GPT-3: Language Models are Few-shot Learners
Abstract
task-agnostic model
현재 아키텍쳐 자체는 task-agnostic (특별히 어떤 구체적인 태스크를 수행하라고 지시되지 않음) 하지만 fine-tuning을 시도하는 데이터셋은 아직 task-specific (구체적인 태스크를 위해 만들어진 데이터셋) 하다. 이 논문에서는 이 점을 사람과 가장 차별화되는 부분이라고 강조하고 여러 번 언급하고 있다. 사람 같은 경우에는 예시가 몇개만 주어지더라도 (few-shot) 다음 예시에 대한 정답을 쉽게 추론할 수 있다.
'@' 연산을 새롭게 정의하는데
2 @ 3 = 7,
3 @ 5 = 16 이라면
6 @ 2 = ?사람은 위와 같은 질문을 주었을때 a @ b = ab + 1이라는 것을 단 몇개의 예시만 가지고 generalize 할 수 있으며, 이를 통해 다음 예시에 대한 답을 추론해낼 수 있다. 하지만 GPT 모델에게 던져주는 데이터셋이 task-specific하다면 이 같은 행동을 하기가 더욱 힘들어진다.
scaling up models
OpenAI에서는 GPT-3 모델을 175B 까지 확장해 훈련시킴으로써, 모델의 크기가 커질수록 few-shot performance가 좋아지며 generalize도 잘하고 단순히 어떤 task에 few-shot을 주는 것만으로도 그 task-specific 하게 만들어진 SOTA 모델도 이기는 경우가 있었다고 한다.
limitations
다만 한계점은 당연히 존재한다. GPT-3는 web corpora를 수집해서 학습하였기 때문에 몇몇 task에 대해서는 few-shot learning을 어려워하는 경우가 존재하였다.
Introduction
Three big limitations
첫번째로, 새로운 모든 태스크에 대해 라벨링된 큰 데이터셋을 필요로 하는 것이 오히려 모델의 적용성(the applicability of language models)을 저해한다.
새로운 모든 태스크에 대해 큰 데이터셋을 구축하는 것 그 자체로도 쉽지 않지만, 그렇게 만든 데이터셋으로 모델을 학습시키더라도 모델이 어떤 태스크를 적용시킬지 혼동하기 때문에 적용성 관점에서도 악영향을 미친다.
두번째로, 훈련 분포(training distribution)의 범위가 좁아질수록, 모델의 표현력(expressiveness)과 함께 모델이 훈련 데이터와 잘못된 연관을 맺을 가능성이 커진다.
모델은 pre-training 과정에서 지식을 습득한 후에 fine-tuning 과정에서 narrow한 task를 수행하도록 훈련받는데, 이 과정에서 문제가 발생할 수 있다.
물론 모델의 사이즈가 커지면 generalize 할 가능성이 커지지만 (correlation) 모델 사이즈가 커졌다고 해서 꼭 generalize한다는 보장은 없다. (correlation does not imply casuation)
따라서 아주 큰 모델을 잘못 훈련시키면 human level에서 봤을때 전혀 생뚱맞은 결과가 나올 수 있다.1
마지막으로, 근본적으로 사람은 어떤 특정 태스크를 하기 위해 엄청나게 많은 예시가 필요하지도 않다.
근본적으로 사람의 경우에는 간단하게 문제의 방향성만 제시해주면 어떤 태스크든 데이터셋이 필요없이 그 태스크를 수행할 수 있다. 우리가 원하는 것은 NLP 모델이 언젠가 이런 유연성fluidity과 일반성generality를 동시에 갖는 것이다.
In-Context Learning (ICL)
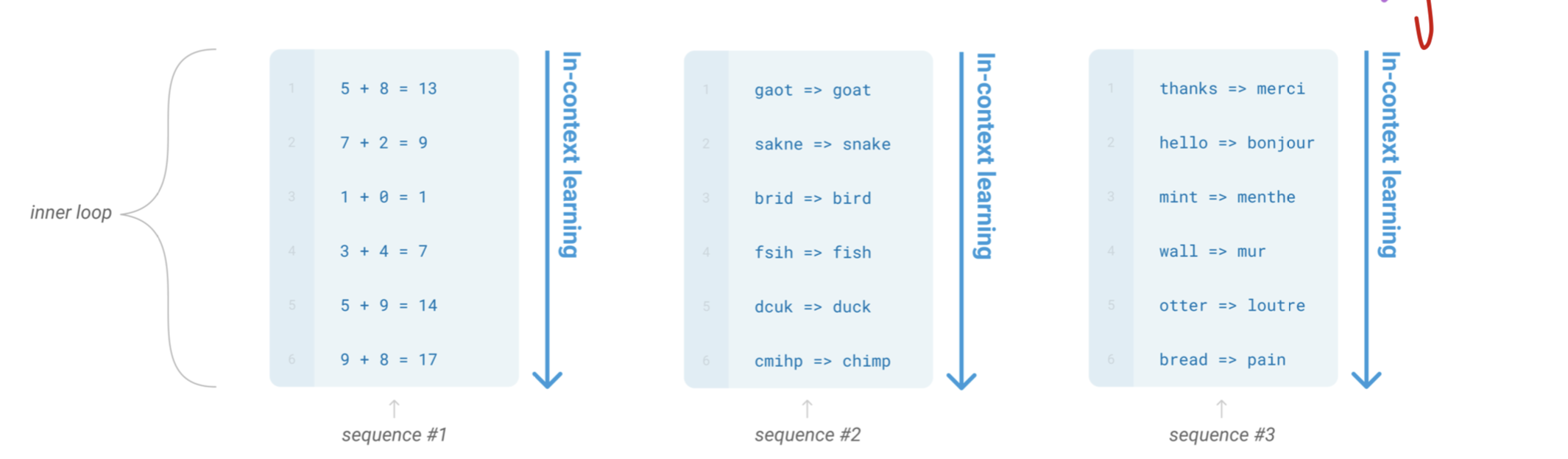
In-Context Learning 은 forward-pass의 sequence 안에서 일어나는 학습 방식을 의미한다. sequence 안에서 일어나기 때문에 gradient가 변경되거나 하는 일은 일어나지 않고 inference 하는 과정에서 one-shot, few-shot 등을 통해 일어나는 것을 일컫는다.(inner-loop structure) 이 단어는 추론하는 도중에 새로운 태스크에 대해서 배우든 단순히 패턴만 인지해서 답을 도출하든 상관없이 사용하는 단어다.
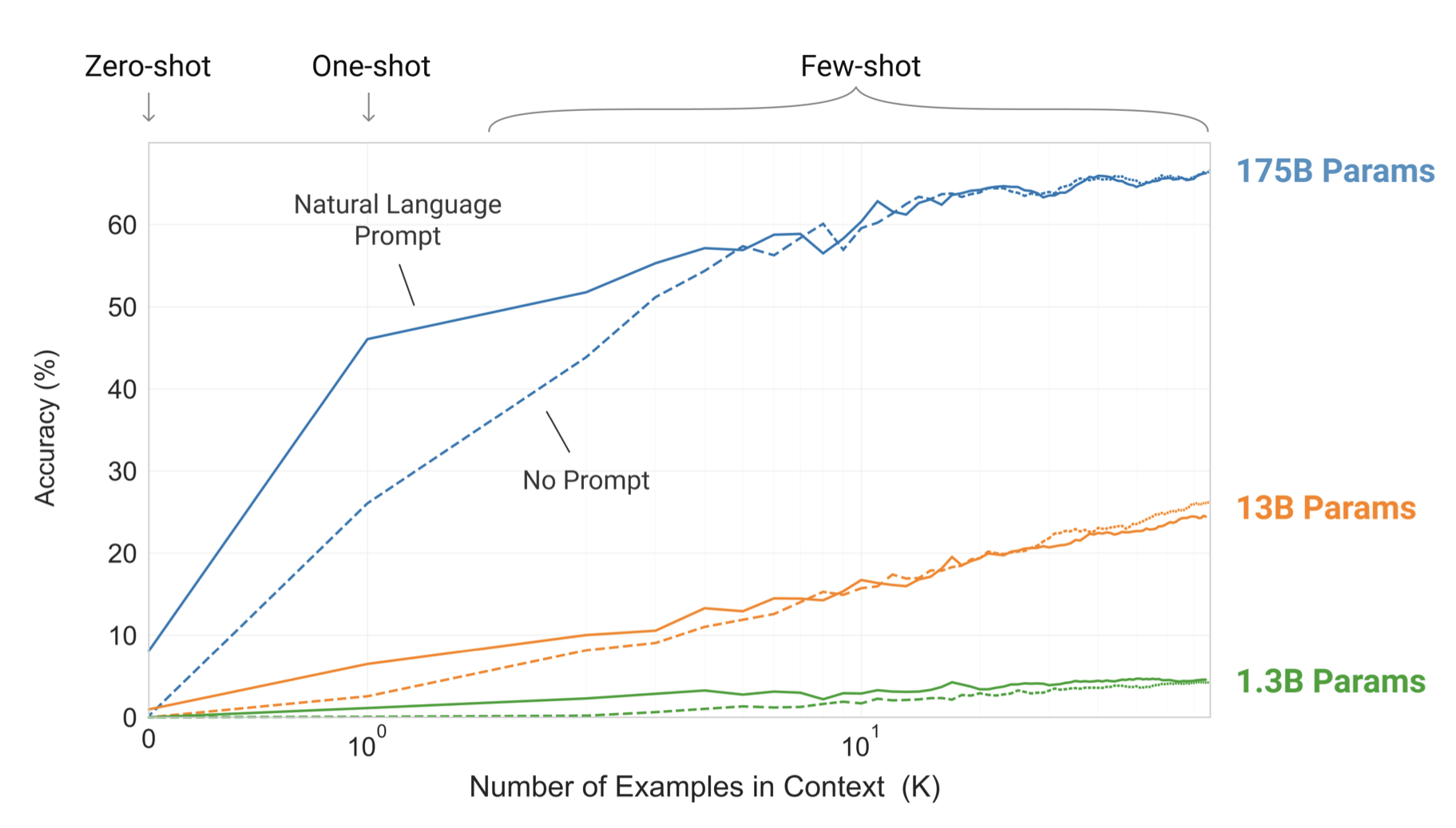
위의 그래프에서는 in-context learning을 zero-shot, one-shot, few-shot로 스케일을 올리면서 주었을 때 성능이 올라가는 그래프이다. k-shot의 개수를 올리면 accuracy가 올라가는 것으로 보아 모델이 generalize가 잘 되었고 ICL에서 문맥적인 의미contextual meaning을 잘 이해하고 있다는 것을 알 수 있다.
Meta learning
(a) few-shot learning: (보통 10~100개) 여러 개의 예시들을 질문하기 전에 던져주는 방식.
(b) one-shot learning: 예시를 하나만 던져주는 방식.
(c) zero-shot learning: 예시를 하나도 주지 않고 어떤 태스크에 대한 답을 구해야 하는지 설명서instruction만 던져주는 방식.
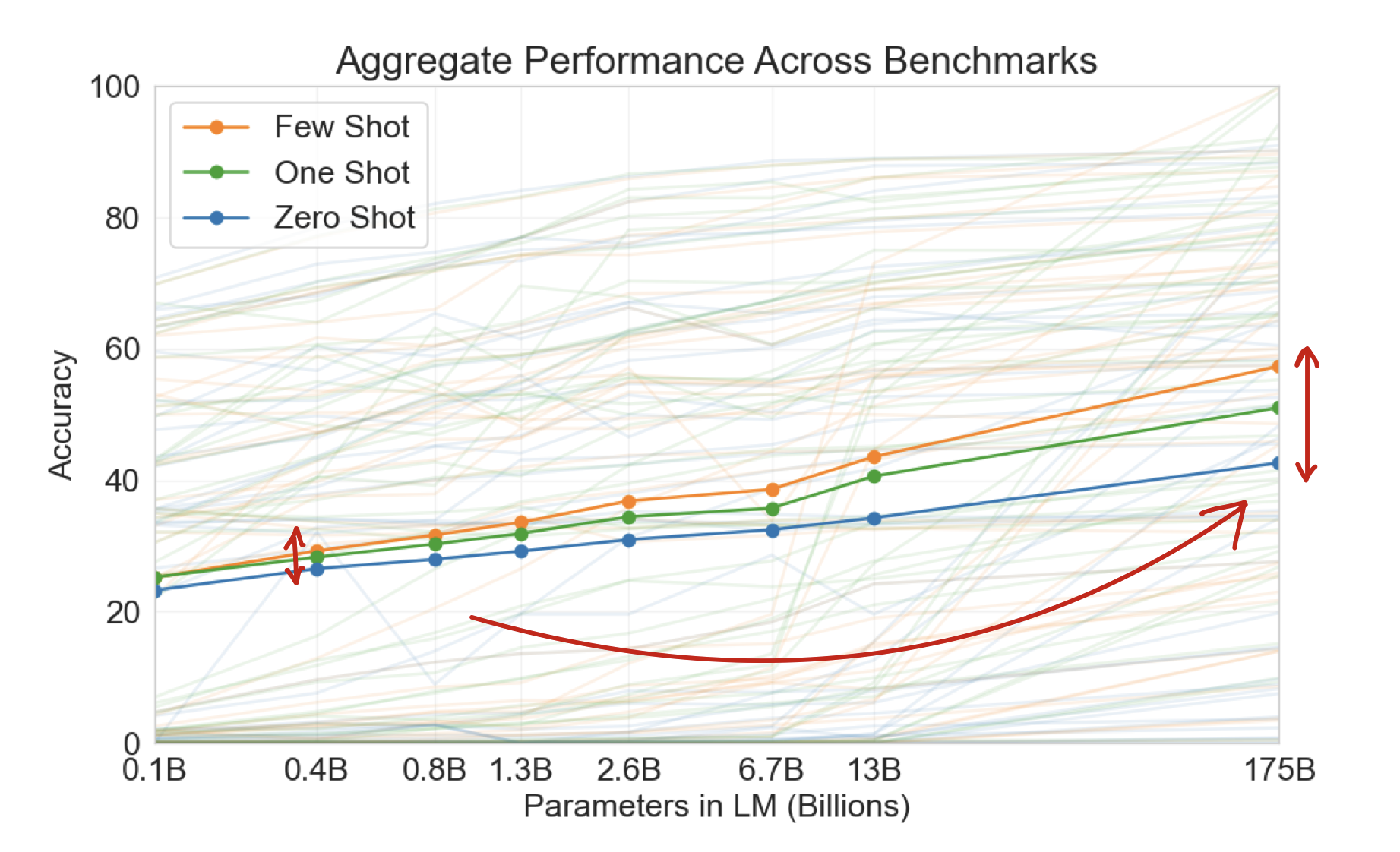
위 사진을 보면 모델 사이즈가 커질수록 zero-shot performance도 few-shot performance도 증가하는 것을 볼 수 있다. 심지어 어떤 특정한 task를 위해서 fine-tuning된 SOTA 모델을 few-shot만을 통해서 이기기도 했다. 또 질문에서 처음보는 단어를 그 당시 딱 한번만 보고도 유연하게 답변에서 사용하는 모습을 보이기도 했고 사람들은 사람이 쓴 글과 GPT-3 모델이 쓴 글을 구분하기 어려워하기 시작했다. 다만, 모든 task를 사람 수준으로 잘하는 것은 아니고 이 정도의 크기에도 맞추기 힘들어하는 task들이 존재했다.
Data Contamination
GPT-3 모델과 같이 큰 모델high capacity model을 pre-training할 때에는 Common Crawl과 같은 데이터셋을 자주 사용하는데, 그런 데이터셋에 잘못된 정보가 들어가 있을 때 data contamination이 발생할 수 있다. 다만 이에 대해 연구를 진행해봤을때에는 GPT-3 모델을 만들 때에는 큰 영향이 없었던 것으로 알려졌다.
결론: Larger models are more proficient meta-learners.
Approach
대부분의 모델 관련 내용은 GPT-2와 유사하다. 훈련 방법, 모델 구조, 데이터 등의 내용은 거의 비슷한데 모델의 크기를 아주 키웠다. In-Context Learning 조차도 비슷한 방식으로 수행하였다. 다만 GPT-3 모델을 평가하는 방식을 네가지 소개했는데, 다음과 같다.
-
Fine-Tuning (FT): 최근 가장 많이 쓰는 approach인데 많은 benchmark에서 높은 스코어를 기록할 수 있지만 각 태스크마다 데이터가 아주 많이 필요하는 단점이 있다.
-
Few-shot (FS): inference time에 모델 자체의 가중치 업데이트는 일어나지 않으면서 예시 태스크들을 보면서 그 예시들을 보고 답을 추론해내는 과정이다. 보통은 예시 개수 k를 달아서 k-shot이라고 표현하고 보통 few-shot에서는 10~100 정도를 잡는다. 적은 개수의 데이터셋이 필요하다는 장점이 있지만 SOTA 모델들보다 보통 훨씬 정답을 못맞춘다는 단점이 있다.
-
One-Shot (1S): 단 하나의 예시를 주면서 정답을 도출해내는 방식. 나머지는 FS와 동일하다.
-
Zero-shot (0S): 1S와 동일한데 예시를 전혀 주지 않는 방식. 가끔은 사람이 문제를 이해하기 어려울수도 있다는 문제가 있고 아주 robust하고 거짓된 상관관계spurious correlations를 피하게 할 수 있다.

사진의 예시는 위의 4가지 예시로 영어를 불어로 번역하게 시키는 과정을 도식화한 것이다.
Parameters
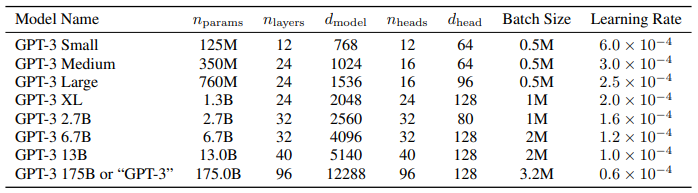
더 큰 모델에 대해서는 learning rate를 작게 잡고 batch size를 크게 설정했고, 큰 모델을 학습시키기 위해 model parallelism을 전체 모델과 각 레이어에 적용했다.
Model and Architectures
모델을 만드는 방법은 GPT-2 때와 같았다. modified initialization, pre-normalization, tokenization 등도 모두 같다. 다만 Sparse Transformer와 같은 방식으로 dense layer와 locally banded sparse attention patterns layer을 번갈아쓰는 레이어를 추가했다.
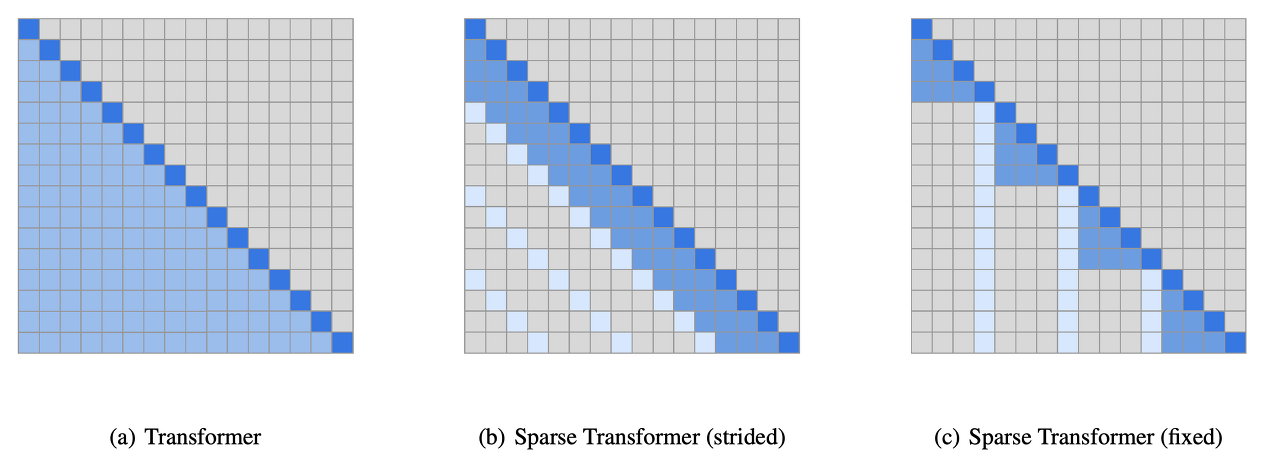
(전 내용이 너무 길 경우 모든 내용을 전부 넣는 것이 비효율적이기 때문에 띄엄띄엄 넣는다.)
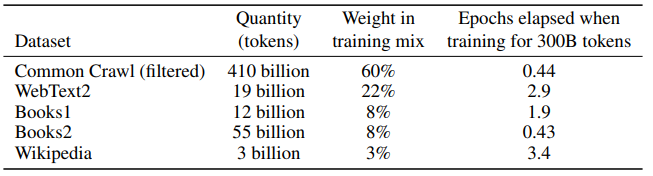
사용한 훈련셋. Common Crawl, WebText2 Books, English wikipedia를 사용했다.
