LIMA: Less Is More for Alignment
요약
- LLM들은 unsupervised pretraining을 우선적으로 거치고 instruction이나 RL 등을 통해서 fine-tuning 했었다.
- 근데 LIMA는 RL이나 HF등을 전혀 안하고 단 1000개의 프롬프트와 답변텍스트들을 통해서만 훈련시켰음에도 아주 잘 generalize해서 한번도 보지 않은 task도 잘 답변하는 모습을 보였다.
- 대신 데이터셋을 아주 diverse하고 조심스럽게 선정함. (이게 중요)
=> fine-tuning 할 때 데이터 퀄리티의 중요성을 다시금 느끼게 함. - 어짜피 지식은 unsupervised pretraining 할 때 대부분 습득하기 때문에 fine-tuning에서 지식적으로 확장하는 것은 별 도움이 안됨.
- llama 65B를 이용해 fine-tuning 했는데 gpt-4, bard, davinci와 비교해서 비슷하거나 어느때는 오히려 더 나은 결과를 냄.
Introduction
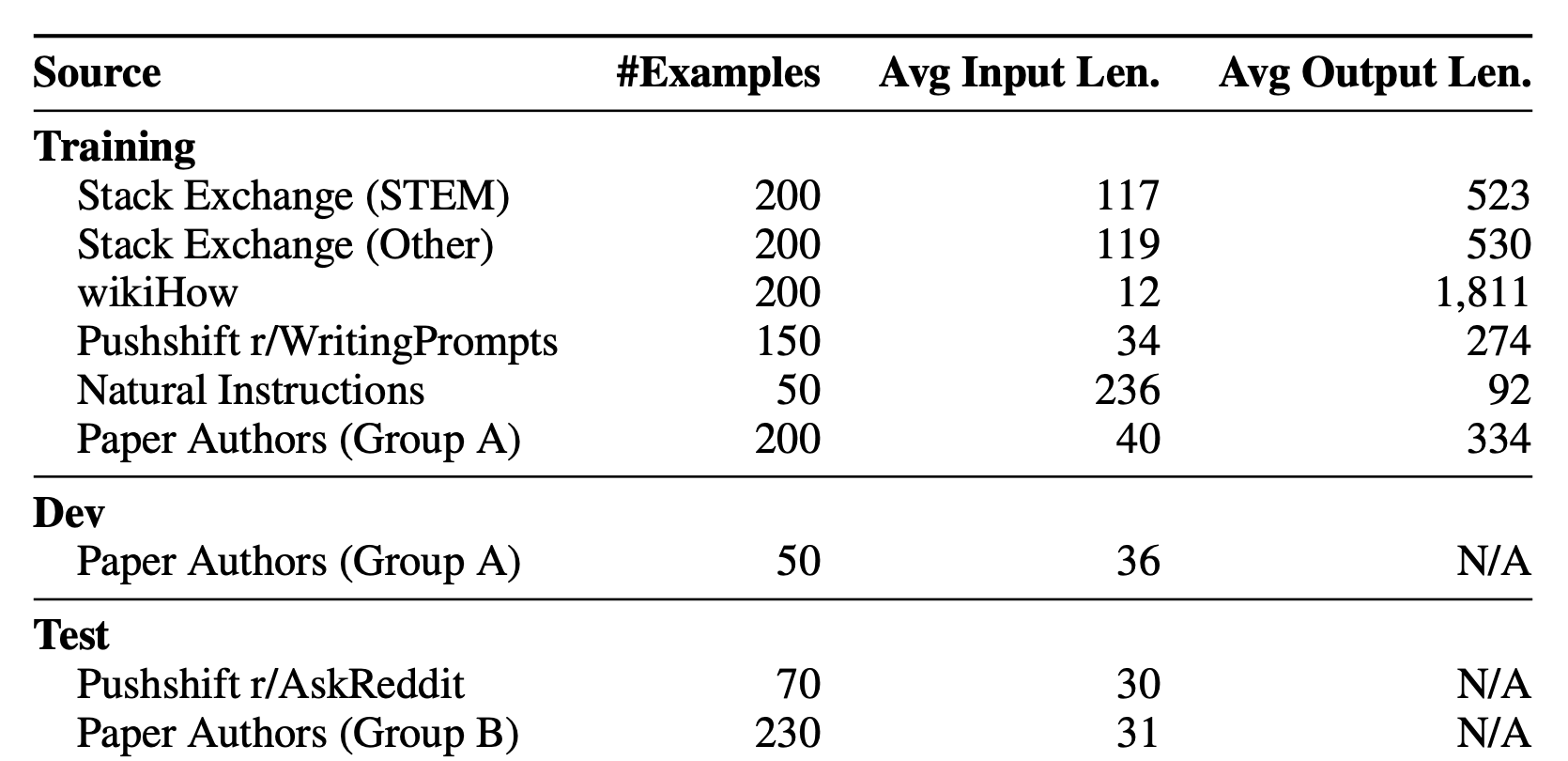
- 후술하겠지만 여러 군데에서 사람이 직접 엄선한 1,000개의 데이터셋을 이용했다.
- 전체 합치면 750,000 토큰밖에 되지 않는다.
- 고작 이것만으로 OpenAI RLHF davinci-003를 이겼고, 65B Alpaca도 이겼다.
- Alpaca는 52000개의 instruction이었으니 52배 이상 효율적으로 훈련했다고 볼 수 있겠다.
- GPT4, Bard를 이기진 못했지만 LIMA 쪽이 더 낫다고 한 경우가 꽤 있었다. (약 43%)
Dataset
Superficial Alignment Hypothesis
모델의 지식이나 역량은 거의 pretraining 단계에서만 얻는다는 가설이다. 이게 사실이면 fine-tuning 단계에서는 우리가 원하는 형식의 데이터셋을 조금만 모아두더라도 원하는 모델을 충분히 만들어낼 수 있다는 것이다. 물론 확실히 데이터셋의 퀄리티가 좋은 경우에서이다.
- Stack Exchange, wikiHow, Reddit 에서 데이터셋을 얻어왔다.
- Stack Exchange
- 아주 가지런히 정돈된 데이터셋이라는 느낌.
- 너무 짧거나, 길거나, 1인칭으로 써진 것들을 제외한 후 HTML 태그나 이미지, 링크를 처리한 후에 바로 데이터셋으로 사용할 수 있을 정도였다.
- diverse하게 만들기 위해 여러 주제에서 질문을 뽑아왔다.
- wikiHow
- 이 경우에도 아주 가지런히 정돈됨.
- 마찬가지로
This article,The following answer와 같은 문구나 이미지, 링크만 처리한 후에 곧바로 데이터셋으로 사용할 수 있었다.
- Pushshift Reddit Dataset
- upvote (좋아요 같은 개념) 를 많이 받은 reddit 댓글들을 모아놓은 데이터셋이다.
- 이 경우에는 너무 농담식으로 써있거나 너무 비꼬는, 풍자적인 댓글들이 많아서 꽤 많이 쳐냈다.
Training LIMA
- 라마 65B 모델을 fine-tuning 함.
- end-of-turn token (EOT token)을 EOS 토큰 대신에 각 문장의 마지막에 넣었는데, 이는 단지 EOS 토큰과 섞이는 것을 방지하기 위함임.
hyperparamters
- num_epochs: 15
- optimizer: AdamW
- 𝛽_1: 0.9, 𝛽_2: 0.95
- weight_decay: 0.1
- batch_size: 32 (64 for smaller models)
dropout residual connections
dropout residual connections도 사용함.- residual connection:
x + f(x)의 형태로 진행. => 훈련에 도움. - dropout probability를 훈련 초반에는 0.0이고 마지막으로 갈수록 0.3에 가깝게 가도록 설정.
- 질문의 적당한 부분이 날아가더라도 적절한 답을 찾아내게 되므로 model의 robustness를 기를 수 있게 된다.
- dropout을 하지 않았을 경우에 모델은 가장 중요한 것만 보고 나머지는 무시하는 경향이 나타나므로 dropout을 통해서 조금씩 분산시키는 역할을 함.
- regularization의 역할, batch normalization 역할도 같이 수행.
Perplexity does not correlate with generation quality.
- perplexity(PPL)는 많은 LLM들이 사용하는 quality 지표이지만 perplexity가 quality와 연관이 있긴 하지만 높다고 quality가 높다라고 단정지을 수는 없음.
- 서로 다른 token sequence로, 서로 다른 tokenizer로 PPL을 계산할 경우 각 토큰마다 모델이 할당하는 likelihood가 전혀 다르기 때문에 서로 다른 두 모델을 비교하는 것은 부적절.
- 모델이 다른 것이지 두 모델의 성능 차이에 의해서 생긴 변화라고 보는 것은 잘못됨.
Human Evaluation
- 52,000개의 example로 훈련한 alpaca보다도 확실히 성능이 좋았다.
- 훈련 효율이 최소 52배 이상 상승한 것임.
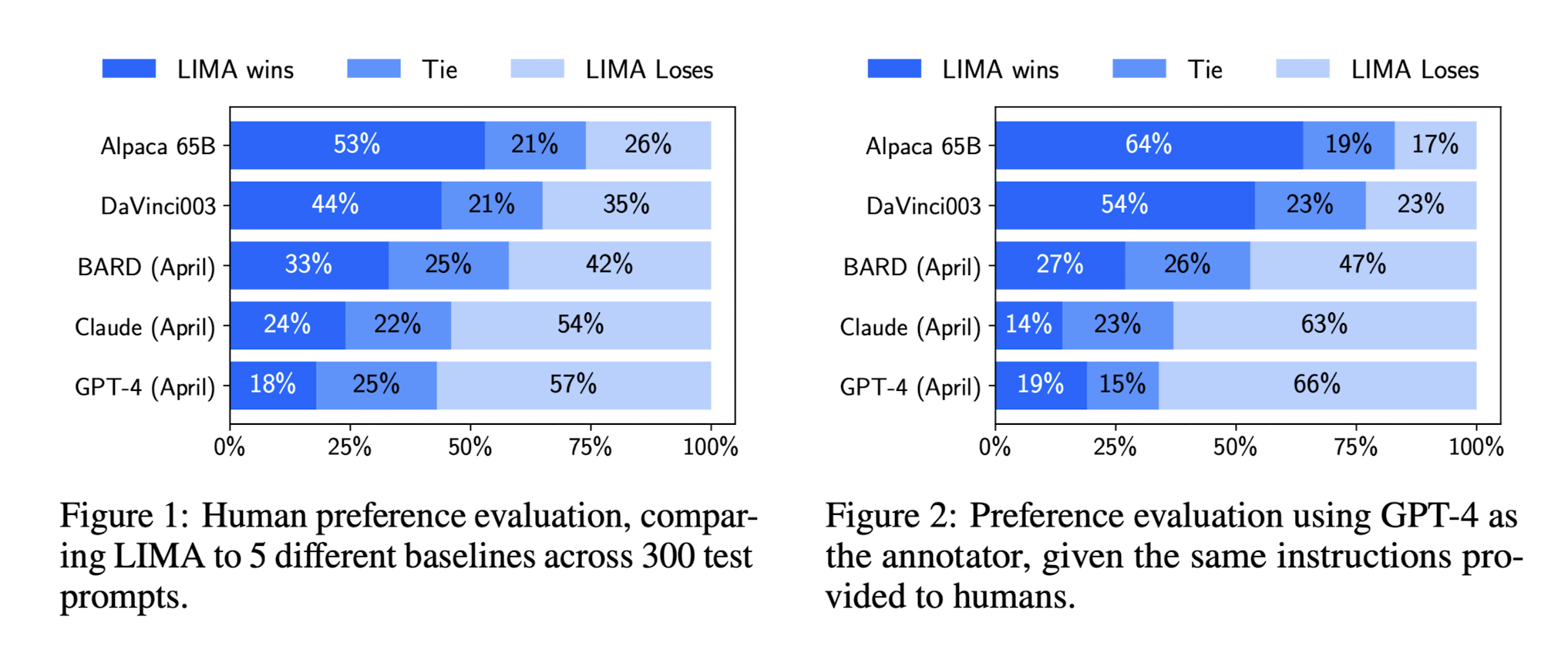
- 아주 잘하지는 않지만 그래도 1000개의 example만인걸 고려하면 꽤 괜찮다.
- p=0.9, temperature 𝜏=0.7 를 이용한 top-p sampling으로 generate한 문장들임.
- max_token_length는 2048로 제한.
결론
Scaling up input diversity and output quality have measurable positive effects, while scaling up quantity alone might not.
결론은 fine-tuning 할 때만큼은 양치기로 승부할 것이 아니라는 거다. 적은 예시들을 들고 오더라도 최대한 다양하고 퀄리티 좋은 예시를 들고 오는 것이 낫다는 것이다.
그런데 오히려 반대로 UE5-Llama-LoRA 처럼 퀄이 매우 안좋은 예시를 들고와도 잘 학습되는 언뜻보면 반대되는 결과가 나오는 것도 있어서 fine-tuning을 어떻게 해야할까 하는 생각을 많이 해보는게 중요한 것 같다.

성랩입니다 :)