련 중, 네트워크에 실제 비디오에서 추출된 몇 가지 동작을 제공하는 것이 도움이 되었음.
- UCF101 데이터셋과 Penn Action 데이터셋의 샘플을 추가로 사용함.
- Cao 등의 방법으로 2D 포즈를 추출함.
-> 이 시퀀스는 시간 창으로 분할되고 동일한 방식으로 전처리 및 확대되어 네트워크에 추가적인 2000개의 입력 샘플로 사용됨.
- 실제 비디오에 대한 라벨이 없기 때문에 이러한 입력에는 표준 reconstruction loss만 적용됨.
5. Results and Evaluation
- pytorch로 구현하였고, Intel Core i7-6950X/3.0GHz CPU (16 GB RAM) 및 NVIDIA GeForce GTX Titan Xp GPU (12 GB)가 장착된 PC에서 다양한 실험을 수행함.
- 네트워크 학습은 약 4시간 소요됨.
- 데이터셋은 학습과 검증 두 부분으로 나누어졌으며, 각 캐릭터와 모션은 이 두 부분 중 하나에 할당 됨.
5.1. Ablation study

- cross reconstruction loss의 성능을 조사하기 위해 먼저 이 손실만 사용하여 네트워크를 훈련시킴.
- 위의 그림(왼쪽)은 학습(파란색), 검증(주황색) 데이터에 적용된 손실 곡선을 epoch 수에 따라 나타남.
-> 네트워크가 잘 일반화되며 학습 데이터에 과적합되지 않음을 보여줌.
- 위의 그림(오른쪽)은 3개의 잠재 공간 각각에 대한 에폭 수의 함수로서의 평균 실루엣 계수가 나타남.
-> 계수가 증가하고 있음을 볼 수 있고, 네트워크가 명시적으로 요구되지 않음에도 불구하고 라벨이 지정된 그룹을 군집화하도록 암시적으로 학습한다는 것을 나타냄.

- 속성 간의 분리를 강제하기 위해 triplet loss을 사용함.
- 위의 그림은 모션과 시야 각도의 군집에 대한 기여를 보여줌.
-> 군집이 더 타이트해짐을 볼 수 있음.

- 위의 표는 검증 세트의 쌍 사이의 대상 출력과 기준의 평균 제곱 오차 (MSE)를 보고함.
- 결과는 세 가지 속성의 분리를 강화하는 triplet loss의 포함이 retargeting 성능을 개선한다는 것을 보여줌.
- 반면에 일반적인 재구성 손실만 사용하여 triplet loss(rec+trip)을 사용하여 재눙 성능이 크게 저하되며 retargeting 작업을 제대로 수행할 수 없음.

- 결과적으로
cross reconstruction loss는 각 잠재 공간에서 데이터를 효율적으로 군집화하도록 네트워크를 암시적으로 훈련시키는 가장 중요한 항목임.
triplet loss는 군집의 타이트함을 더욱 강화하고 잠재 특징의 더 나은 분리를 강제하여 retargeting 성능을 더욱 개선함.
5.2. Comparison
- 다른 motion retargeting 알고리즘과 비교하여 이 연구의 방법을 평가하는 두 가지 실험을 진행
-
지상 진실 3D 포즈가 사용 가능한 상황에서 여러 방법을 비교함.
-
retargeting되는 motion을 비디오로 캡처하여 정확한 3D 포즈의 이점이 없는 더 현실적인 시나리오에서 방법을 비교함.


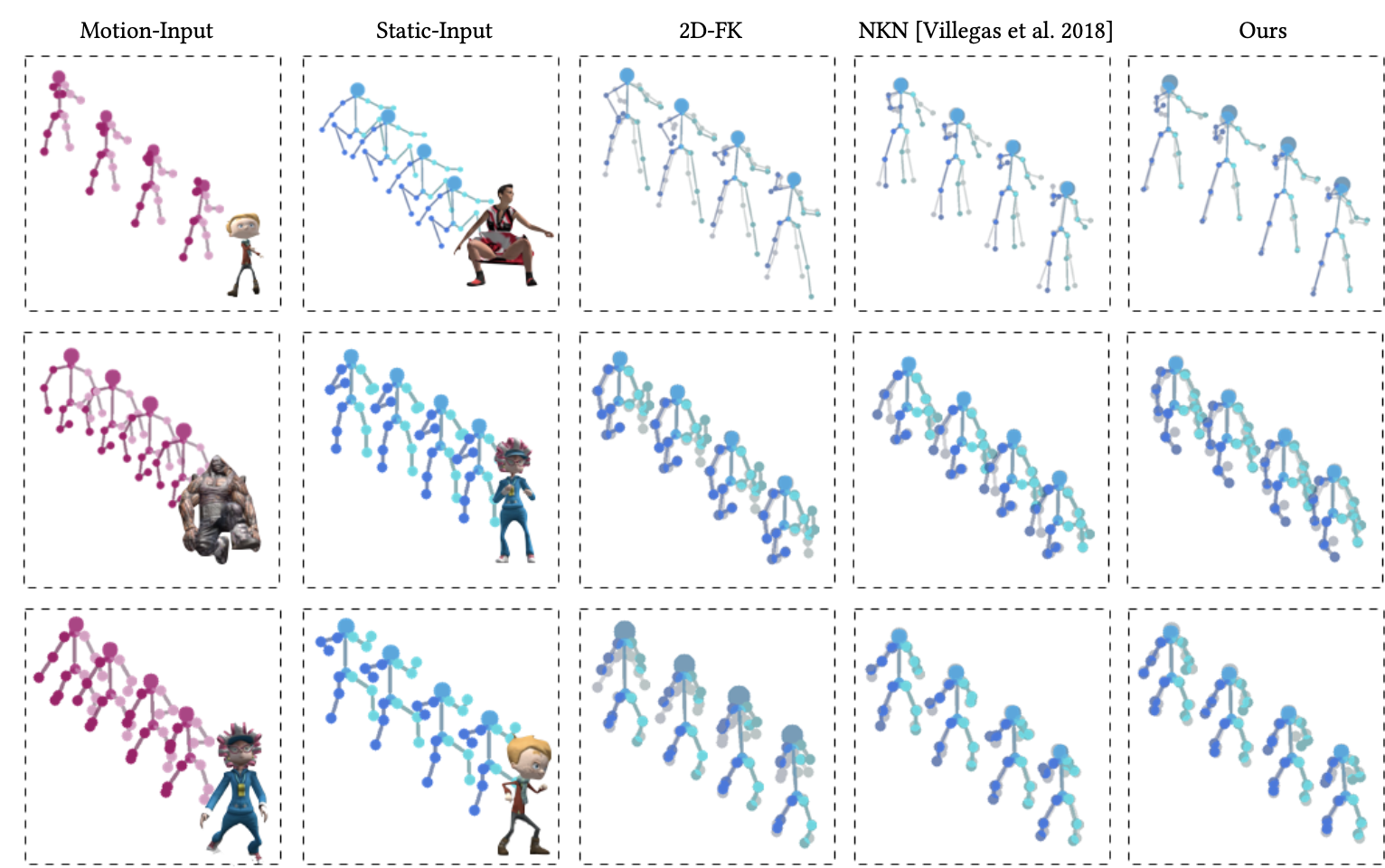
- 위의 그림은 다른 리타겟팅 방법과의 비교를 보임.
-> 주어진 모션 입력 시퀀스(첫 번째 열)와 정적 파라미터가 추출된 시퀀스(두 번째 열)에 대하여 세 가지 리타겟팅 접근법의 결과가 오른쪽 열에 표시함.
- 2D Forward Kinematics (2D-FK, 3번째 열),
- Neural Kinematic Networks (NKN,4번째 열)
- 이 연구의 방법 (가장 오른쪽 열)
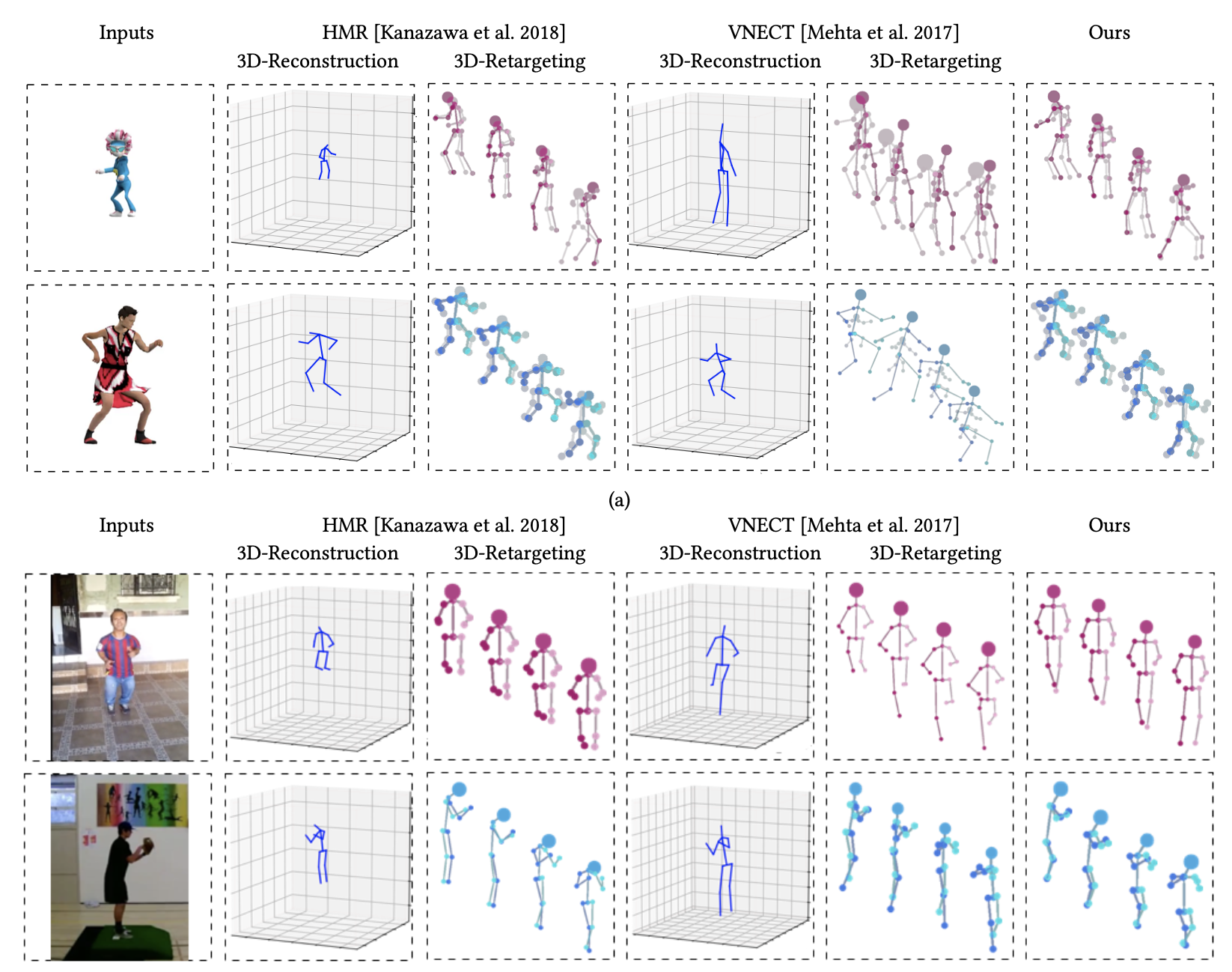
- 위의 그림은 비디오로 캡처된 모션의 리타켓팅을 실험한 그림임.
- 실험은 Mixamo에서 가져온 가상 비디오와, 실제 환경에서 촬영된 Youtube & UCF 101 dataset의 비디오를 사용함.
- 3D 자세 추정을 위해
VNECT,HMR을 사용함.
VNECT는 일부 비디오에서 시간적으로 불일치하는 관절 위치를 보여주며, 이는 자연스럽지 않은 모션을 초래함.
또한, 카메라와 골격 사이의 모호성으로 인해 스케일이 잘못되어 리타켓팅에 문제가 발생할 수 있음.
HMR의 경우, 2D 투영은 올바르지만, 일부 캐릭터의 3D 관절 위치가 잘못되어 있고, 이는 불자연스러운 결과를 초래함.
- 우리의 연구에서는 이러한 문제를 모두 해결하며, Mixamo 비디오에 대해 더 낮은 오류값을 달성함.
6. Applications
- 비디오에서 직접 인간의 움직임을 추출하고 retargeting하는 능력은 다양한 응용 프로그램의 길을 열어줌.
6.1. Performance Cloning
- 2D에서 움직임 리타겟팅을 수행하는 능력을 통해 다양한 비율을 가진 새로운 2D 골격을 사용하여 비디오로 캡처된 퍼포먼스를 구동할 수 있음.
- 최근에는 몇 가지 Performance Cloning 기술이 제안되었는데, 이 기술들은 주연 배우의 움직임을 재연하는 대상 배우의 모습을 포함하는 프레임을 생성하기 위해 깊은 생성 네트워크를 사용함.

- 위의 그림은 Chan 등의 방법 [2018]을 사용하여 참조 비디오의 배우의 프레임을 재생성하는 네트워크를 훈련시킴 (왼쪽)
- 간단한 전역 스케일링은 잘못된 비율과 아티팩트를 초래함 (Global Scaling)
- 우리의 retargeting 방법을 사용하여 생성된 결과는 올바른 몸 비율과 원래의 방향을 가지며 (오른쪽), 타당한 결과를 제공함.
6.2. Motion Retrieval
- 우리의 움직임 표현을 사용하면, 개인의 몸매나 카메라 시점에 관계없이 주어진 비디오의 움직임과 유사한 움직임을 와일드 비디오 데이터셋에서 검색할 수 있음.
- 우리의 잠재 움직임 표현은 시간적 정보를 보존하는 시간 축을 포함하고 있어, 검색된 비디오는 다른 시간 길이를 가질 수 있으며 결과는 검색된 sequence 내에서 Query 움직임을 지역화 가능함.
- 비디오 데이터셋에서 Query 움직임과 유사한 움직임을 효과적으로 검색할 수 있는 움직임 검색 엔진을 시연함.
- 비디오를 데이터셋에 추가할 때, 시스템은 그것을 2D 포즈 추정 구성 요소를 통해 전달하고, 훈련된 움직임 인코더를 통한 전방 통과를 사용하여 그것의 잠재 움직임 표현을 추출함.
-> 그 결과로 나온 잠재 움직임 표현들은 시간 축을 따라 연결되고, 이 형태로 데이터셋에 저장됨.
- Query 움직임을 포함하는 비디오가 주어지면, 위와 같이 움직임 표현을 추출하고, 데이터셋 내의 움직임의 연결과의 초대 교차 상관 관계를 검색함.
- 최상의 일치가 발견되면 해당 비디오 조각이 자르고 반환됨.
-> 검색은 잠재 표현에서 수행되므로, 검색 엔진은 검색된 움직임을 시간적 정확도까지 지역화 가능.

- UFC101 dataset & Penn Action dataset의 와일드 비디오 세트에서 검색을 수행함.
-> Query 움직임을 이 dataset에서 추출되었으며, dataset에 반드시 포함되지 않은 다양한 동작을 보여줌.
- 위의 그림은 짧은 Query sequence(왼쪽 열)와 검색된 상위 네 개의 결과를 보여줌.
- 검색된 결과는 다양한 체형과 시점을 보여줌.
- 게다가 Query가 dataset에 포함되지 않은 움직임을 보여줄 때도 검색된 움직임은 유사한 팔 제스처를 보여줌.
7. Discussion and Future work
- 2D에서 직접 움직임을 retargeting하는 방법을 제시함.
- 이 기술은 3D로의 복잡한 전환을 피하며, 딥러닝 네트워크를 사용해 움직임, 골격, 카메라 뷰 각도를 분리함.
- 현재의 방법은 정적 카메라에서만 작동하지만, 미래에는 더 다양한 카메라 움직임을 고려하고자 함.
- 이 기술을 활용하여 비디오에서 3D 포즈 재구성을 돕는 방법도 탐구하고자 함.
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
- 저자는 비디오에서 포착된 움직임을 분석하는 기술을 제시하고자 함.
- 이를 통해 3D 데이터로 전환하는 복잡한 문제를 피하면서 2D 프로젝션의 스켈레톤에 직접 움직임을 retargeting하려고 함.
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
- 핵심은 딥러닝 네트워크를 활용하여 관측된 움직임을 동적 요소와 정적 요소로 분리하는 방식임.
동적 요소는 실제 움직임을,정적 요소는 스켈레톤 구조와 카메라의 시점을 나타냄.
- 어느 프로젝트에 적용할 수 있는가?
- 비디오 캡처된 움직임의 retargeting
- 모션 검색 엔진 구현
- 모션 기반의 콘텐츠 생성 (3D 포즈 재구성 개선)
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- Chan et al. [2018]의 작업
- Aberman et al. [2018]의 연구
- Liu et al. [2018]의 방법론
- VNECT [Mehta et al. 2017]
- HMR [Kanazawa et al. 2018]
- 느낀점은?
- Mixamo라는 데이터셋을 활용한 점이 매우 독특하다고 느낌.
- 손실함수가 3가지 구성요소로 되어 있어서 복잡했음.
- 움직임, 골격, 카메라 뷰 각도를 분리하는 점이 아이디어 굳이었음.
📚 References
논문
