논문리뷰
1.[논문리뷰] LIMA: Less Is More for Alignment
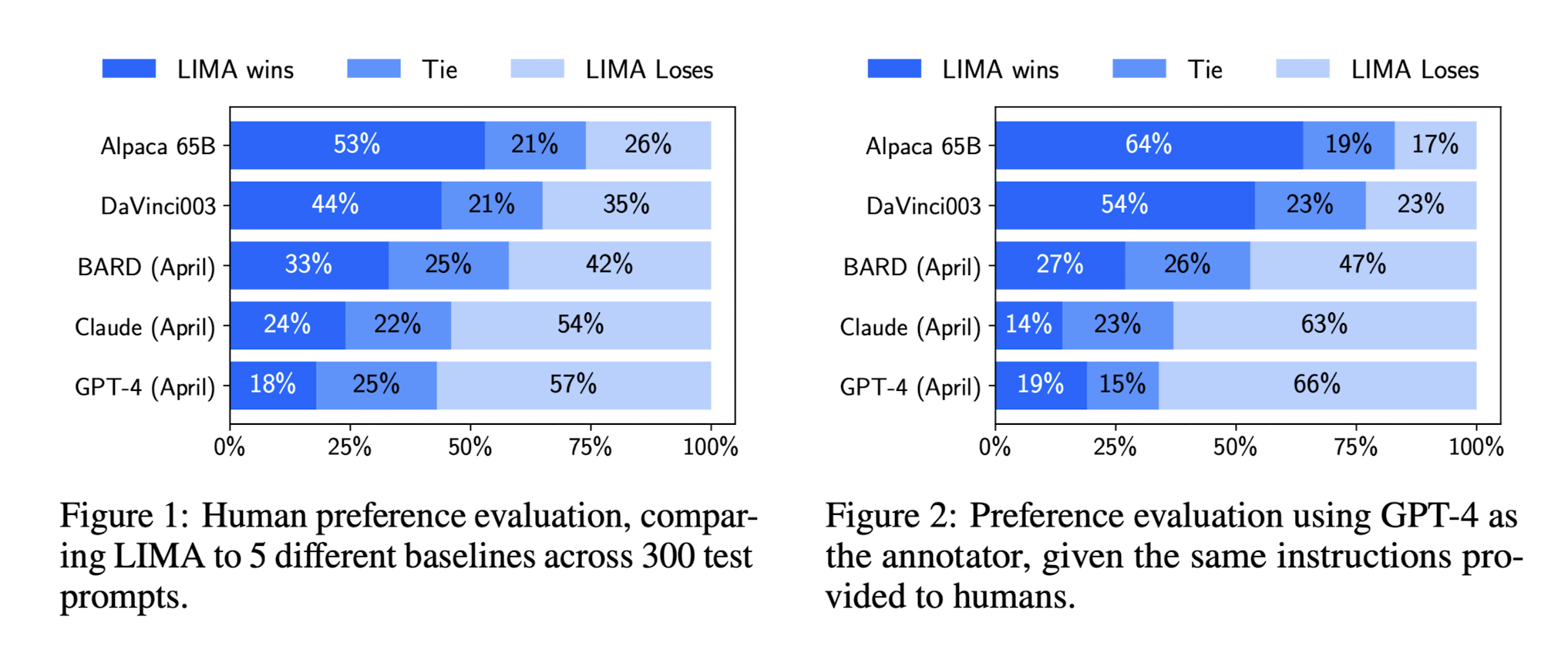
LIMA: Less Is More for Alignment Paper Link PDF Link 요약 LLM들은 unsupervised pretraining을 우선적으로 거치고 instruction이나 RL 등을 통해서 fine-tuning 했었다. 근데 LIMA는
2023년 5월 28일
2.[논문리뷰] GPT-3: Language Models are Few-shot Learners

GPT-3: Language Models are Few-shot Learners Abstract task-agnostic model 현재 아키텍쳐 자체는 task-agnostic (특별히 어떤 구체적인 태스크를 수행하라고 지시되지 않음) 하지만 fine-tunin
2023년 5월 31일
3.[논문 리뷰] GPT2: Language Models are Unsupervised Multitask Learners
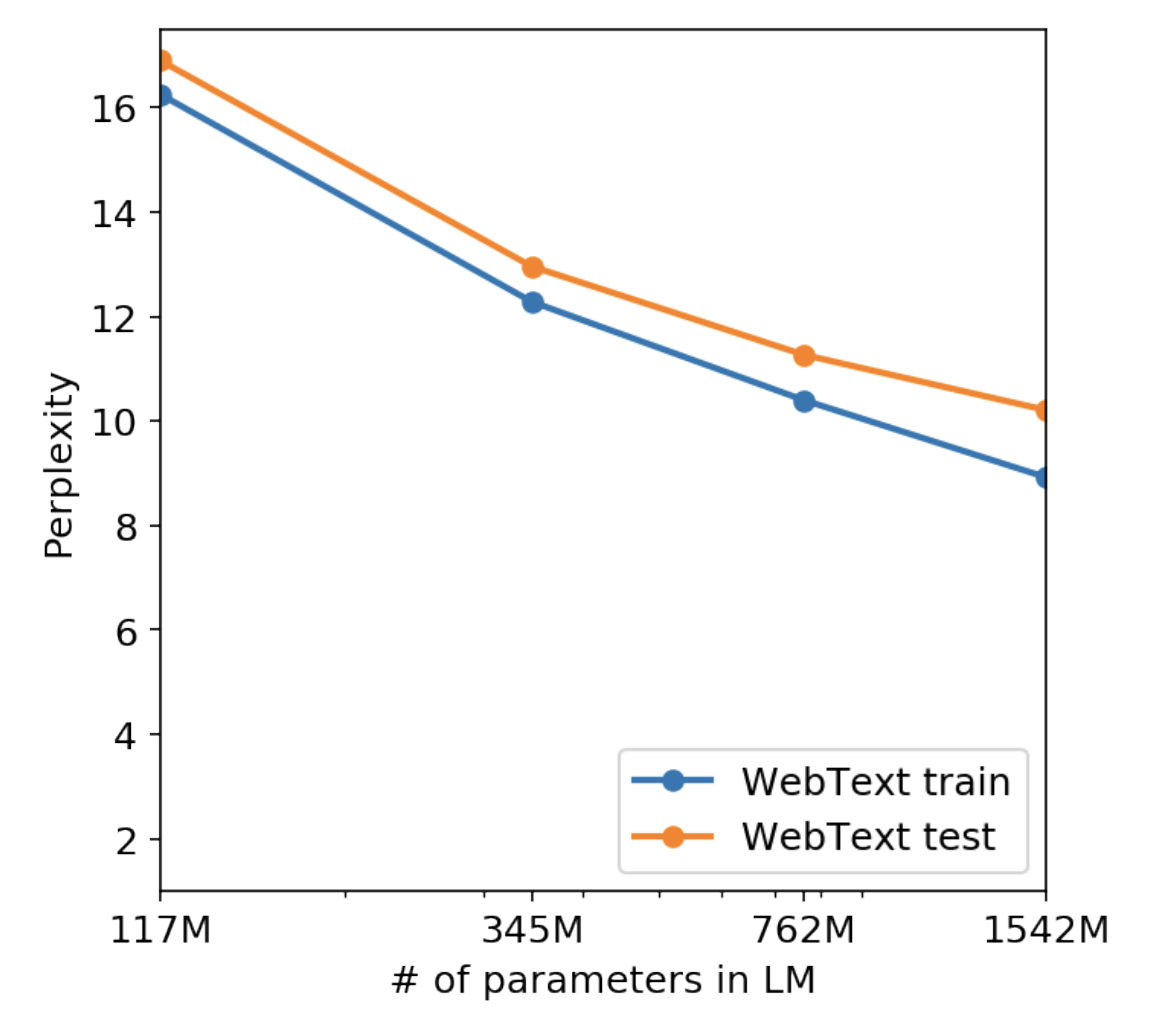
What NLPs are nownarrow expertsbrittle and sensitive to the data distribution or trivial changesSingle task training on single task datasetstill super
2023년 5월 25일
4.[논문리뷰] RWKV: Reinventing RNNs for the Transformer Era

RWKV: Reinventing RNNs for the Transformer Era Problem posing Limitations of Transformer Transformer는 NLP에서 엄청난 파급력을 지녔지만 memory와 time complexity 측
2023년 6월 5일