전이학습
좋은 데이터로 훈련된 모델을 재사용하여 학습하는 기법
모델 중 일부분을 가져와서 출력층의 레이어를 내가 풀고자하는 문제에 맞게 재구축하여 사용한다.
이때 가져온 모델 중 사용하지 않는 레이어를 'freeze'한다고 한다.
VGGNET
어떤 필터의 크기든 3x3필터를 여러번 사용하면 같아진다. 따라서 3x3필터만 사용하면 된다.는 것을 제시.
비선형 활성화 함수가 많아져서 더 많은 패턴을 학습할 수 있게 되고, 파라미터 수가 작아져 연산 회수를 줄일 수 있다.
Inception V2, V3
VGG모델의 영향을 받아 3x3필터만 사용하며 모든 채널을 한번에 계산하지 않고, 행, 열의 방향으로 나눠서 적용하는 방법.

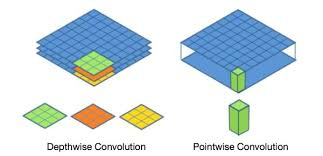
MobileNet
채널을 나눠서 계산한후, 다시 하나로 합쳐준다.
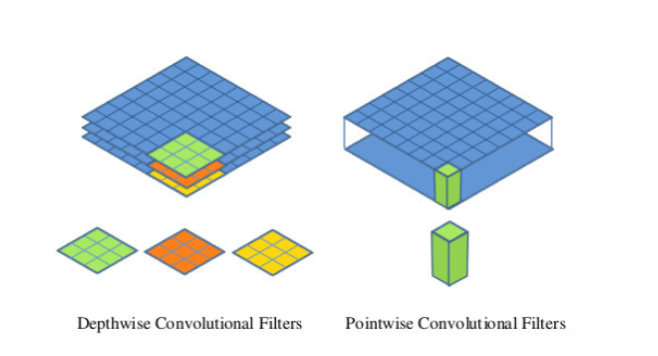
채널을 depth별로 분리하여 각각의 depth에 3x3필터를 거쳐 feature map을 생성해준다.
그 후 feature map들을 합쳐서 하나의 층으로 바꿔서 출력해준다.
이 방법은 정확도가 향상되진 않아도 네트워크 경량화에 상당히 효율적이다.
Seq2Seq (2)
인코더에서 입력값의 정보를 축적하여 마지막의 은닉상태/쉘상태의 값을 디코더에게 전달해준다.
이 내용을 바탕으로 단어에 대한 확률을 예측하고, 이 내용을 이용하여 다음단어를 예측한다
Bagging
중복을 허용한 랜덤 샘플링으로 만든 훈련세트를 사용하여 같은 분류기를 각각 다르게 학습
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import BaggingClassifier
# oob_score : 부스트래핑에 포함되지 않는 샘플을 기반으로 훈련된 모델을 평가
model = BaggingClassifier(LogisticRegression(solver='liblinear'),n_estimators=100, oob_score=True, n_jobs=-1, random_state=42)
model.fit(X_train, y_train)logistic회귀방법을 여려개로 bagging을 진행.
Extra Tree
후보 특성을 사용해 무작위로 분할한 다음 그중에서 최상의 분할을 선택하는 모델.
from sklearn.ensemble import ExtraTreesClassifier
model = ExtraTreesClassifier(n_estimators=5, random_state=42)
model.fit(X_train, y_train)다른 모델과 같은 방법으로 학습진행.
트리의 개수를 5개로 정하고 random_state값을 지정.
시각화를 해본 결과 각각의 트리는 과적합이 심하게 나타나는데, 최종 모델은 좋은 성능을 보인다.
extra tree는 랜덤포레스트와 거의 같은 성능을 낸다.
계산비용은 적지만 무작위 분할때문에 일반화 성능을 높이려면 많은 트리가 필요하다.
느낀점
- 머신러닝의 지도학습이 끝나가는데 내가 하려는 프로젝트의 해답이 보이지 않아 답답하다
- 자연어 처리에 대한 관심이 증가하는데 어려워서 걱정이다. 이를 좀 더 보충할 방법을 생각해봐야겠다.(서적 구매할까...)
- 비가 너무 많이 온다.... 빨리 그쳤으면 좋겠다...
- 다음주부터 오프라인이라는데 뭔가 긴장되고 설렌다.
