연속확률밀도
누적확률함수(CDF) : 연속균등분포의 함수에서 지점까지의 면적과 같다.
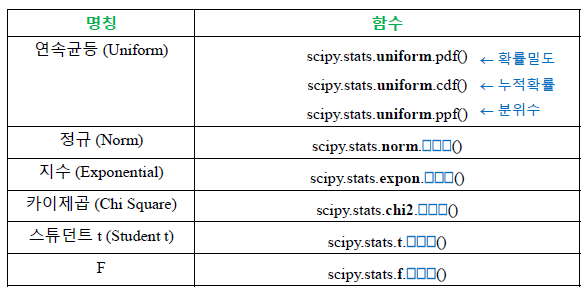
스튜던트 t분포 : 정규분포의 평균을 측정할 때 사용하는 분포.
자유도가 커질수록 표준정규분포에 가까워짐.
카이제곱분포 : 자유도 k개의 표준정규 변수를 각각 제곱한 다음 합해서 얻어지는 분포.
신뢰구간이나 가설검증 등의 모델에서 자주 등장.
F분포 : 2개 이상의 표본평균들이 동일집단에서 추출되었는지를 판단하기 위해 사용.
다층 퍼셉트론 with tensorflow
model = tf.keras.Sequential([
tf.keras.layers.Dense(units= 52, activation='relu',input_shape = (13, )),
tf.keras.layers.Dense(units= 39, activation='relu'),
tf.keras.layers.Dense(units= 26, activation='relu'),
tf.keras.layers.Dense(units= 1)
])keras를 이용하여 신경망을 쌓는 방법이다.
현재 입력층을 제외하고 4개의 층으로 구성되어있으며, 각 라인의 units는 퍼셉트론의 수를 말한다.
중간에 단순 선형으로 출력되지 않게 하기 위해 relu함수를 중간층에 적용해주었다.
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss = 'mse')
history = model.fit(train_X, train_Y,epochs = 25, batch_size = 32, validation_split = 0.25)생성한 모델을 최적화 해주고, 학습을 진행하였다.
학습횟수와 배치 사이즈, 검증데이터의 크기를 지정해준다.
LSTM 구현 with python
<흐름도>
문자열을 단어별로 자름 -> 훈련, 테스트 데이터로 나눔 -> stopword제거 -> 단어들을 토큰화 진행 -> 단어 인덱스 설정 -> 문장 길이 지정 -> 단어 임베딩 -> 모델 학습 -> 정확도 측정
다중 분류 with Logistic Regression
Logistic Regression은 기본적으로 다중 분류를 지원한다.
느낀점
- 주 초에 복습을 밀리니까 계속 밀리고 뒤에 내용이 이해가 안가는 느낌이다.
모르는 내용에 대한 질문 거리를 정리해야할 거 같다. - 어느새 한달이 지났는데 아직 남는게 없어 불안하긴 하다..
- 다른 사람들은 어떻게 공부하는지 궁금하다 어떻게 공부해야할지를 모르겠다.

안녕하세요 ㅎㅎ