
💖대망의 첫 캐글 도전!!💖

첫 시도치고 성적이 나쁘지 않아 기록으로 남긴다.
물론 80% 이상 달성한 분들도 많지만 내가 한 방법을 소개해보고자 한다.
전체 코드는 github 레포지토리에서 확인할 수 있다.
핵심만 다루고자 일부 셀은 생략한다.
1. 시작
1) 데이터셋 import
from google.colab import drive
drive.mount('/content/gdrive')
import pandas as pd
import numpy as np
TITANIC_PATH = '/content/gdrive/My Drive/handson/datasets/titanic/'
def load_titanic_data(filename, titanic_path=TITANIC_PATH):
csv_path = os.path.join(titanic_path, filename)
return pd.read_csv(csv_path)import os
train_data = load_titanic_data("train.csv")
test_data = load_titanic_data("test.csv")2) 데이터셋 자료구조 조사
train_data.head()
train_data.info()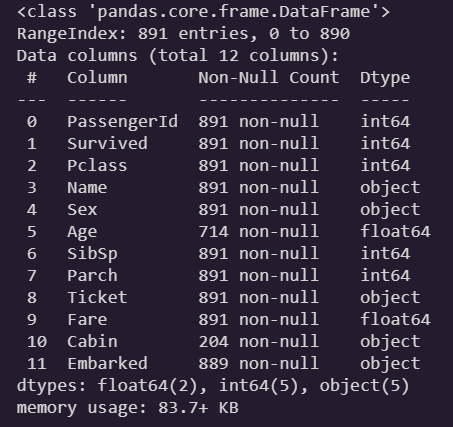
-
Age, Cabin, Emarked에 결측치가 존재한다. -
Cabin은 결측치가 과반수 이상이라 유의미한 데이터를 얻기는 어려워보인다. 이후 drop하는게 낫다고 생각된다. -
Age의 경우는 데이터 분석을 해보고, 생존율과 유의미한 상관관계가 있다면 중앙값 정도로 결측치 처리를 해주면 되겠다. -
Embarked는 결측치 수가 적어 어떻게 채워도 결과에 거의 영향을 끼치지 않을 것이다. 어차피 pandas의 get_dummies로 NaN 값을 채워는 줄테니 크게 신경쓰지 않아도 되겠다.
train_data.describe()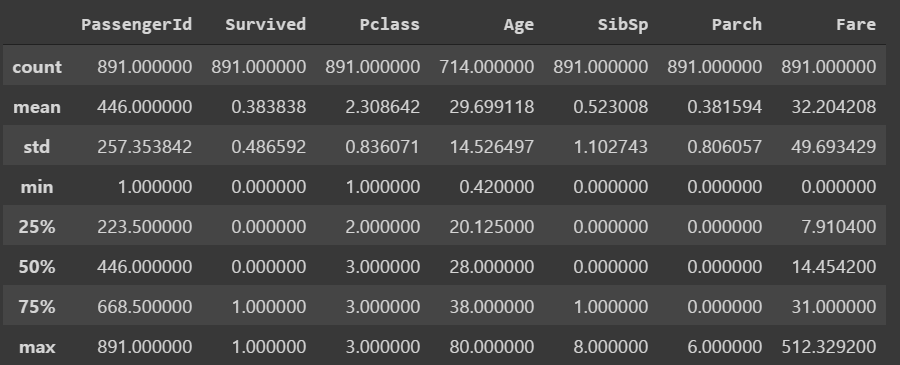
- 생존/비생존 비율은 꽤 균형있게 나누어져 있다.
train_data['Survived'].value_counts()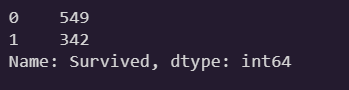
train_data['Sex'].value_counts()
train_data['Pclass'].value_counts()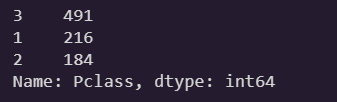
Pclass는 정수타입이지만 사실 범주형 feature임이 확인되었다.
train_data['Embarked'].value_counts()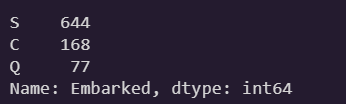
2. EDA
1) 상관관계 분석
eda = train_data.copy()
eda['Sex_code'] = eda['Sex'].astype('category').cat.codes
eda['Embarked'].fillna('S', inplace=True)
eda['Embarked_code'] = eda['Embarked'].astype('category').cat.codes-
데이터 분석 과정에서만 일시적으로 변형할 feature도 있기 때문에 탐색 과정에서만 쓸 복제 데이터셋을 하나 두었다.
-
범주형 feature의 선형성을 확인하기 위해, 각각 수치화한 열을 추가해준다.
-
Embarked의 결측치는 처리해주지 않으면 수치화 후에 카테고리 코드가 4개 생겨버리기 때문에, 일단 최빈값으로 채워준다.
corr_matrix = eda.corr()
corr_matrix["Survived"].sort_values(ascending=False)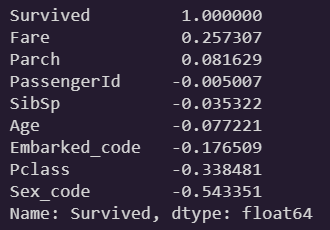
-
Fare와 생존율은 뚜렷한 양의 상관관계를 보인다. -
Sex와 생존율이 매우 강한 음의 상관관계를 보인다. -
Pclass는 강한 음의 상관관계를 보인다. 물론 범주형 feature긴 하나, 연속형처럼 순서가 있기 때문에 여기선 의미부여해도 좋다. -
PassengerId는 그저 승객의 고유번호일 뿐이다. 생존율과의 합리적인 상관관계가 거의 없으니 이후에 drop한다. -
그럼 연속형 중에선 남는 것이
Sibsp, Parch, Age인데... -
더 요리해보고, feature engineering 을 통해 최대한 유의미한 데이터를 만들어보자. 분석 과정에서 타당한 관계를 찾지 못하면 drop할 수도 있다.
상관계수 분석 하나로 상당히 많은 insight를 얻었다!😃
결론만 정리해보자
결론
- 요금을 많이 지불한 승객일수록 생존율이 높다.
- 탑승 클래스가 낮을 수록 생존율이 높다.
- 여자일수록 생존율이 높다.
- 선착장별 생존율은 C > Q > S 순으로 높다.
2) 시각화 분석
여기선 SibSp, Parch, Age와 생존율의 관계에 대한 분석만 보겠다.
(그 외 시각화 내용은 github 레포지토리를 참고 바란다.)
일단 아래 추측을 가지고 접근했다.
가능한 추측
- 일행이 많을 수록 사망률이 높을 것이다.
- 나이가 어릴 수록 생존율이 높을 것이다
import seaborn as sns
sns.set()
sns.kdeplot(eda[eda['Survived'] == 1]['Age'])
sns.kdeplot(eda[eda['Survived'] == 0]['Age'])
plt.legend(['Survived', 'Dead'])
plt.show()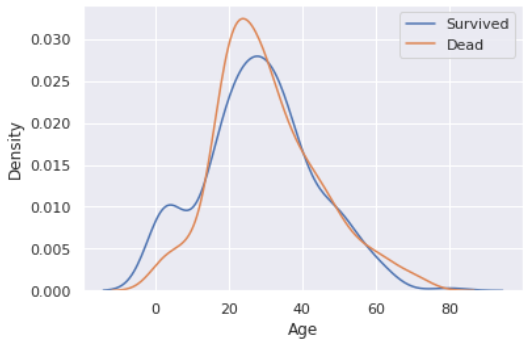
-
확실히 나이가 적을 수록 생존율이 높다. 특히 약 15세 정도.. 이하인 어린아이의 생존율이 눈에 띈다.
-
즉, Age 컬럼은 drop하면 안된다. 단 15 단위로 binning 하면 더 좋을 것 같다. (데이터셋 수가 적은 편이기에 생존자 특성을 어느 정도 일반화해줄 필요가 있다)
sns.kdeplot(eda[eda['Survived'] == 1]['SibSp'])
sns.kdeplot(eda[eda['Survived'] == 0]['SibSp'])
plt.legend(['Survived', 'Dead'])
plt.show()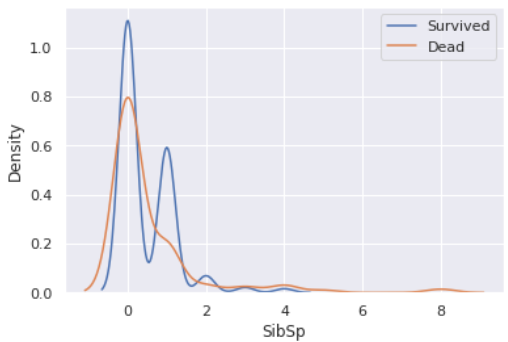
sns.kdeplot(eda[eda['Survived'] == 1]['Parch'])
sns.kdeplot(eda[eda['Survived'] == 0]['Parch'])
plt.legend(['Survived', 'Dead'])
plt.show()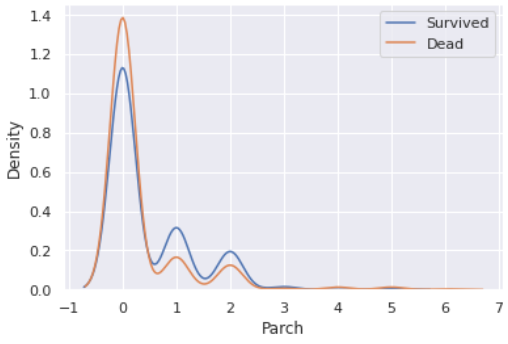
- 각각으로는 조금 뭔갈 잡아내기 힘들다. 한번 둘을 합쳐서 보겠다.
eda['family_size'] = eda['SibSp'] + eda['Parch']
sns.kdeplot(eda[eda['Survived'] == 1]['family_size'])
sns.kdeplot(eda[eda['Survived'] == 0]['family_size'])
plt.legend(['Survived', 'Dead'])
plt.show()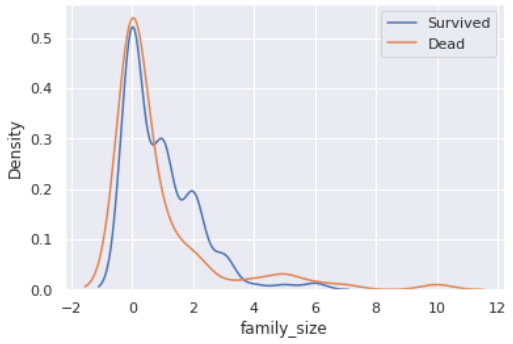
- 가족 수가 너무 적어도, 4명 이상으로 커져도 생존률이 낮아진다.
- 한번 범위를 자세히 보겠다.
eda[['family_size', 'Survived']].groupby(['family_size'], as_index=True).mean().sort_values(by='Survived', ascending=False).plot.bar()
plt.show()
-
정확히 1~3명 선에서 높은 생존율을 보인다. 뭐라고 해야하지.. 핵가족?
-
그렇다고 핵가족과 아닌 경우를 이진 구분만 하기엔, 혼자인 경우는 좀 유의미하다. 뭉뚱그리기엔 어느정도 생존율이 있다.
(5나 6같은 경우는 해당 데이터가 매우 적으므로 대표성이 없다고 보았다.) -
혼자, 핵가족, 대가족으로 나누어 feature enginnering을 해볼 수 있겠다.
정리
Agebinning- 혼자, 핵가족, 대가족인 경우로 구분한 feature 생성
3. 특성 공학 & 전처리
1) 불필요 컬럼 drop
train = train_data.drop(['Cabin', 'Ticket', 'PassengerId'], axis=1)
train.head()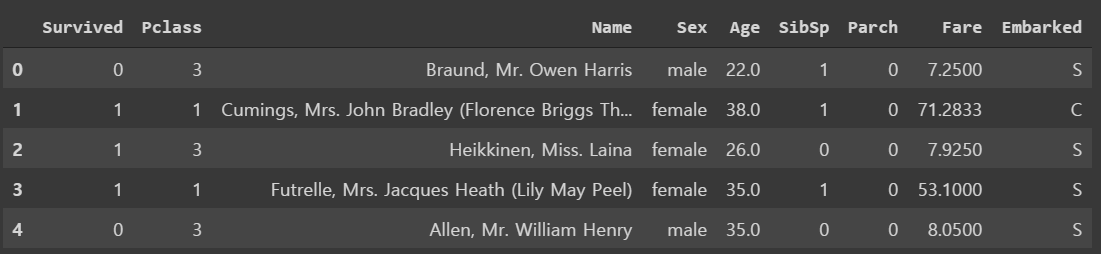
- 물론 drop 할 컬럼은 아직 더 있다. (
Name등) - 다만 feature enginnering을 하기 위해선 필요하기 때문에 이후에 마저 drop한다.
2) 특성 공학 - Title
Name 컬럼이 그닥 생존율과 큰 상관이 없긴 하지만, Mr, Miss 등의 글자로 끊어서 통계를 내볼 수 있다.
train['Title'] = train['Name'].str.extract('([A-Za-z]+)\.', expand=False)
train['Title'].value_counts()
- 10 이상 분포하고 있는 이름들 말고는 전부
Other필드로 묶기로 하자. - 또한 소수의 필드들 중 통합할 수 있는건 같은 맥락의 이름으로 묶어주자.
train['Title'] = train['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Other')
train['Title'] = train['Title'].replace('Mlle', 'Miss').replace('Ms', 'Miss').replace('Mme', 'Mrs')
train = train.drop(['Name'], axis=1)train[['Title', 'Survived']].groupby(['Title'], as_index=True).mean().plot.bar()
plt.show()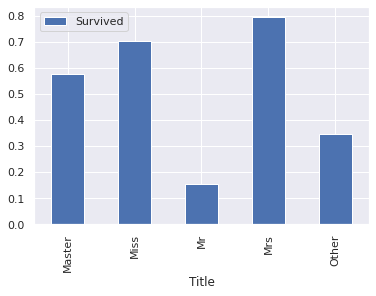
-
Mr 가 확연히 낮다.
-
남성보다 여성의 생존율의 높다는게 이
title필드로 다시 한번 반증된 셈이다. -
그리고 Master 의 생존율이 높은데, 데이터가 약 40개 정도로 무시할 수 없는 양이다.
결론은 title 을 학습에 포함해야 한다!
3) 특성 공학 - Alone, Bigfamily
train['family_size'] = train['SibSp'] + train['Parch']
train['Alone'] = 0
train.loc[train['family_size']==0, 'Alone'] = 1
train['Bigfamily'] = 0
train.loc[train['family_size']>3, 'Bigfamily'] = 1train.corr()['Survived']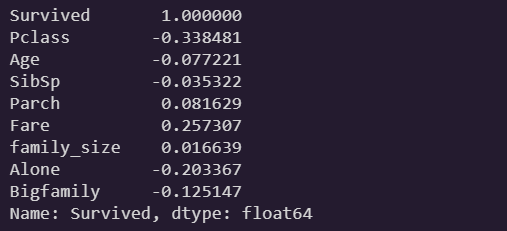
- 두 feature 모두 상관관계 계수가 0.1 이상이다! 뚜렷한 음의 상관관계를 보인다.
시각화를 통해 직접 확인해보자.
sns.factorplot(x='Alone', y='Survived', data=train)
plt.show()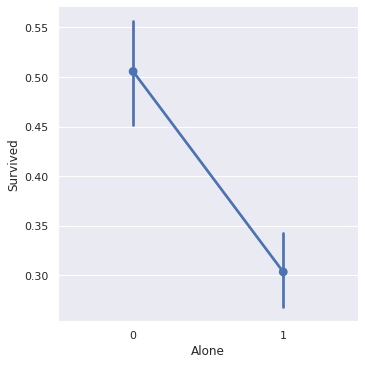
sns.factorplot(x='Bigfamily', y='Survived', data=train)
plt.show()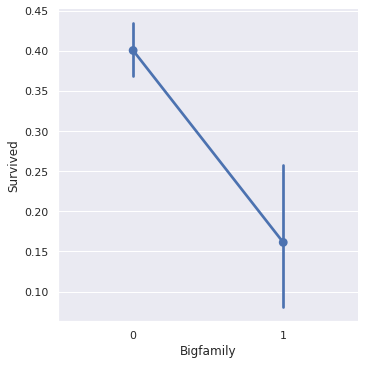
- 혼자일 경우, 대가족일 경우 모두 생존율이 확연히 낮다.
두 feature 모두 학습에 반영하자.
4) 결측치 처리
train = pd.get_dummies(train, columns=['Sex', 'Embarked', 'Pclass', 'Title'])
train.info()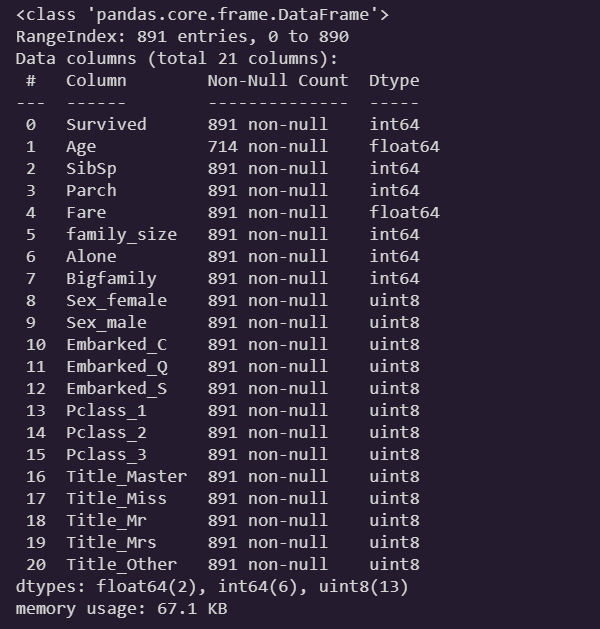
-
Age컬럼만 처리해주면 된다. -
평균값으로 하면 혹시 모를 이상치에 영향을 받는다.
-
중앙값으로 채우자
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
X = imputer.fit_transform(train)
imputer.statistics_
train = pd.DataFrame(X, columns=train.columns, index=train.index)
train.info()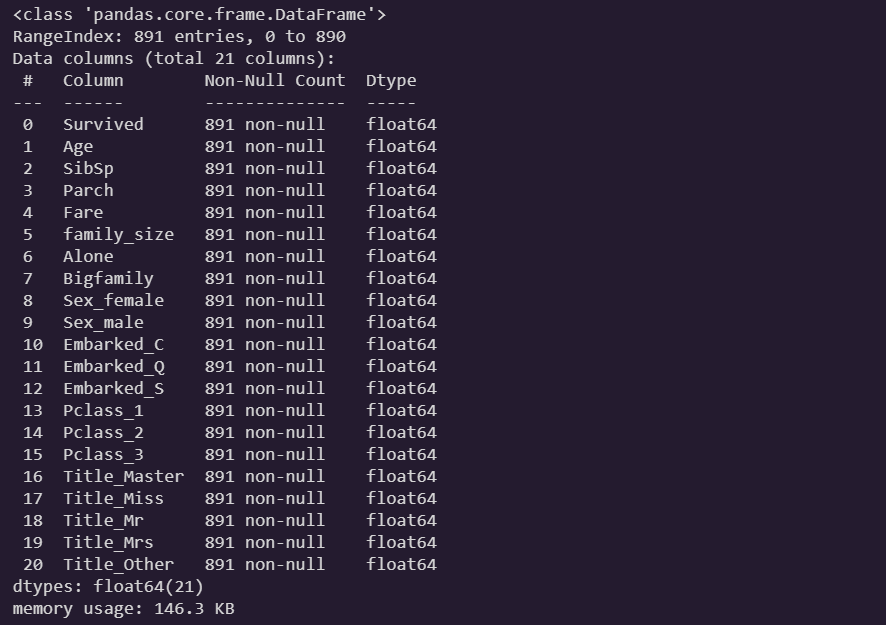
- 결측치 처리가 끝났다.
이제 나이대 범주화를 할 수 있다.
5) 특성 공학 - AgeBucket
train["AgeBucket"] = train["Age"] // 15 * 15
train[["AgeBucket", "Survived"]].groupby(["AgeBucket"]).mean()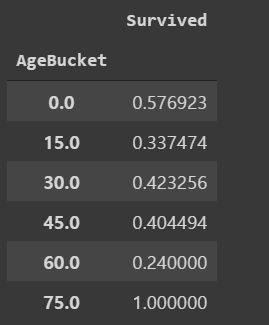
sns.factorplot(x='AgeBucket', y='Survived', data=train)
plt.show()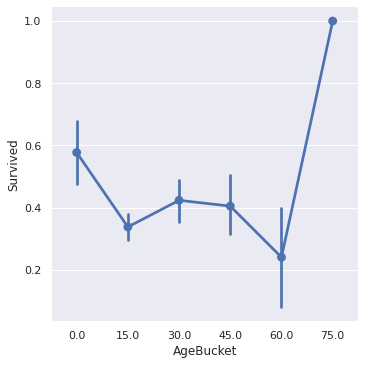
6) 필드 2차 drop
train = train.drop(['SibSp', 'Parch', 'family_size', 'Age'], axis=1)
train.head()
train.isnull().sum()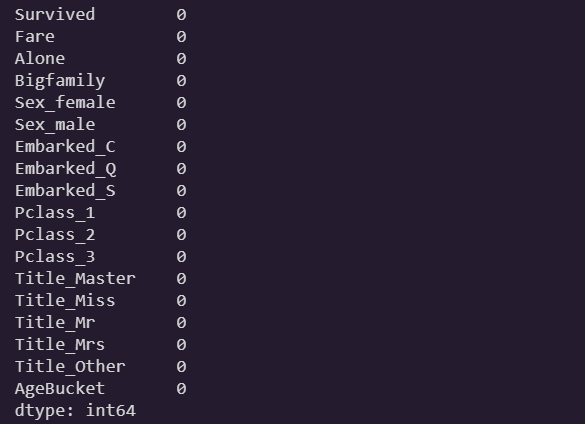
6) X-Y split
y_train = train['Survived']
x_train = train.drop(['Survived'], axis=1)7) 스케일링
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
x_train = scaler.fit_transform(x_train)
x_train.std()
- 이제 학습시킬 준비가 끝났다!
4. 모델별 성능평가
이제 모델 선정을 위해 후보 모델의 성능평가를 해볼 차례!
단순 accuracy 비교는 클래스별 분포가 같을 때나 유용하다.
AUC (Area Under the Curve) 성능지표 테크닉을 이용하자.
SVM, Random Forest 분류기의 성능을 비교 분석해본다.
AUC Score
def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0,1], [0,1], 'k--')
plt.grid(True)
plt.xlim([0,1])
plt.ylim([0,1])
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score, cross_val_predict
forest_clf = RandomForestClassifier(n_estimators=100, random_state=42)
forest_scores = cross_val_predict(forest_clf, x_train, y_train, cv=10, method="predict_proba")from sklearn.svm import SVC
svm_clf = SVC(gamma="auto")
svm_scores = cross_val_predict(svm_clf, x_train, y_train, cv=10, method="decision_function")from sklearn.metrics import roc_curve
fpr_forest, tpr_forest, thresholds, = roc_curve(y_train, forest_scores[:,1])
fpr_svm, tpr_svm, thresholds, = roc_curve(y_train, svm_scores)
plt.plot(fpr_svm, tpr_svm, "b:", label="SVM")
plt.plot(fpr_forest, tpr_forest, "r:", label="Random Forest")
plt.legend()
plt.show()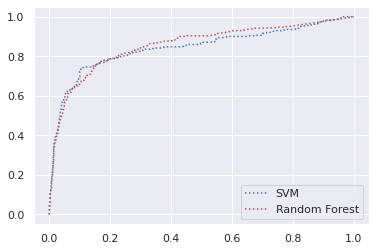
roc_auc_score(y_train, forest_scores[:,1]), roc_auc_score(y_train, svm_scores)
Random Forest 쪽이 더 AUC 스코어가 높다.
즉 상대적으로 더 완전한 모델이라 판단하여, Random Forest를 채택하였다.
5. 파이프라인 제작
모델까지 선정했으니 바로 학습을 진행해도 물론 괜찮다.
그러나, 현재 테스트셋은 전처리가 하나도 되어있지 않다.
그냥 훈련셋 전처리할 때 같이 해주면 되지 않나..? 할 수도 있는데,
좀 더 아름답게 해보기 위해 파이프라인 으로 모든 과정을 함축해서 전처리해보자.
1) 특성 삭제기
from sklearn.base import BaseEstimator, TransformerMixin
class Dropper(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X.drop(self.attribute_names, axis=1)2) 특성 결합기
from sklearn.preprocessing import OneHotEncoder
class CombineAttributeAdder(BaseEstimator, TransformerMixin):
def __init__(self):
pass
def fit(self, X, y=None):
return self
def transform(self, X):
X['family_size'] = X['SibSp'] + X['Parch']
X['Alone'] = 0
X.loc[X['family_size']==0, 'Alone'] = 1
X['Bigfamily'] = 0
X.loc[X['family_size']>3, 'Bigfamily'] = 1
X["AgeBucket"] = X["Age"] // 15 * 15
X['Title'] = X['Name'].str.extract('([A-Za-z]+)\.', expand=False)
X['Title'] = X['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Other')
X['Title'] = X['Title'].replace('Mlle', 'Miss').replace('Ms', 'Miss').replace('Mme', 'Mrs')
return X3) encoder
class encode(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return pd.get_dummies(X, columns=self.attribute_names)-
OneHotEncoder를 쓰면 별도로 클래스를 만들 필요가 없다! -
다만 get_dummies와 같은 목적의 인코더인데도 엄연히 다르기 때문에,
-
기존에 썼던 방식인 get_dummies로 인코딩하기 위해 따로 클래스를 만들었다.
4) 최종 파이프라인
from sklearn.pipeline import Pipeline
full_pipeline = Pipeline([
('dropper_1', Dropper(['Cabin', 'Ticket', 'PassengerId'])),
('attribs_adder', CombineAttributeAdder()),
('dropper_2', Dropper(['SibSp', 'Parch', 'family_size', 'Age', 'Name'])),
("encode", encode(['Sex', 'Embarked', 'Pclass', 'Title'])),
("imputer", SimpleImputer(strategy="median")),
("scaler", RobustScaler())
])이제 다른 데이터셋을 받아서 또 전처리 하더라도, 이 파이프라인만 가동시켜주면 한번에 전처리가 스르륵 된다.
처음부터 이렇게 객체화하면서 전처리하기엔 이 단계가 성능 향상에 도움이 되는가에 대한 확신이 부족했다. 아직 많이 미숙하다...
6. 학습
test = full_pipeline.fit_transform(test_data)
test.shape
1) 최적 하이퍼파라미터 탐색
from sklearn.model_selection import RandomizedSearchCV
params = {
'n_estimators': list(range(10,100,10)),
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth' : [4,5,6,7,8],
'criterion' :['gini', 'entropy']
}
rfc = RandomForestClassifier(random_state=42)
rand_search = RandomizedSearchCV(estimator=rfc, param_distributions=params, cv=5)
rand_search.fit(x_train, y_train)
2) 학습
y_train = train_data['Survived']
x_train = train_data.drop(['Survived'], axis=1)
x_train = full_pipeline.fit_transform(x_train)model = rand_search.best_estimator_
model.fit(x_train, y_train)
model = rand_search.best_estimator_
cross_val_score(model, x_train, y_train, cv=5).mean()
이 로직을 가지고 제출해보면 약 78%가 나온다.
(전체 코드는 github에서 참고 바란다.)
사람들이 왜 캐글은 타이타닉부터 해보라는건지 알겠다.
데이터셋이 너무 복잡하지도 않되, 분석할 맥락도 대양하다.
상당히 많은 것을 얻었다! 😃😃
