
아래 내용은 개인적으로 공부한 내용을 정리하기 위해 작성하였습니다. 혹시 보완해야할 점이나 잘못된 내용있을 경우 메일이나 댓글로 알려주시면 감사하겠습니다.
AlexNet?
캐나다 토론토 대학에서 발표한 AlexNet은 2012년 개최된 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)에서 압도적인 성능으로 우승한 CNN Network 입니다.
Top-5 error rate 16.4%라는 압도적인 성능차이로 주목을 받게 되었고, 특히 GPU를 사용한 병렬연산으로 의미있는 결과를 보여준 모델입니다.
AlexNet역시 이 글을 쓰는 시점인 2021년에는 그리 좋은 성능이 아니지만 LeNet과 마찬가지로 CNN Network들의 발전 흐름을 복습하기 위해 논문과 기타 자료를 참고하여 간단히 정리해 보았습니다.
특징
AlexNet은 Convolution layer 통과 후 Pooling, 마지막에 Fully-Connected layer로 class를 분류하는 형태로 지난시간 알아본 LeNet-5와 구조적으로 보면 큰 차이는 없습니다.
하지만 세부적으로 보면 성능개선을 위해 여러 방향으로 고민한 흔적을 볼 수 있습니다.
아래 그림은 AlexNet을 발표한 논문 ImageNet Classification with Deep Convolutional Neural Network에 있는 AlexNet의 전체 구조를 나타낸 그림입니다.
구조

위의 첫 번째 그림은 논문에 나온 AlexNet의 전체 구조이며 5개의 convolutional layer와 3개의 fully-connected layer로 구성되어 있습니다. 마지막 output 결과는 softmax 연산을 거쳐 1000개의 class label에 대한 확률값으로 출력됩니다.
1) Multi-GPU 사용
AlexNet 개발자들은 Network를 학습하기 위해서는 1,200만개의 샘플이 필요하다고 밝혔습니다. 하지만 AlexNet을 개발할 당시 사용한 GPU는 GTX580로, 3GB 메모리만 가지고 있기 때문에 한개에 GPU에서 연산하기에는 한계가 있었고, 따라서 개발자들은 아래 그림과 같이 Network를 두 개의 GPU로 나눌 수 있는 구조로 설계했습니다.
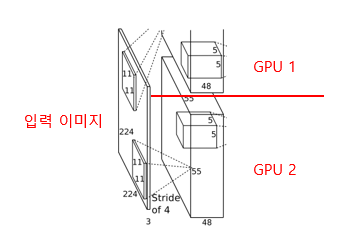
병렬구조를 사용하기 위한 또 한가지 트릭(꼼수?)으로 3번 Convolutional layer(이하 Conv layer)와 Fully-Connected layer(이하 FC layer)에서는 GPU끼리 parameter를 공유합니다. 즉, 1, 2번 GPU의 결과를 섞어 쓸 수 있는 inter-connection을 추가한겁니다.
AlexNet의 구조를 자세히 보면 세 번째 Conv layer의 kernel과 FC layer는 1번과 2번 GPU의 feature map 모두를 입력으로 받고 있습니다.(Inter-connection) 그 외 layer들은 같은 GPU에 있는 결과값만 입력으로 받아 사용합니다.(Intra-connection)
전체 구조 그림에서 Inter/Intra connection을 나타내면 아래 그림과 같이 표현할 수 있습니다. 붉은색 라인이 두 GPU값을 모두 사용하는 inter-connection, 파란색 라인이 자기 자신의 GPU값만을 사용하는 intra-connection 입니다.
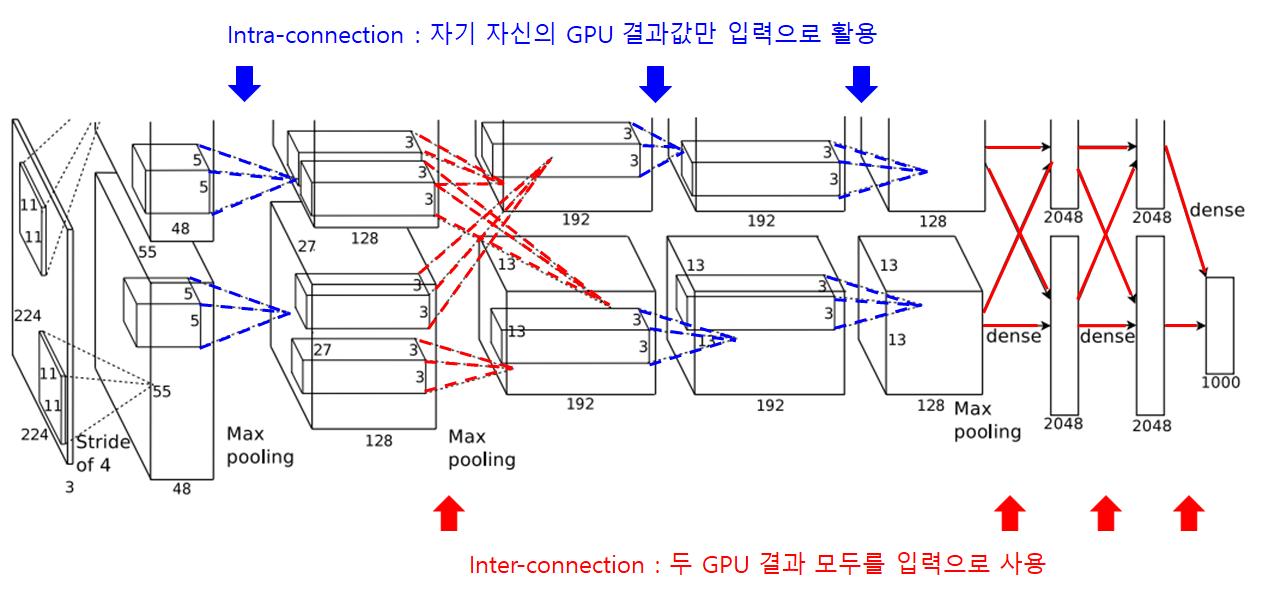
또, GPU 1에서는 주로 컬러와 상관없는 정보를 추출하기위한 kernel이 학습되고,
GPU 2에서는 color에 관련된 정보를 추출가히위한 kernel이 학습된다고 합니다.

2) ReLU사용
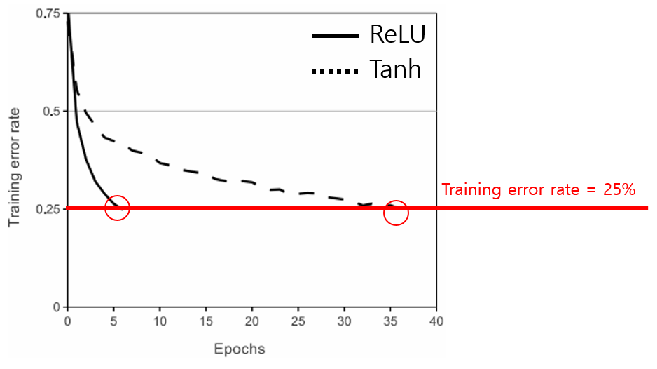
AlexNet에는 해당 논문 발표 전까지 가장 일반적으로 쓰이던 활성함수인 Tanh 대신 ReLU를 활성함수로 사용합니다.
ReLU를 사용함으로 써 가장 큰 장점은 학습속도가 빨라지는 것 입니다. 실제로 AlexNet개발자들은 CIFAR-10데이터셋과 4개의 Convolutional network를 사용해 Tanh와 ReLU의 학습속도를 비교했습니다. 실험결과는 아래 그림과 같이 training error rate가 25%까지 내려가는데 걸리는 epoch를 비교하였고, ReLU가 Tanh보다 약 7배 가까이 빠른것을 확인할 수 있습니다.
3) LRN(Local Response Normalization)
ReLU는 양수의 입력값에 비례해 출력값이 되므로 saturation을 방지하기 위해 정규화할 필요가 없는 특성이 있습니다. 하지만 AlexNet 개발자들은 망의 일반화 성능을 돕기 위해 local normalization 할 수 있는 방법을 찾았고, 그 결과로 고안해낸 Local Response Normalization(이하 LRN)을 AlexNet에 적용했습니다.
LRN은 kenel의 한 점에서 공간적으로 같은 위치에 있는 다른 channel의 값들을 square-sum하여 하나의 filter에서만 과도한 활성화 값이 나오는 것을 막는 역할을 합니다.
LRN의 동작은 아래 수식과 같이 작동하게 됩니다.
: kernsl의 i번째 channel에 있는 (x, y)점에서 값
: LRN을 적용한 결과 값
: normalization을 위한 hyper-parameter
AlexNet 발표한 논문에서는 hyper-parameter를 값으로 사용했다고 합니다.
4) Overlapped pooling
CNN Network에서 Pooling layer는 kernel을 요약하기 위해 종종 사용됩니다. 일반적으로 pooling할 때는 strid를 kernel사이즈를 같게 하여 겹쳐지지 않게 수행하는데, AlexNet의 개발자들은 stride를 3, kernel 크기를 2로 설정하여 overlapping max-pooling을 사용했습니다.
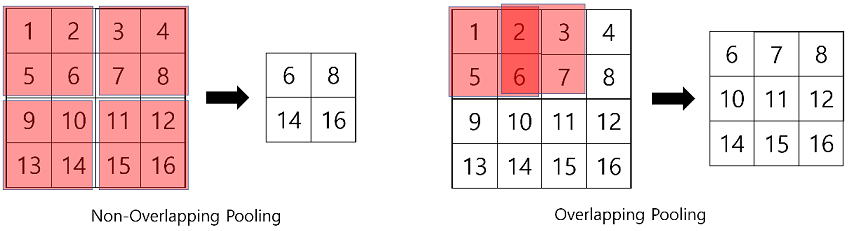
Overlapping pooling의 효과를 확인하기 위해 stride=2, kernel=2를 사용하는 일반적인 pooling layer와 성능 비교한 결과 top-5 error rate는 0.4%, top-1 error rate는 0.3% 낮아지는 효과가 있었다고 합니다.
Overfitting 줄이기
AlexNet의 free-parameter 개수는 6,000만개 수준의 매우 큰 네트워크 입니다. 이렇게 많은 free-parameter로 인해 overfitting에 빠지기 쉬웠고, 이를 피하기 위해 AlexNet 개발자들은 두 가지 방법을 사용합니다.
1) Data Augmentation
Overfitting 문제를 해결하는 가장 대표적인 방법은 학습에 사용할 데이터 수를 늘리는 것 입니다. AlexNet에서는 데이터를 늘리기 위해 두 가지 방법을 적용했습니다.
첫 번째 방법은 ILSVRC의 256x256 크기의 원래 이미지로 부터 224x224 크기의 이미지를 무작위로 추출하는 것 입니다. 이 방법으로 1장의 이미지로부터 수평반전을 포함하여 총 2,048장의 다른 영상을 추출했다고 합니다.
Test할 때는 원본 이미지로 부터 상하좌우 및 중앙의 5개의 224x224 이미지를 추출하고 반전된 이미지 5개를 포함한 10개의 이미지로부터 softmax 출력을 평균하는 방법을 사용했다고 합니다.
두 번째 방법은 학습 이미지에서 RGB채널의 값을 변화시키는 방법을 사용했다고 합니다.
원본 이미지에 대해 주성분 분석(PCA)를 수행하였으며, 평균 0, 표준편자 0.1을 갖는 랜덤 변수를 곱하고 그 결과를 원본 이미지에 더해주는 방식으로 컬러 채널의 값을 바꾸어 데이터의 수를 늘렸다고 합니다.
논문에서는 Data augmentation 을 통하여 top-1 error rate를 1% 넘게 줄였다고 합니다.
2) Dropout
AlexNet은 Overfitting문제를 해결하기 위한 두 번째 방법으로 Dropout을 사용했습니다. Dropout은 학습할 때 일부 뉴런을 생략하는 방법으로 Overfitting을 해결하기 위해 사용되는 방법 중 하나입니다.
AlexNet에서는 첫 번째와 두 번째 FC layer에 대해 50%의 확률로 hidden 뉴런을 생략하며(probability를 0.5로 셋팅) 학습을 진행했다고 합니다.
결과
AlexNet 우선 ILSVRC-2010 테스트 데이터를 기준으로 성능을 평가됐습니다. ILSVRC-2010 DB에서는 Top-1 error rate 37.5%, Top-5 error rate 17.0%를 달성하여 대회에서 우승한 모델보다 월등히 좋은 성능을 보여주었을 뿐만 아니라 AlexNet 논문을 발표하던 당시까지 발표된 방법 중 가장 좋았던 SIFT feature에 Fisher Vector로 학습한 방법론 보다도 좋은 성능을 보여주었습니다.
ILSVRC-2012에 참가했을 때는 Top-5 error rate 16.4%의 성능을 보여 1위를 차지했습니다.
또한 논문에서 몇가지 추가 실험을 진행하였는데, 2개의 Conv layer를 2011년 가을에 발표된 ImageNet 데이터로 pre-train한 뒤 AlexNet을 이어 붙여 결과를 냈을 때 15.3%까지 error rate가 내려간것을 확인할 수 있었습니다. 이는 2위를 차지한 모델의 26.2%와 비교하면 매우 좋은 성능임을 알 수 있습니다.
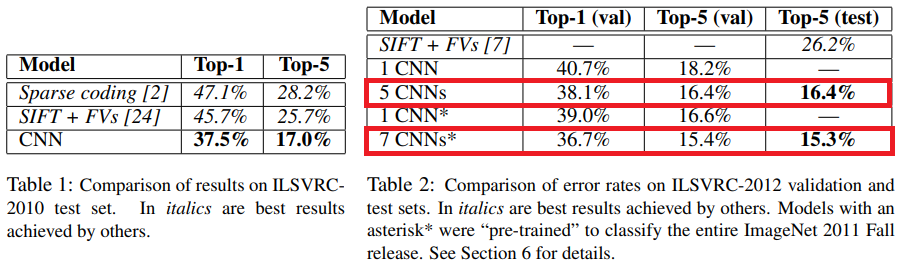
마지막으로 상세한 결과를 확인했했습니다.
아래 그림과 같이 8개의 이미지로 확인했을 때 이미지가 중앙에 위치해 있지 않더라도 정확하게 class를 구분해 내며(좌측 상단), leopard의 경우도 상위 5개의 label들이 거의 비슷한 형태를 갖기 때문에 어느정도 이유가 있는 결과라고 판단할 수 있습니다. 아래의 첫 번째와 세 번째 이미지인 cherry나 grille의 경우 초점을 어디에 맞추느냐에 따라 충분히 나올 수 있는 답이기 때문에 완전한 오류라고 볼 수는 없습니다.

끝으로 network의 학습된 시각적 정보가 얼마나 유용한지 증명하기 위해 두 번째 FC layer의 feature vector의 유사도를 확인해보았습니다. Test 데이터에서 5개 이미지를 선정하고, 학습 데이터에서 가장 유사한 6개의 이미지를 선택한 결과 아래 이미지와 같습니다.

마무리
AlexNet은 CNN Network를 활용해서 훌륭한 결과를 얻을 수 있음을 보여주었는데, 특히 SIFT와 같이 사람이 설계한 feature가 아닌 학습을 통해 선택된 feature를 활용해 기존보다 좋은 성능을 보여주었다는 점에서 매우 큰 의미가 있는것 같습니다.
참고자료
ImageNet Classification with Deep Convolutional Neural Networks
라온피플 블로그
Curaai00님의 블로그

좋은글 감사합니다!!