[논문리뷰 | Speech] Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers (VALL-E) (2023) Summary
[논문리뷰]
Title
- Neural Codec Language Models are
Zero-Shot Text to Speech Synthesizers

shyu0522님의 블로그를 참고하면서 논문 리뷰하였습니다.
0. 논문 읽기 전에 알면 좋을 것들
Zero-Shot
- 기계 학습 및 인공 지능 분야에서 사용되는 용어로, 모델이 학습 중에 본 적 없는 데이터나 클래스에 대해 예측하거나 작동할 수 있는 능력을 설명할 때 사용됨.
- 즉 "zero-shot"은 학습 예시를 보지 않고도 작업을 수행할 수 있는 능력을 의미함.
- zero-shot 학습은 주로 자원이 제한된 상황이나 빠르게 변화하는 데이터 환경에서 유용하게 사용됨.
- 음성(Speech) 분야에서의 "zero-shot"은 주로 모델이 학습 데이터에서 경험하지 못한 언어, 방언, 발음, 또는 환경 조건에서도 음성 인식이나 다른 음성 관련 작업을 수행할 수 있는 능력을 의미함.
Abstract
- 현대 TTS (text to speech) 기술은 주로 mel spectrogram이라는 중간 단계를 포함한 음향 모델과 vocoder를 기반으로 하는 구조를 사용함.
-
첨단 TTS 기술은 단일 또는 다수의 스피커의 음성을 고화질로 변환할 수 있으나, 이를 위해선 스튜디오 수준의 녹음 데이터가 필수적이였음.
-> 하지만 웹에서 수집된 대량의 데이터는 이 요구를 만족시키지 못하며, 대체로 성능 저하를 가져왔음
-> 학습용 데이터셋이 제한적이므로, 현 TTS 기술의 범용성은 아직 미흡함.
-> Zero-shot 상황에서 새로운 스피커에 대한 음성 품질과 자연스러움이 크게 저하됨. -
이를 해결하기 위해 텍스트 음성 합성(TTS)을 위한 언어 모델링 방법을 제시함.
🤜 VALL-E라는 신경 코덱 언어 모델을 훈련시키며, 기존 연속 신호 회귀 방식이 아닌 조건부 언어 모델링 작업으로 TTS를 취급한다.
🤜 TTS 음성합성을 Language Modeling 접근으로 달성했음을 강조함. -
이 문제를 극복하기 위한 해결책으로, 텍스트 합성 영역에서의 성과를 참고하여, 풍부하고 다양한 데이터로 모델을 교육하는 방법을 제안함.
🤜 학습 데이터는 기존 시스템보다 수백 배 큰 60K 시간의 영어 음성으로 확장됨.
-
이 연구에서는 이러한 성공 경험을 음성 합성 분야에 적용하고자 하며, 다양한 스피커 데이터를 활용하는 새로운 언어 모델 기반 TTS 시스템인, VALL-E를 제시함.
-
VALL-E는 문맥 학습 능력을 보여주며, 보이지 않는 스피커의 3초 녹음만으로 고품질의 개인화된 음성을 합성할 수 있음.
🤜 실험 결과, VALL-E는 음성의 자연스러움과 스피커 유사성에서 최첨단 zero-shot TTS 시스템을 능가하며 스피커의 감정과 음향 환경을 보존할 수 있음.

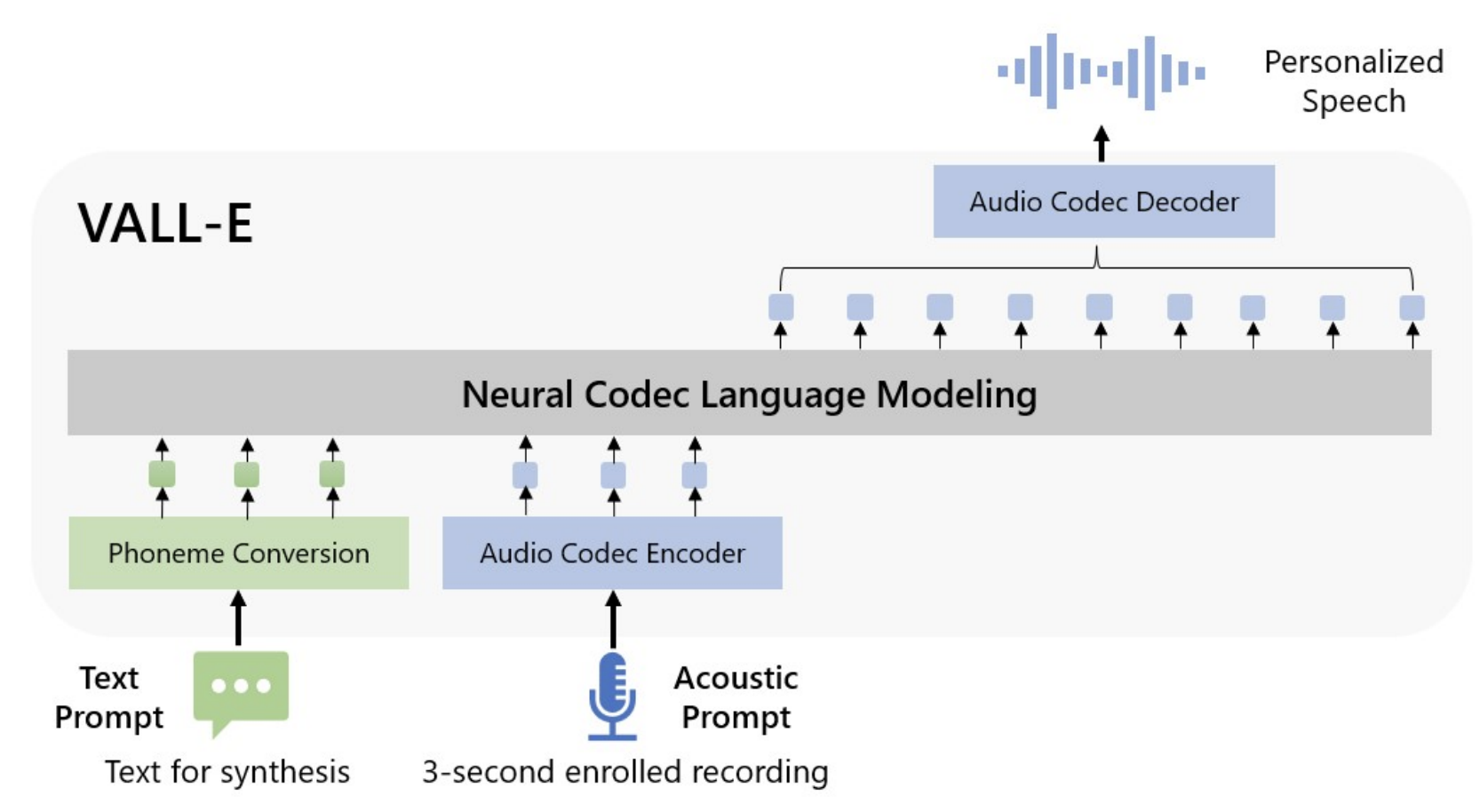
- 이전 Pipeline은 (phoneme -> mel spectrogram -> waveform)였음.
📌 VALLE-E의 Pipeline은 (phoneme -> discrete code -> waveform)임.
- 위의 그림을 통해 확인할 수 있는 바와 같이, VALL-E는 개별적인 음성(예: zero-shot TTS) 합성을 위해 3초 녹음된 음향 토큰과 음소 지시어를 사용하여 스피커와 내용 정보를 구분함.
- 이후에, 생성된 음향 토큰은 Decoder를 통해 최종 음성 파형으로 변환됨.
- 오디오 Codec 기반의 음향 토큰들을 활용하여 TTS를 조건부 Codec Language Modeling으로 처리하고, 이를 통해 TTS에서 선진적인 프롬프트 기반 기술을 적용할 수 있음.
- 음향 토큰의 사용은 추론 과정에서 여러 샘플링 방법을 통해 다양한 결과물을 생성하는 데 도움을 줌.
1. Introduction
- 최근 10년 동안 음성 합성 분야에서는 신경망과 종단 간 모델링의 발전으로 큰 진전이 있었음.
- 현대의 Text to Speech (TTS) 시스템은 대부분 mel spectrograms을 중간 표현으로 사용하는 음향 모델과 vocoder로 구성되어 있음.
기존 문제점
(1) TTS 구조가 매우 복잡하고, Engineering 공수가 큼
(2) 고품질의 음성 합성을 위해서는 깨끗한 데이터가 필요했지만, 데이터 양이 많이 않고, 품질저하 이슈가 있음.
(3) Mel-Spectrogram을 사용하는 것은 불편한 issue
🤜 이러한 문제를 해결하기 위해 여러 방법이 시도되어 왔지만, 궁극적인 해결책은 다양한 데이터로 모델을 크게 훈련시키는 것으로 제시되어 왔음.
- VALL-E는 이러한 문제를 해결하기 위한 새로운 TTS 프레임워크로, 큰 다양한 다중 화자 음성 데이터를 활용
VALL-E의 접근방식
(1) 기존의 중간 표현인 mel spectrograms을 대체하여 언어 모델링 작업으로 음성 합성을 처리함
(2) TTS 프레임워크를 띄는 NLP 모델이라는 접근
(3) VALL-E는 다양한 출력을 제공할 수 있고, 음향 환경과 화자의 감정을 잘 유지할 수 있음.
-> 60K시간의 음성과 7,000명의 독립적인 화자를 구함.
(4) Text Modeling처럼 수많은 데이터를 통해 프롬프트를 기반으로 적용해보는 시도 (Incontext Learning)
(5) 잔향, 반향, 감정들을 감안해서 TTS 할 수 있게 됨.
(6) 하지만 데이터에는 노이즈가 많고 오타가 있지만, 거대한 데이터로 노이즈에 Robustness함.
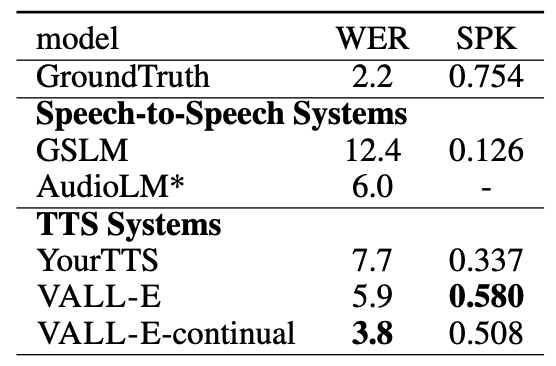
(7) VALL-E는 LibriLight라는 대규모 dataset을 활용하여 훈련되었으며, 테스트 결과 VALL-E는 기존의 Zero-Shot TTS 시스템보다 더 우수한 성능을 보였음.
🤜 LibriLight는 순수 오디오 데이터이기 때문에, 음성 인식 기술을 통해 텍스트로 전환함.
🤜 LibriTTS와 같은 이전의 TTS 데이터셋에 비해, LibriLight에는 다양한 스피커와 발음 패턴을 포함하고 있지만, 더 많은 잡음과 오류가 포함된 텍스트가 있을 수 있음.
🤜 VALL-E는 이러한 잡음에도 불구하고 대량의 데이터를 사용하여 잘 일반화됨.
🤜 전통적인 TTS 모델들은 일반적으로 한정된 스피커 데이터로 학습되지만, VALL-E는 이보다 훨씬 광범위한 데이터를 활용함.
- 아래 표는 오디오 코덱 코드를 중간 단계로 채택하고, 광범위한 데이터를 이용하여 탁월한 문맥 내 학습 능력을 지닌 TTS 언어 모델인 VALL-E의 독창적인 특징을 개략적으로 보여줌.

요약하면
• VALL-E는 GPT-3 기반의 첫 TTS 프레임워크로, 기존의 mel spectrograms 대신 Audio codec codes를 중간 표현으로 사용하며, 추가적인 엔지니어링이나 fine-tuning 없이 Zero-Shot TTS를 수행함.
• 엄청난 양의 semi-supervised data를 활용하여 일반화된 TTS 시스템을 만들었으며, 이러한 방식의 중요성이 과소평가되었음을 강조함.
• VALL-E는 주어진 Text로 다양한 출력을 생성하며, 음향 환경과 화자의 감정을 유지할 수 있음.
• VALL-E는 Zero-Shot 시나리오에서도 스피커와 유사한 자연스러운 음성 합성을 가능하게 하며, LibriSpeech 및 VCTK에서 뛰어난 성능을 보여줌.
2. Related Work
Zero-Shot TTS
- 현대의 TTS 방법은 Cascaded 방식과 End-To-End으로 분류됨.
Cascaded: acoustic model과 vocoder를 mel-spectrogram을 사용하여 처리함.
-> 실제 상황에서는 제한된 녹음의 임의의 목소리에 TTS System을 맞춤화하는 것이 바람직하므로, 대부분 cascaded 방식을 선호함.
-> VALLE는 Cascaded 방법론과 유사하게 학습하지만, audio codec을 사용함.
End-To-End: vocoder의 단점을 해결하기 위해 vocoder를 한꺼번에 학습시킬 수 있게함.
- 최초로 제안된 연구들은 speaker adaptation 및 speaker encoding-based을 도입함.
speaker adaptation: 화자를 표현하기 위한 별도의 Embedding Layer을 도입하여, 새로운 화자가 생길 때마다 해당 Embedding만 업데이트하도록 설계함. (단, 이 방식은 화자가 지속적으로 추가될 경우, Embedding의 Fine-Tuning이 자주 필요하므로 운영상 불리함.)
speaker encoding-based: YouTTS에 따르면, 다양한 화자들의 Embedding을 화자 구분 문제로서 학습하게 됨. 그리고 알려지지 않은 화자의 음성이 입력될 경우, 해당 Embedding에서 가장 가까운 발화 특성을 잡아내길 바라는 접근방식임.
- 최신 연구들은 더 나은 결과를 위해 복잡한 스피커 Encoder 디자인 & 확산 모델 기반 TTS를 활용함.
- 본 연구는 Cascaded TTS를 따르고, Audio Codec Code를 중간 표현으로 사용함
🤜 이 연구는 GPT-3와 같은 강력한 문맥 내 학습 능력을 가지고 Fine tuning, 사전 설계된 feature, 복잡한 스피커 Encoder가 필요 X
Spoken generative pre-trained models
- 음성 이해와 음성 생성 분야에서 자기 지도 학습이 널리 연구되고 있음.
🤜 음성 생성 분야에서 핵심 주제는 텍스트 없는 설정에서 음성을 합성하는 방법임.
-
GSLM은 HuBERT 코드를 기반으로 음성 합성 방법을 제안함
-
AudioLM은 audio codec을 사용하여 유사하게 학습하는데, 추가적인 vocoder or HifiGAN 없이 speech-to-speech 음성 합성할 수 있게 됨.
음성 합성 방법을 제안함 -
VALL-E는 TTS 모델이므로 음성 합성에서 내용을 명시적으로 제어할 수 있음.
-> 이전의 TTS 사전 훈련 작업은 1K 시간 미만의 데이터를 활용했지만, VALL-E는 60K 시간의 데이터로 사전 훈련됨.
-> 이는 중간표현으로 오디오 코덱 코드를 사용하는 최초의 모델로, Zero-Shot TTS에서 문맥 내 학습 능력을 발현함. -
Pre-Training의 장점은 Fine-Tuning하는 데 많은 데이터가 필요하지 않음.
-> 이전 TTS pre training은 1K 시간의 음성으로 했음.
-> VALL-E는 60K 시간으로 했고, audio codec을 사용하여 중간에서 음성 표현을 처리하고, in-context learning을 사용함.
3. Background: Speech Quantization
- 대체적으로, 오디오는 16비트 정수 값의 sequence로 저장되기 때문에 오디오를 합성하기 위해서는 timestep 당 2^16 = 65,536 확률들을 출력하는 생성 모델이 필요함.
- 오디오 샘플 속도가 10,000을 초과하게 되면 sequence의 길이가 길어져서 오디오 합성이 더 어려워짐.
- 이를 해결하기 위해 정수 값과 sequence 길이를 압축하기 위한 음성 Quantization 기법이 필요함.
- 기법을 이용하면 각 timestep을 256 값으로 오디오를 고해상도로 복원할 수 있음.
WaveNet, HuBERT : 이들은 빠르지만 발화자 특성을 고려하지 않는 학습으로, 다시 reconstruction했을 때 품질이 떨어짐.
- 최근에는 vq-wav2vec, HuBERT와 같은 Self-supervisd 방법을 이용한 음성 모델에 벡터 양자화 기법이 흔히 적용되고 있음.
🤜 이러한 모델에서 추출된 코드는 콘텐츠를 효과적으로 복원할 수 있으며, 처리 시간이 WaveNet보다 효율적임.
🤜 이러한 접근법에서는 화자의 특성이 손실될 수 있으며, 재구성된 음성의 품질이 일관되지 않을 수 있다는 한계점이 있음.
AudioLM
(1) K-means로 self-supervised를 하고, acoustic tokens을 neural codec model로부터 얻어오는데, 고품질 speech-to-speech 생성으로 이어짐.
(2) HuBERT의 K-Means의 빠른 장점과 WaveNet의 원복 장점을 결합함.
(3) HuBERT 방법론보다 정보량이 많고 원복이 잘 됨.
(4) 변환보다 속도 빠름 + Vocder가 필요 없음.
- 이 논문에서는 AudioLM을 따라 discrete tokens를 생성함.
-> unseen speaker에 대해서도 높은 품질의 waveform 얻을 수 있음.
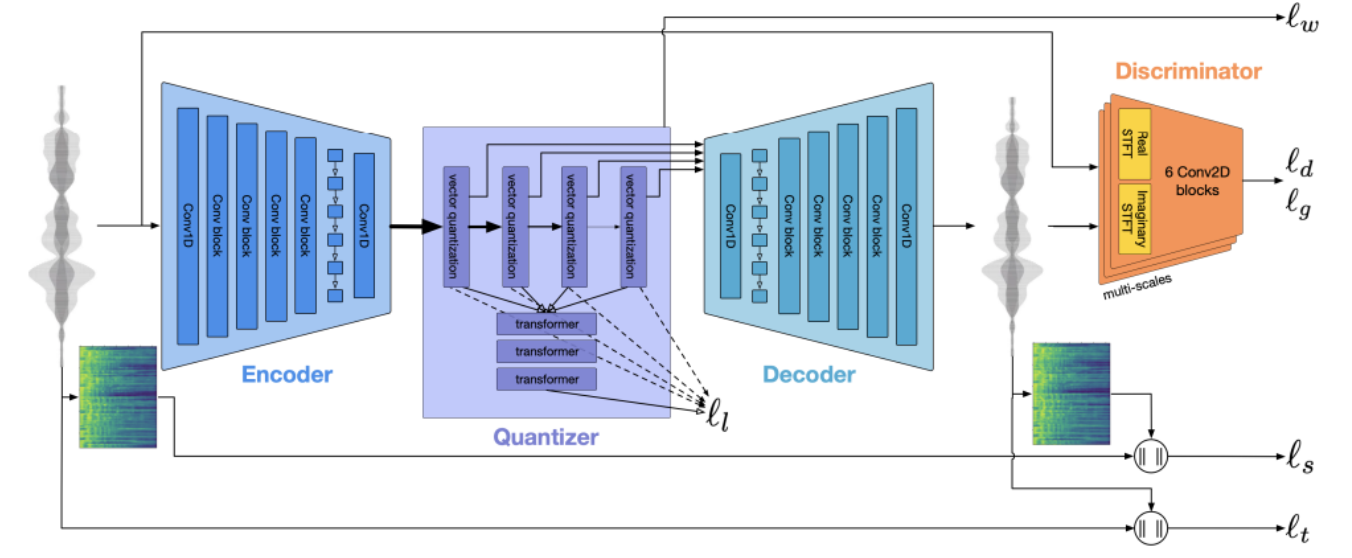
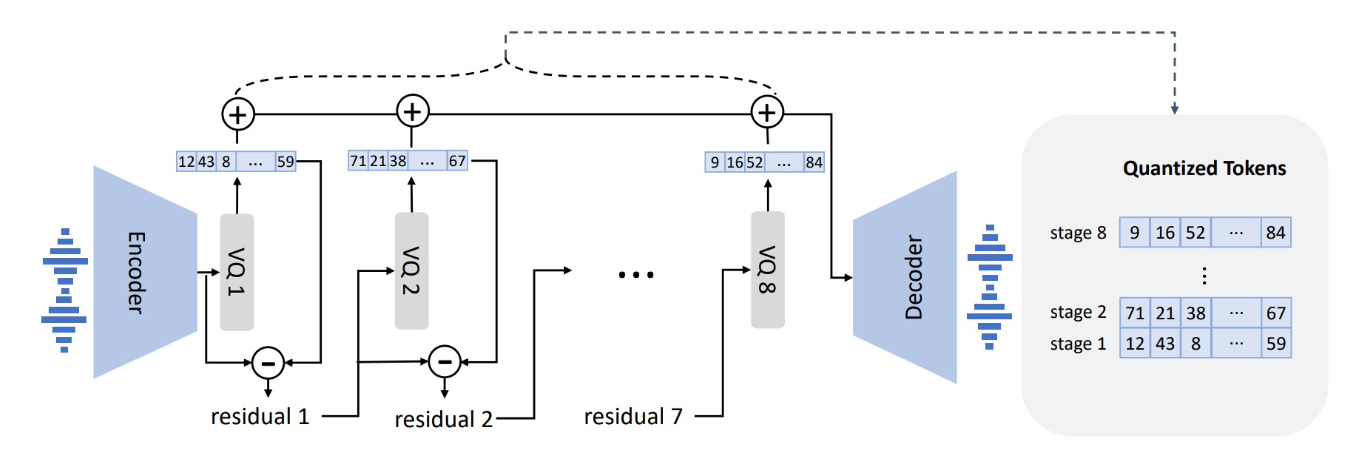
- 위의 그림은 SoundStream 논문에서의 RVQ이고, 아래는 위를 참고해서 비슷한 개념으로 만들어짐.
4. VALL-E
4.1. Problem Formulation: Regarding TTS as Conditional Codec Language Modeling
4.2. Training: Conditional Codec Language Modeling
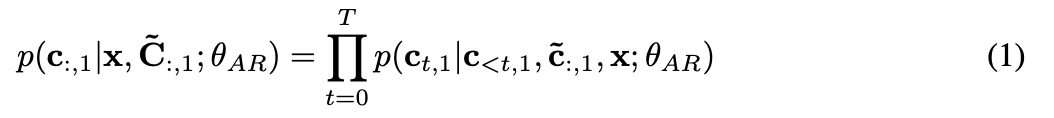
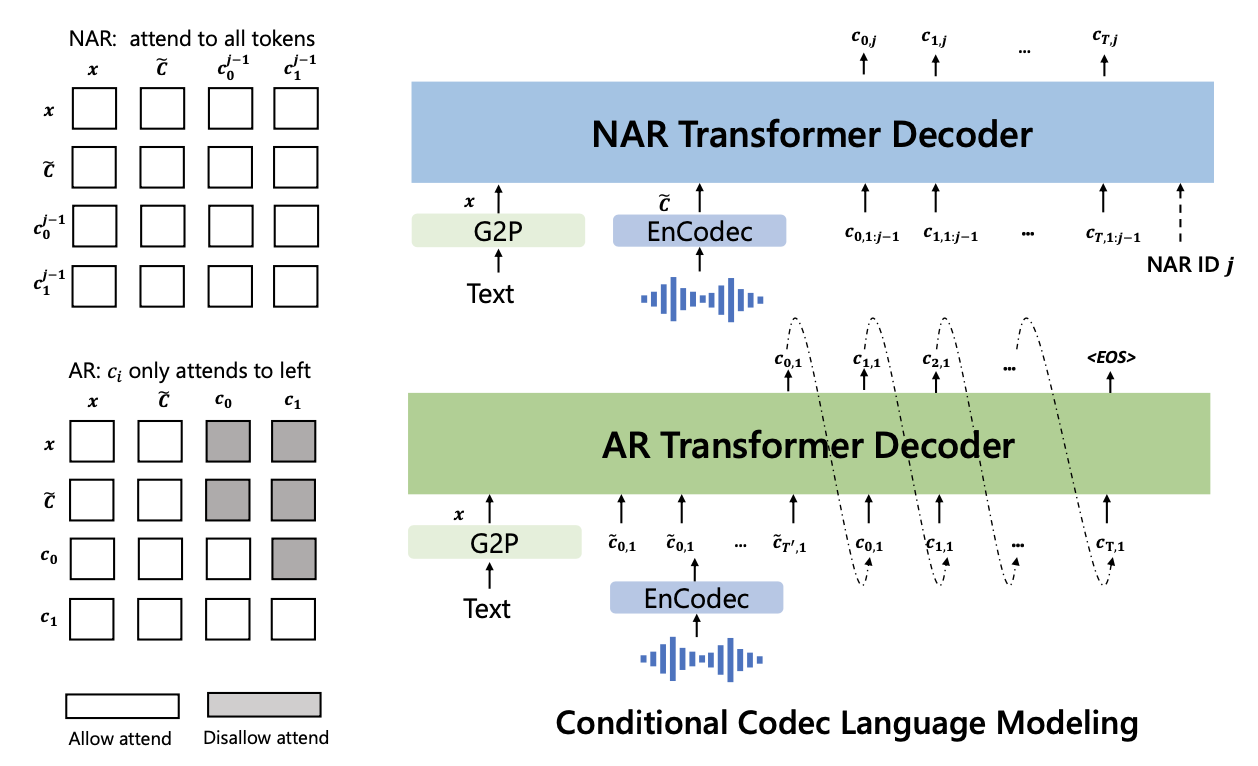

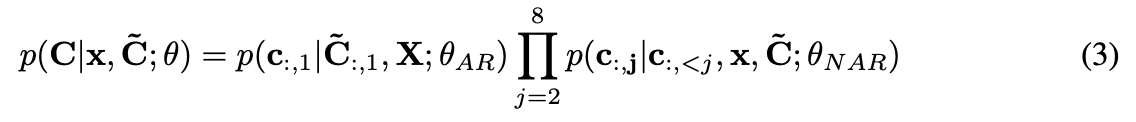
4.2.1. Autoregressive Codec Language Modeling
4.2.2. Non-Autoregressive Codec Language Modeling


4.3 Inference: In-Context Learning via Prompting
5. Experiment
5.1. Experiment Setup
Dataset
사용 데이터: LibriLight (60K 시간, 약 7000명의 화자로 구성된 영어 오디오북 데이터)
ASR 모델: 960시간의 LibriSpeech로 훈련된 DNN-HMM ASR 모델을 사용하여 레이블 없는 데이터 디코딩.
Model
AR 및 NAR 모델: 동일한 Transformer 아키텍처(12 계층, 16 attention heads, 임베딩 차원 1024 등).
학습 설정: NVIDIA TESLA V100 32GB GPU 16개를 사용하여 800k 스텝 동안 훈련.
Baseline
- YourTTS 모델을 사용하여 성능 비교.
Automatic metrics
화자 유사성 평가: WavLM-TDNN 사용.
합성의 강건성 평가: 생성된 오디오에 대한 ASR 수행 및 원본 전사와의 WER 계산.
Human evaluation
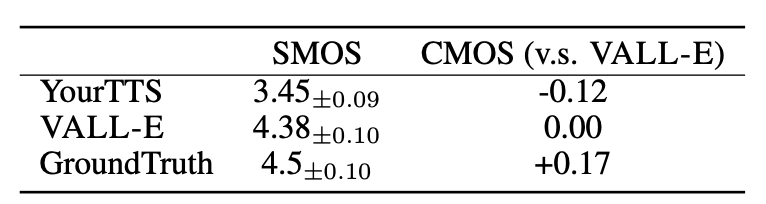
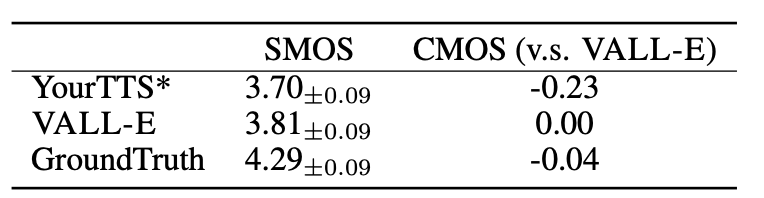
- CMOS 및 SMOS를 통한 평가 수행
- CMOS는 음성의 자연스러움을, SMOS는 원본 화자의 목소리와의 유사성을 측정.
5.2. LibriSpeech Evaluation
- 아래는 오디오 생성에 대한 평가 결과임.
- 아래는 human evaluation 결과임.
- 아래는 NAR 모델에 대한 ablation study 결과임.

- 아래는 AR 모델에 대한 ablation study 결과

5.3. VCTK Evaluation
- 아래는 VCTK의 speaker 108명에 대한 spekaer 유사성을 평가한 결과임.
- YourTTS는 학습 중에 97명의 speaker를 보았지만, VALL-E는 모든 speaker를 보지 못하였다.
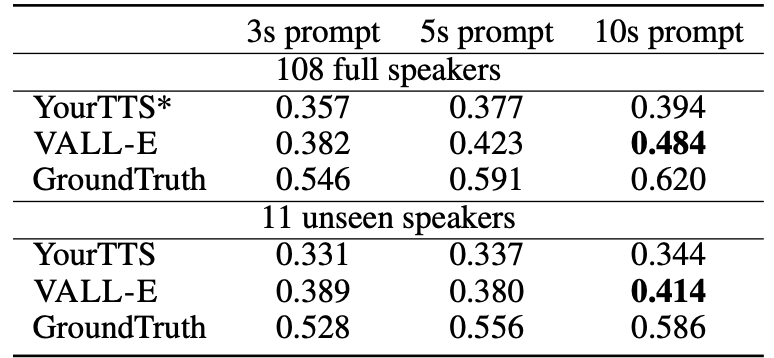
- 아래는 CTK의 speaker 60명에 대한 human evaluation 결과임.
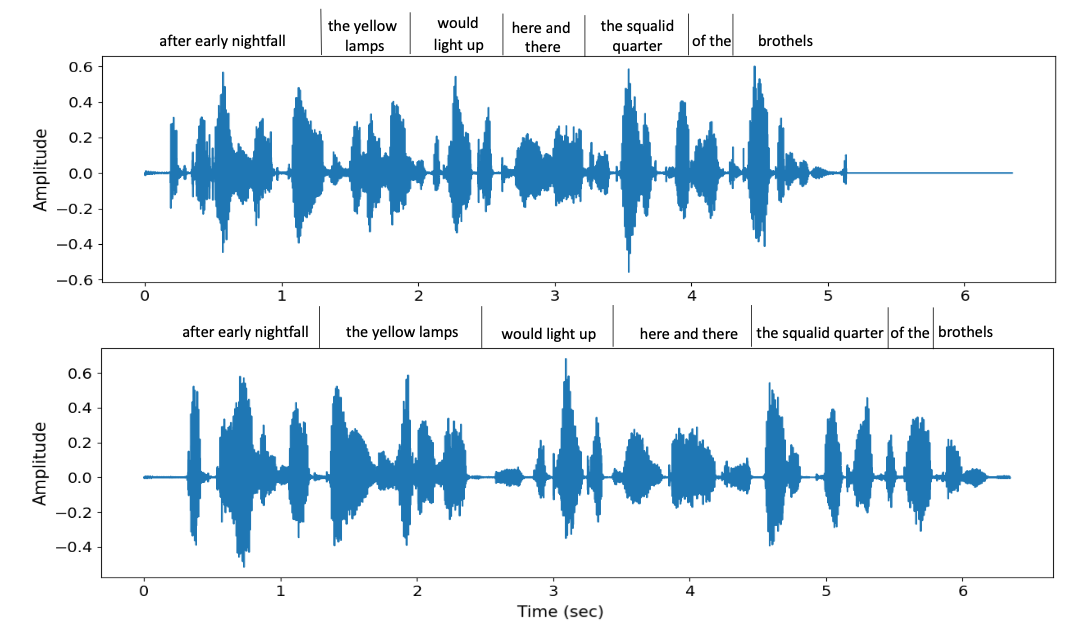
- 아래는 VALL-E의 다양성을 보여주는 LibriSpeech 샘플과 VCTK 샘플들임.
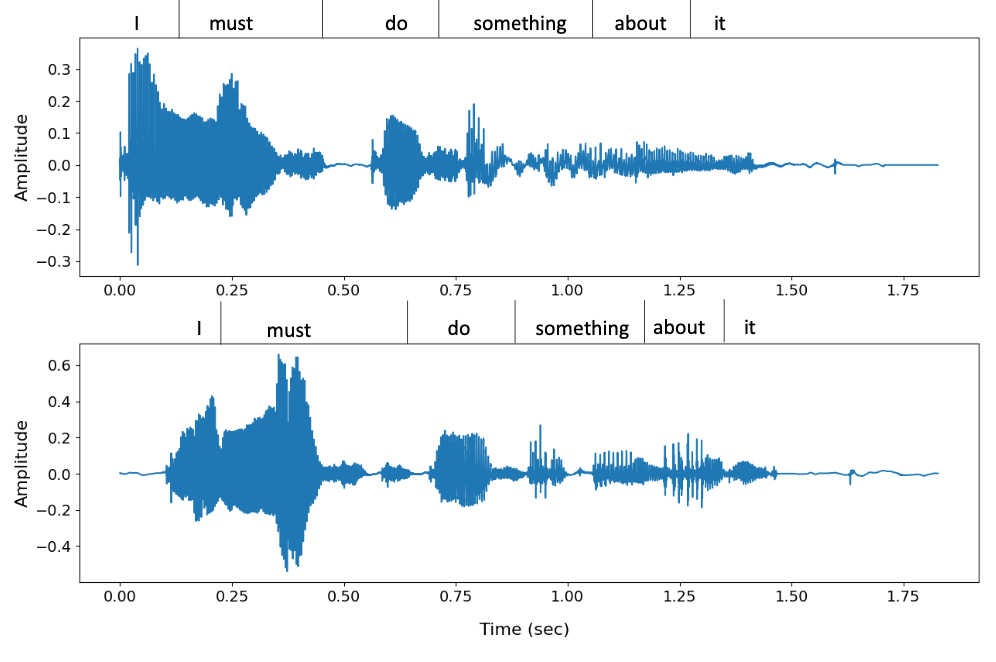
5.4 Qualitative Analysis
6. Conclusion, Limitations, and Future Work
6.1. Conclusion
- VALL-E는 TTS를 위한 Language Model 방식을 사용하며 오디오 코덱 코드를 중간 표현으로 사용함.
- 60K 시간의 음성 데이터로 pre-train했고, Zero-Shot 시나리오에서의 능력을 보여줌.
- LibriSpeech와 VCTK에서 최고의 Zero-Shot TTS 결과를 달성하였고, 합성 과정에서 음향 환경과 화자의 감정을 유지하며 다양한 출력을 제공함.
6.2. Limitations
Synthesis robustness
- VALL-E에서 음성 합성 시 일부 단어가 불분명하거나 누락되거나 중복될 수 있음.
- 이는 주로 자동 회귀 모델인 phoneme-to-acoustic 부분 때문에 발생하며, 주의가 정렬되지 않아 문제를 해결할 제약이 없음.
- 이 현상은 기본 Transformer 기반 TTS에서도 관찰되고, 비자동회귀 모델 사용 or Attention mechanism으로 해결됨.
Data coverage
- 60K 시간의 학습 데이터를 사용하더라도 모든 사람의 목소리 특히 악센트를 가진 화자를 포함시키지 못한다는 한계가 있음.
- VCTK의 결과가 LibriSpeech보다 나쁘다는 것은 악센트 화자에 대한 coverage가 부족하다는 것을 나타냄.
- LibriLight는 대부분 읽는 스타일의 발화로 구성된 오디오북 dataset이므로 발화 스타일의 다양성이 부족함.
- 앞으로는 학습 데이터를 더 확장하여 prossody, speaking style, 화자 유사성 측면에서 모델 성능을 향상 시킬 예정임. 이를 통해 zero-shot TTS 문제를 해결할 수 있을 것이라고 생각함.
Model Structure
- 현재 다른 quantizers의 코드를 예측하기 위해 2개의 모델을 사용하고 있음.
- 대규모 범용 모델로 예측하는 것이 유망한 방향이며, 프레임워크 내에서 모델 추론 속도를 높이기 위해 전체 NAR 모델을 사용하는 것도 흥미로움.
Broader impacts
- VALL-E는 화자의 정체성을 유지하며 음성을 합성할 수 있지만 모델의 오용의 문제점이 있음.
- 이러한 문제점을 줄이기 위해 VALL-E에 의해 합성된 오디오 클립인지 판별하는 탐지 모델을 구축할 수 있고, 모델 추가 개발할 때 MMicrosoft AI 원칙을 적용할 예정임.
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
- 이 연구는 TTS(Text to Speech)를 위한 새로운 접근 방식인 VALL-E라는 언어 모델을 소개하고자 함.
-> VALL-E를 통해서 짧은 시간의 음성을 가지고 사용자와 비슷한 목소리를 생성하는 것이 핵심.
- 이 모델은 오디오 코덱 코드를 중간 표현으로 사용하여 텍스트를 음성으로 변환
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
- 중요한 요소는 "오디오 코덱 코드"를 중간 표현으로 사용하는 것과 "in-context 학습 능력"을 가진 VALL-E 모델임.
- 이 모델은 zero shot 시나리오에서도 효과적으로 작동한다는 점
- 어느 프로젝트에 적용할 수 있는가?
- VALL-E는 TTS(Text to Speech) 프로젝트, 특히 zero shot TTS 시나리오, 개인화된 음성 합성 및 다양한 환경/감정을 포함하는 음성 합성에 적용될 수 있음.
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- AudioLM: a Language Modeling Approach to Audio Generation
🤜 vocoder없는 speech to speech 모델링을 위한 Spectrogram 표현 기법
https://arxiv.org/abs/2209.03143
- SoundStream: An End-to-End Neural Audio Codec
🤜 어떻게 Audio 표현을 잘 압축할 수 있을까?
https://arxiv.org/abs/2107.03312
- 느낀점은?
📚 References
논문
Youtube
블로그
