8. 데이터 시각화
pairplot으로 상관관계 확인하기
kind ➡ scatter, kde, hist, reg
# [인구수, CCTV]와 [살인, 강도]의 상관관계
def drawGraph():
sns.pairplot(
data=crime_anal_norm,
x_vars=["인구수", "CCTV"],
y_vars=["살인", "강도"],
kind="reg",
height=4
)
plt.show()
drawGraph()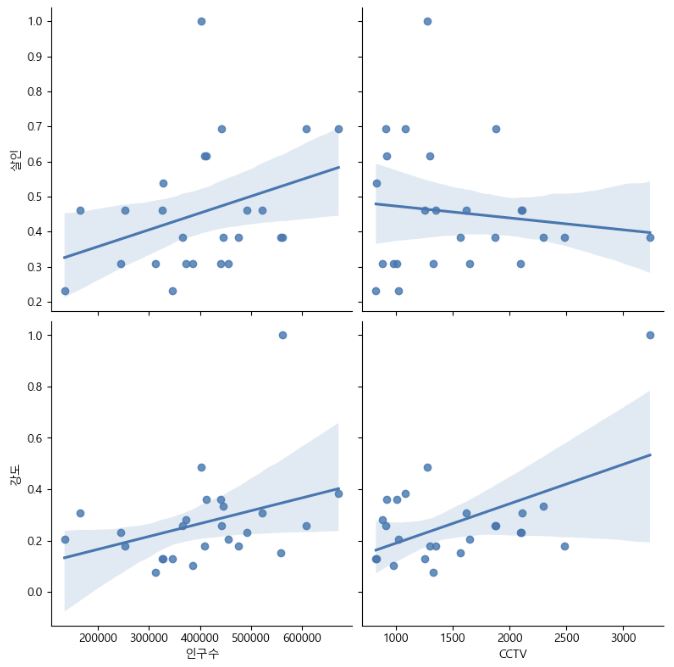
CCTV-강도 데이터의 관계 : 강도 사건이 많이 발생해서 CCTV를 늘렸다고 보는 게 더 적절하고, 이상치가 없으면 더 완만해질 것이다.
heatmap - 범죄 비율, 범죄 검거 비율
def drawGraph():
# 데이터 프레임 생성
target_col = ["강간", "강도", "살인", "절도", "폭력", "범죄"]
crime_anal_norm_sort = crime_anal_norm.sort_values(by="범죄", ascending=False)
# 그래프 설정
plt.figure(figsize=(10, 10))
sns.heatmap(
data=crime_anal_norm_sort[target_col],
annot=True,
fmt="f",
linewidths=0.5, # 박스 간 간격 설정
cmap="RdPu"
)
plt.title("범죄 비율(정규화된 발생 건수의 합으로 정렬)")
plt.show()
drawGraph()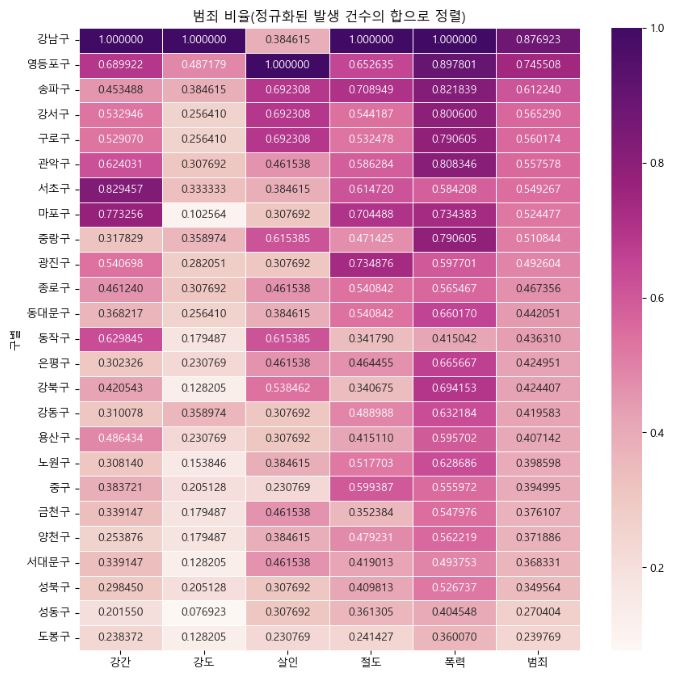
9. 지도 시각화
서울시 구별 경계선의 위도, 경도 json 파일이 필요하다.
인구 대비 범죄 발생 건수
tmp_criminal = crime_anal_norm["범죄"] / crime_anal_norm["인구수"]
tiles = "https://tiles.stadiamaps.com/tiles/stamen_toner/{z}/{x}/{y}{r}.png?api_key=인증키"
attr = "toner"
my_map = folium.Map(
location=[37.5502, 126.982],
zoom_start=11,
tiles=tiles,
attr=attr
)
folium.Choropleth(
geo_data=geo_str, # 우리나라 경계선 좌표값이 담긴 데이터
data=tmp_criminal,
columns=[crime_anal_norm.index, tmp_criminal],
key_on="feature.id",
fill_color="PuRd",
fill_opacity=0.7,
line_opacity=0.2,
legend_name="인구 대비 범죄 발생 건수"
).add_to(my_map)
my_map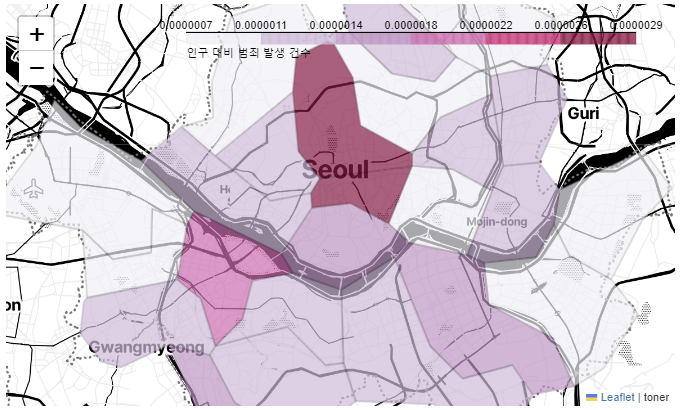
# 5대 범죄 발생 건수
folium.Choropleth(
geo_data=geo_str, # 우리나라 경계선 좌표값이 담긴 데이터
data=crime_anal_norm["범죄"],
columns=[crime_anal_norm.index, crime_anal_norm["범죄"]],
key_on="feature.id",
fill_color="PuRd",
fill_opacity=0.7,
line_opacity=0.2,
).add_to(my_map)
# 경찰서 위치 마커 표시
for idx, row in crime_anal_station.iterrows():
folium.Marker(
location=[row["lat"], row["lng"]]
).add_to(my_map)
# 5대 범죄 검거율
for idx, row in crime_anal_station.iterrows():
folium.CircleMarker(
location=[row["lat"], row["lng"]],
radius=row["검거"] * 50,
popup=row["구분"] + ":" + "%.2f" % row["검거"],
color="#3186cc",
fill=True,
fill_color="#3186cc"
).add_to(my_map)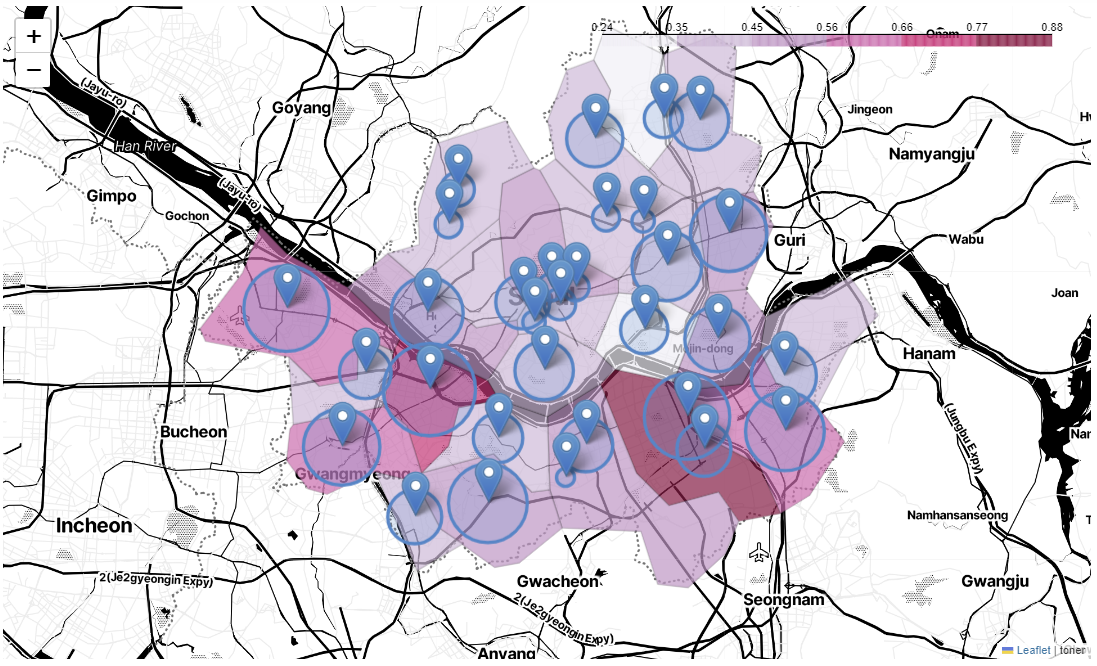
10. 추가 검증 : 서울시 범죄 현황 장소별 분석
데이터 정리
crime_loc = crime_loc_raw.pivot_table(
crime_loc_raw,
index="장소",
columns="범죄명",
aggfunc=[np.sum]
)
crime_loc.columns = crime_loc.columns.droplevel([0, 1])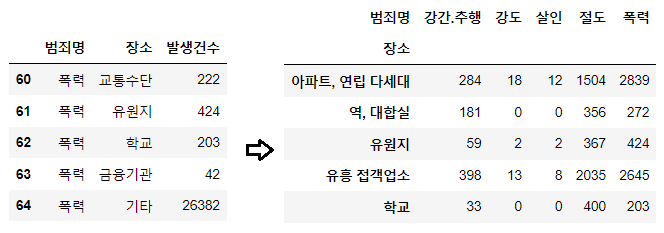
# 정규화
col = ['살인', '강도', '강간.추행', '절도', '폭력']
crime_loc_norm = crime_loc / crime_loc.max()
# "종합" 컬럼 추가
crime_loc_norm["종합"] = np.mean(crime_loc_norm, axis=1)heatmap 그리기
# 데이터 정렬
crime_anal_norm_sort = crime_loc_norm.sort_values("종합", ascending=False)
# 시각화
def drawGraph():
plt.figure(figsize=(10, 10))
sns.heatmap(
crime_anal_norm_sort,
annot=True,
fmt="f",
linewidths=0.5,
cmap="RdPu"
)
plt.title("범죄 발생 장소")
plt.show()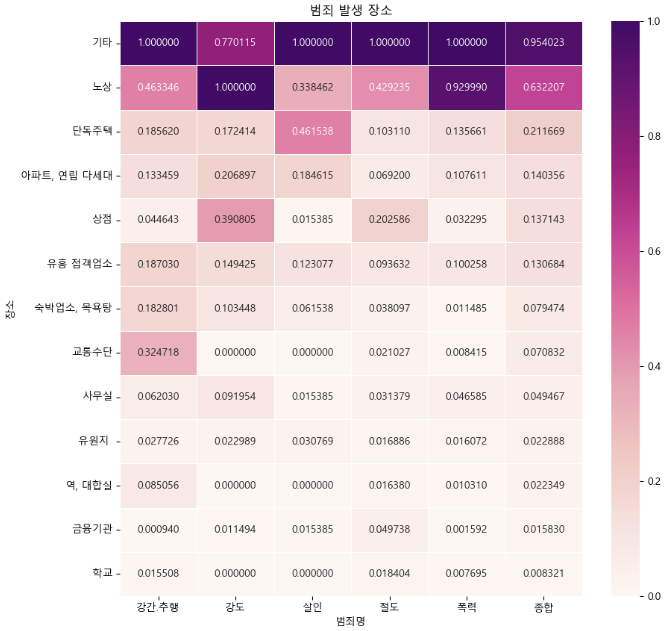
🚗
두 번째 미니 프로젝트가 끝났다.
새로운 기능을 연달아 마주하니 조금 어렵게 느껴지기도 하지만, 알아가는 즐거움이 있다.
시간이 여유로울 때 최신 데이터를 가지고 다시 해보고 싶다.🤹♂️
