
딥러닝 + 예술
두 이미지의 스타일과 내용이 합성된 제 3의 이미지를 만들기
VGG-19모델에서 마지막 레이어를 제거하고 이용하였다.
원본 사진, 타깃 사진의 각 레이어에서 gram matrix를 추출한다. 각각에서 구한 2개의 gram matrix의 MSE를 구하여 MSE가 작아지도록 타깃 사진을 변형한다.
장식자와 GradientTape를 사용했다.
tf.function(장식자) = 성능을 올려주는 함술 빠른 연산과 가중치 연산을 직관적이게 해준다.
GradientTape = 계산에 관계되는 모든 변수와 연산을 추적해주는 역할을 한다.


Seq2Seq를 이용한 챗봇
https://github.com/songys/Chatbot_data
여기에 있는 데이터와 Seq2Seq모델을 이용하여 위로의 말을 해주는 챗봇을 만들어봤다.
단순한 모델이라,

높은 손실값과 조금은 부족한 정확도를 보인다.

위에 문장은 입력한 문장이고, 밑에 문장은 답변이다.
조금은 이상하면서도 약간은 말이 되는 답변을 한다.
SVM
평면에서 분류하기 힘든 데이터를 차원을 늘려서 3차원에서 분류하도록 하는 모델
차원을 늘리는 방법에는 두가지가 있다.
- 원래 데이터를 제곱하여 새로운 값을 생성한다.
- 커널이라는 것을 사용하여 선형이 아닌 비선형으로 분류를 한다.
1번 기법은 3차원에서 평면으로 데이터를 분류하는 방법이다.

위에 사진과 같이 2차원에 있는 데이터에 추가하여 3차원으로 데이터를 옮긴다.
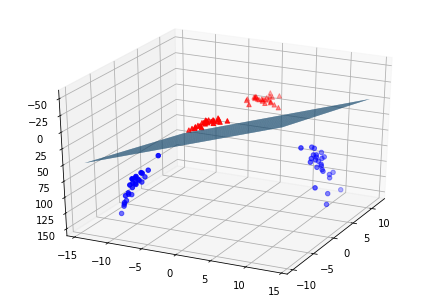
이처럼 옮겨진 데이터를 평면으록 분류가 가능해진다.
2번째 방법은 선형이 아닌 비선형으로 분류하는 방법이다.
model = SVC(kernel='rbf', C=10, gamma=0.5).fit(X, y) # 감마가 커질수록 강하게 감싸준다. (구분 공간이 작아진다). 감마값이 작을 수록 선형모델에 가까워진다.
mglearn.plots.plot_2d_separator(model, X)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
이처럼 곡선으로 분류를 진행한다. gamma의 값이 커질수록 구분공간이 작아지며 강하게 감싸준다. gamma값이 작아질수록 선형모델에 가까워진다.
느낀점
- 장고가 재밌다 ㅎㅎ 서버를 다뤄보는건 처음인데 신기했다.
네트워크 프로그래밍 할때와는 다른 느낌의 신선했다. - 이미지를 재구성하는 것을 보며 머지않아 인간의 예술 능력을 뛰어넘는 인공지능이 나올거 같다는 생각을 했다.
- 자연어처리가 재밌어진다. 신기하고 어떻게 해야할지 고민하게 된다.
- 다음주부터는 오프라인 수업인데 기대반 걱정반이다.
