TIL
1.[TIL] 2020.07.13
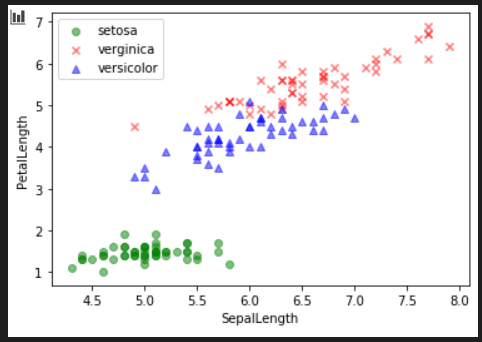
정처기 2번째 책 나머지 보기오늘 배운 내용 정리vscode python환경구축붓꽃데이터를 이용하여 SepalLength를 가로축으로, PetalLength를 세로축으로 하고, Species별로 색이 다르게 나오는 산점도 그리기.단층 퍼셉트론 : 일련의 퍼셉트론을 한줄
2.[TIL] 20.07.14

딥러닝 데이터셋 다운로드velog 작성정처기 chap72까지정규식을 사용한 예시. 전화번호의 정규식을 compile한 후, 그에 매치 되는 내용을 찾는다. 그 후 중간 부분의 전화번호를 바꿔준다.pandas를 이용한 시각화matplotlib을 시각화하는데 많이 사용한다
3.[TIL] 20.07.15
정처기 chap94velog TIL 작성정규표현식 공부온라인 강의 2개 듣기정규표현식import re하여 사용한다. 표현하고자 하는 식은 p = re.compile()에 괄호안에 적는다.<주로 사용하는 기능>'.' : 어떤 문자든 한개'+' : 문자를 원하는 만큼
4.[TIL] 20.07.16
계획한 일 velog작성 tokenize 공부 정처기 3권 풀기 공부한 것 >tokenize 사용 word_tokenize를 사용하여 단어별로 문장을 잘라준다. 잘라진 단어중 의미에 상관없는 불필요한 단어들을 제거해준다. 각 단어의 개수를 세어 내림차순으로 정렬한
5.[WIL] 20.07.3rd week
딥러닝(단층 퍼셉트론)단층 퍼셉트론은 은닉층이 없는 신경망이다. 입력층과 출력층으로 이루어져 있으며, 입력값과 가중치, 편향을 이용하여 출력값을 구한다. 입력값의 수와 가중치의 수는 같고, 편향과 출력값, 퍼셉트론의 수가 같다.딥러닝을 진행할 때는 데이터를 미니배치하여
6.[TIL] 20.07.20
정처기 1권 정리본 읽고, 1권 문제 풀기stack클래스 구현 with pythontil작성행렬곱인 matmul과 전치 행렬을 사용했다.konlpy를 사용하기 위해서는 jdk, JPype가 필요하다.jdk는 환경변수 설정을 한 후, JPype를 다운받아 pip를 이용하
7.[TIL] 20.07.21
정치기 2권 풀기velog작성딥러닝 2번째 코드 실행신경망은 값이 일정하지 않은 값으로 나오지 1과 0으로 나오게 할 수는 없다.따라서 신경망의 결과를 시그모이드 함수와 같은 비선형 함수를 이용하여 0과 1의 사이의 값으로 출력하게 한다.신경망으로 출력된 임의의 실수값
8.[TIL] 20.07.22
정처기 3권 풀고 모의고사 5개정렬 알고리즘 작성velog작성엔트로피는 불확실한 정보를 숫자로 정량화하려는 노력이다. 정보량을 나타낸다.이는 어떠한 사건이 일어날 확률의 역수에 로그를 취한 값이다.엔트로피는 불확실한 정보를 수치화하는 것이므로 높은 엔트로피는 높은 불확
9.[TIL] 20.07.23
정처기 수제비 모의고사 풀어보기오늘 배운 내용 정리해서 velog나이브베이즈 실행 성공시키기sort 알고리즘 작성어제 짠 코드를 활용하여 한국어 단어 분류기를 만들었다.여기에서 ratings_test.txt파일을 이용하여 학습을 진행했다. 같은 방법으로 진행하나 이 파
10.[WIL] 20.07.4st week

11.[TIL] 20.07.29
다층 퍼셉트론 다수의 퍼셉트론 계층들을 순서에 따라 배치하여 중간단계의 은닉층부터 출력층을 거쳐 출력벡터를 산출한다. >은닉계층 : 직접 드러나지 않는 계층이며 이를 통한 출력물을 '은닉벡터'라고 한다. 한계층의 파라미터 수 = (입력수) * 퍼셉트론의 수 + 편향
12.[TIL] 20.07.30
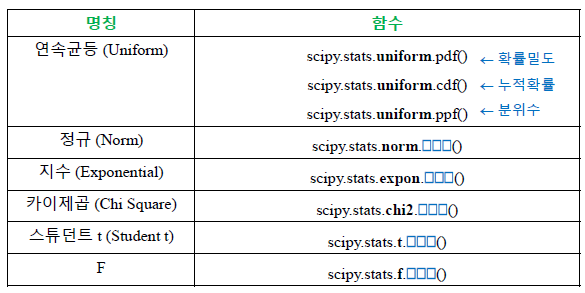
누적확률함수(CDF) : 연속균등분포의 함수에서 지점까지의 면적과 같다.스튜던트 t분포 : 정규분포의 평균을 측정할 때 사용하는 분포. 자유도가 커질수록 표준정규분포에 가까워짐.카이제곱분포 : 자유도 k개의 표준정규 변수를 각각 제곱한 다음 합해서 얻어지는 분포. 신뢰
13.[WIL] 20.07.lastweek
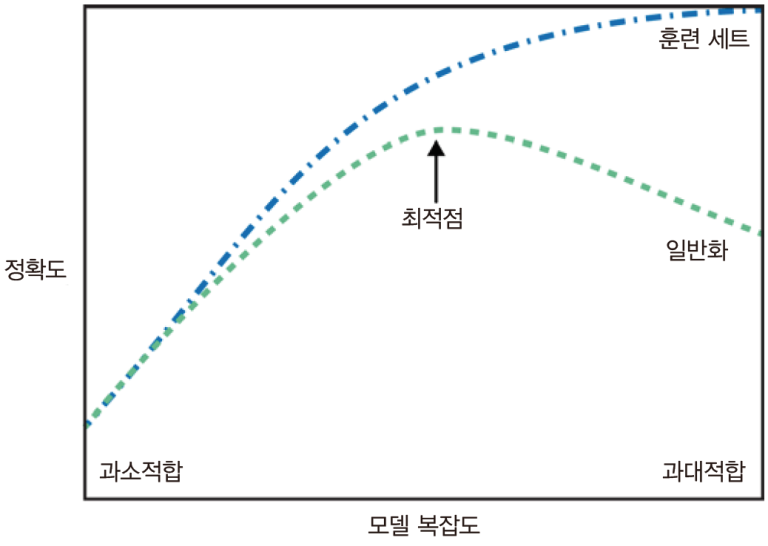
이번주는 개인적인 일도 생기고 정신도 없는 한주였던거 같다.... 주 초에 복습을 하지 못하니 뒤에 내용을 이해하는데 어려움이 있었다.이번주는 집에서 들었는데, 여기 있으니 확실히 공부를 덜하는.... (ㄴ이모지 처음 써봄 ㅎㅎ)로짓값 벡터를 확률분포 벡터로 변환해주
14.[TIL] 20.08.03
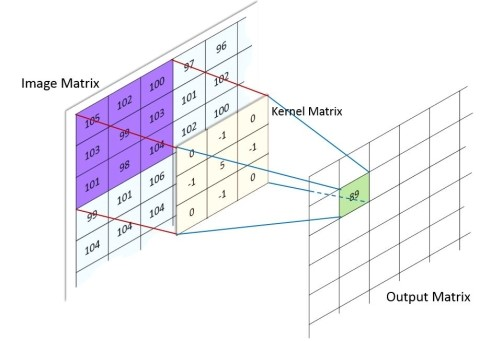
이미지 처리에 알맞게 은닉층을 배치한 신경망은닉층에 파라미터 수가 적어진 합성곱계층과 파라미터가 없는 풀링계층이 존재한다.출처:http://ww1.machinelearninguru.com/?subid1=2c57a700-d57c-11ea-8716-3d334e21
15.[TIL] 20.08.04
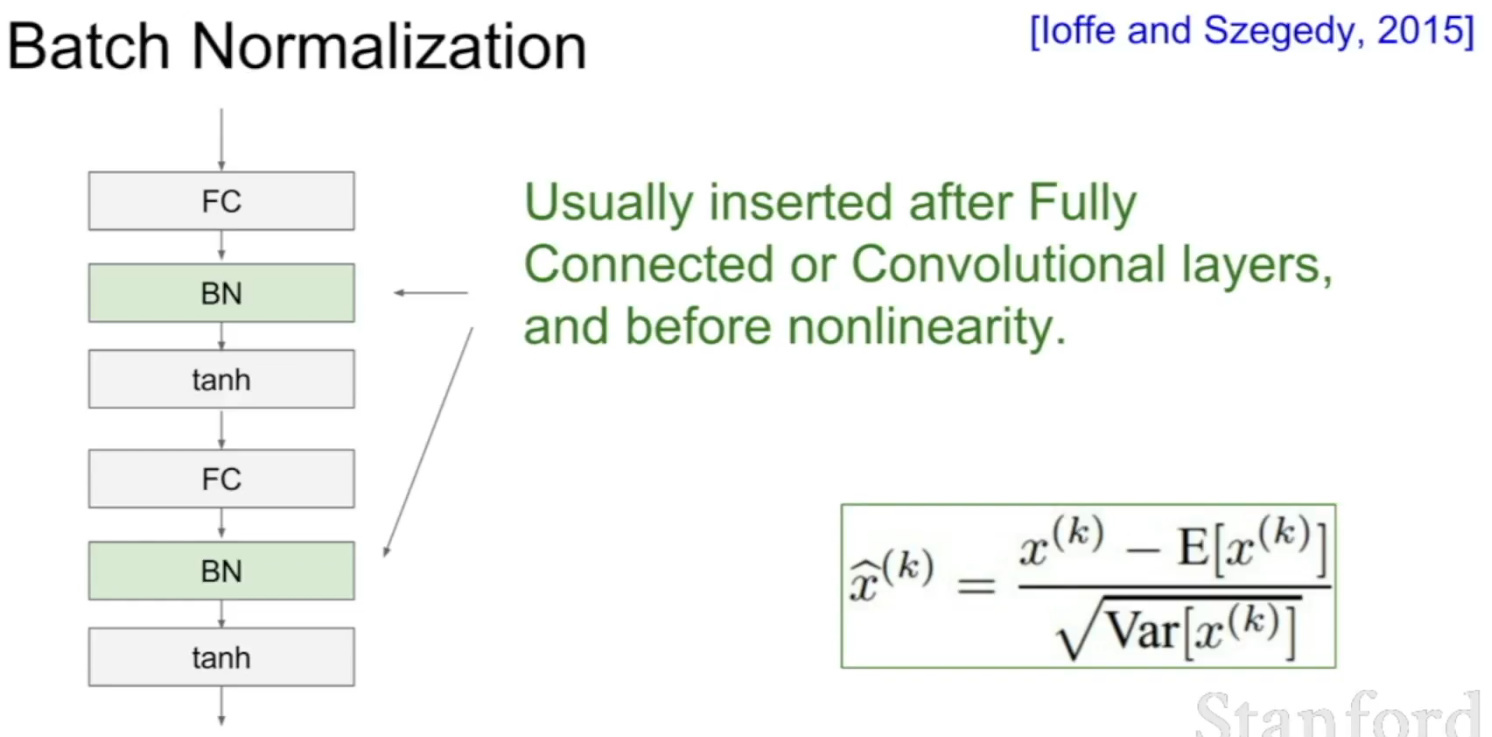
학습률을 개별 파라미터 별로 동적으로 조절해 경사하강법의 동작을 보완하고 학습 품질을 높여주는 방법.모멘텀, 2차 모멘텀과 학습률을 활용한다.파라미터 하나마다 모멘텀 정보와 2차 모멘텀 정보가 따라붙게 되어 파라미터 관리에 필요한 메모리 소비량이 매우 증가한다.또한 학
16.[TIL] 20.08.05
뉴런의 연결을 임의로 삭제하여 일부의 퍼셉트론을 학습과정에서 계산하지 않는 방법과적합 방지를 위한 방법이며, 하나의 신경망을 여러개의 작은 신경망으로 나눠서 계산하다보니 계산량을 오히려 늘어난다.학습시점에서만 사용하며 테스트 과정에서는 모든 퍼셉트론을 계산한다. 이 방
17.[TIL] 20.08.06
완전 연결 계층만 사용.높은 손실값과 낮은 정확도를 보임.convolution계층만 사용파라미터수가 매우 증가하며 시간이 증가한다. 약간 향상되었지만, 여전치 높은 손실값과 낮은 정확도를 보인다. 과적합 발생convolution, pooling, dropout계층 사용
18.[WIL] 20.08. 1stWeek
입력값이 많은 이미지에 대해 파라미터 수를 줄이고, 좀 더 빠르고 정확한 방법으로 학습할 수 있도록 만들어진 신경망.중간층인 은닉층에 convolution, pooling계층이 번갈이 존재한다. 이를 통해 이미지의 픽셀. 즉 입력값이 줄어들기도 한다.convolutio
19.[TIL] 20.08.10
신경망을 모바일에서도 작동 가능하도록 네트워크 구조를 경량화한 신경망tensorflow_hub를 통해 불러와서 사용가능하다.한 도메인(예: 한글 문장)에서 다른 도메인(예: 영어로 된 문장)으로 시퀀스(sequence)를 변환하는 모델 학습즉, 문장을 입력받아 문장을
20.[TIL] 20.08.11
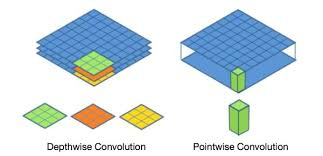
좋은 데이터로 훈련된 모델을 재사용하여 학습하는 기법모델 중 일부분을 가져와서 출력층의 레이어를 내가 풀고자하는 문제에 맞게 재구축하여 사용한다.이때 가져온 모델 중 사용하지 않는 레이어를 'freeze'한다고 한다.어떤 필터의 크기든 3x3필터를 여러번 사용하면 같아
21.[TIL] 20.08.12
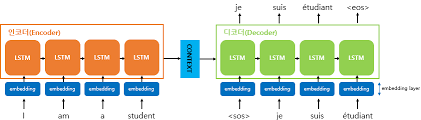
훈련때와 다르게 decoder_input이 없다.그래서 decoder를 문장 대신 단어 하나로 생각하도록한다.즉, encoder의 마지막 은닉/쉘 상태 값과 <'start'>를 입력값으로 LSTM을 하나만 실행한다.이때 나온 단어들의 확률값과 은닉/쉘 상태값을 다
22.[TIL] 20.08.13

두 이미지의 스타일과 내용이 합성된 제 3의 이미지를 만들기VGG-19모델에서 마지막 레이어를 제거하고 이용하였다.원본 사진, 타깃 사진의 각 레이어에서 gram matrix를 추출한다. 각각에서 구한 2개의 gram matrix의 MSE를 구하여 MSE가 작아지도록
23.[WIL] 20.08.2nd Week
텐서플로우 허브에서 좋은 데이터로 훈련되어 있는 모델을 가져와서 사용한다.(= 전이학습)네트워크 구조를 경량화 하고 성능을 향상시킨 모델으로 모바일 환경에서도 사용가능하게 하였다.전이학습 : 미리 훈련된 좋은 성능을 보이는 모델을 가져와서 일부분 혹은 전부를 사용하여
24.[TIL] 20.08.19

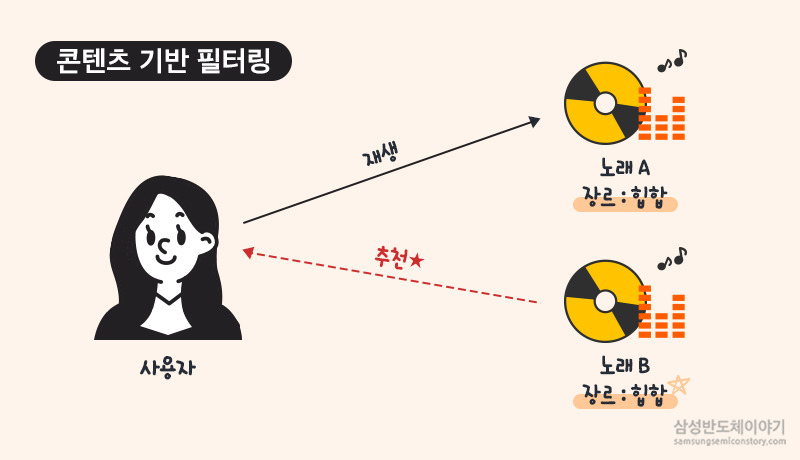
콘텐츠 기반 필터링 : 단어의 유사도를 측정하여 유사한것을 찾아서 추천가장 기본적으로 코사인 유사도를 사용한다.두 벡터의 내적을 이용하여 코사인 값을 계산하여 -1~1사이의 값으로 유사도를 추출한다.tfdif를 이용하여 단어들을 벡터화해준다. 벡터화가 된 단어들의 유사
25.[TIL] 20.08.20
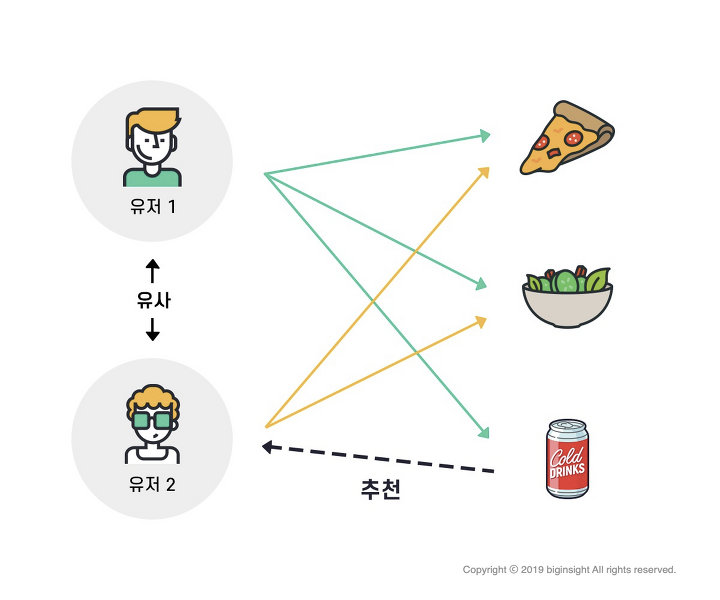
사용자 기반, 아이템 기반 협업 필터링으로 나뉘며 유사도가 높은 것을 추천해준다.출처 : https://brunch.co.kr/@biginsight/15사용자 기반의 경우 사용자와 활동내역이 비슷한 사용자를 찾아 그 사람의 내용을 추천해준다.출처 : https
26.[WIL] 20.08 3rd week
자기자신을 재생성하는 신경망으로 출력값을 입력값의 근사로 하는 함수를 학습하는 비지도 학습이다.다른 신경망과 달리 이 신경망은 입력과 출력이 동일하다.인코더를 진행한 후 중간에 잠재변수가 있어서 출력값을 일차원 벡터로 만들어 준다.이 일차원 벡터를 디코더에 전달하여 원
27.[TIL] 20.08.24
범주형 데이터를 코드형 숫자값으로 변환해주는 것이다.카테고리 특성을 코드형 숫자 값으로 변환하는 것이다.인코딩 반환값 : 0 1 4 5 3 2인코딩 클래스 : 'TV' '냉장고' '믹서' '선풍기' '전자렌지' '컴퓨터'인코딩을 진행할 결과과 다음과 같이 출력된다.
28.[TIL] 20.08.26
데이터에 대한 답이 주어지지 않을 상태에서 컴퓨터를 학습시키는 방법데이터를 비슷한 특성끼리 묶는 군집과 차원축소로 나눠진다.데이터 과학자들이 데이터를 더 잘 이해하고 싶을 때 탐색적 분석 단계에서 많이 사용한다.데이터를 새롭게 표현하여 원래 데이터보다 쉽게 해석할 수