CNN 실험 결과
- 완전 연결 계층만 사용.
- 높은 손실값과 낮은 정확도를 보임.
- convolution계층만 사용
- 파라미터수가 매우 증가하며 시간이 증가한다.
- 약간 향상되었지만, 여전치 높은 손실값과 낮은 정확도를 보인다.
- 과적합 발생
- convolution, pooling, dropout계층 사용
- 손실값과 정확도가 어느정도 향상됨.
- 드롭아웃이로인해 파라미터수가 감소하고 속도도 향상.
- 약간의 과적합 현상 해소.
- VGGNet 스타일 적용
- VGGNet 스타일의 일부를 적용
- 레이어가 깊어져 파라미터수가 증가.이로인한 컴퓨팅 파워가 필요.
- 과적합 현상이 해소
- 90%이상의 정확도를 보임.
여러가지 방법을 사용하여 비교해본 결과 VGGNet결과가 가장 좋았지만, 아직 정확도가 90%정도였다.
이를 좀 더 높이기 위한 방법으로는 데이터 보강과 학습량증가일 것으로 예측된다.
결정 트리 회귀
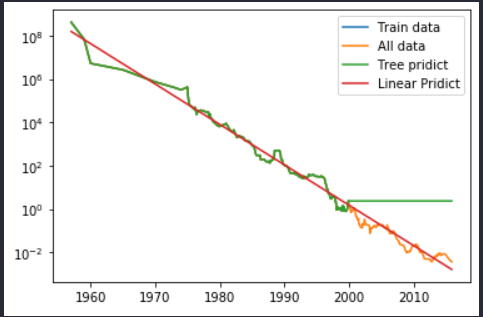
분류 결정 트리와 비슷하나 회귀 방식으로 사용된다. 훈련데이터의 범위 밖의 포인트는 예측이 불가하다.
model_tree = DecisionTreeRegressor().fit(X_train, y_train)
price_tree = model_tree.predict(X_test)
plt.semilogy(ram_prices.date, price_tree, label="Tree pridict")위의 코드는 결정트리회귀 모델을 생성하고 학습한 후, 테스트까지 진행한다. 그 후 semilogy를 이용하여 그래프로 시각화한다.
느낀점
- 어제는 서울로 올라오느라고 벨로그 작성이 좀 늦었다...
- 오늘의 내용은 복습 및 실습이 많아서 벨로그의 양이 적다.
- 이번주는 좀 정신없이 지나간것 같다.
주말동안 다음주에 어떻게 공부할지에 대한 고민이 필요할것 같다.

안녕하세요 ㅎㅎ