Language Models are Unsupervised Multitask Learners
Introduction
-
What NLPs are now
- narrow experts
- brittle and sensitive to the data distribution or trivial changes
- Single task training on single task dataset
- still supervised learning
- we don’t need single domain experts anymore
- 광범위한 domain의 expert가 필요함
- 최근에는 GLUE등의 benchmark dataset도 공개됨
-
What we want from NLP
- competent generalist
- no need to label tasks and create training dataset
- zero-shot
-
이 논문에서는 이 두가지 흐름을 엮어서 모델을 만듬
- Multitask
- unsupervised learning
-
perform down-stream tasks
-
zero shot
-
with almost no modification to the model
Approach
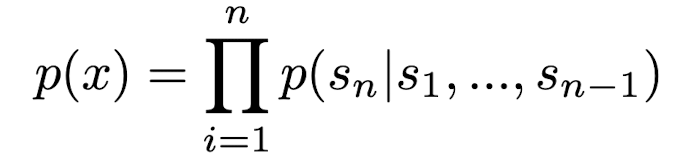
-
Approach 자체는 GPT-1 논문과 유사 (전 token들을 보고 다음 토큰을 예측)
-
McCann et al. (2018) decaNLP (The Natural Language Decathlon) 논문에 따르면 LM들은 instruction이 주어진 경우 Multitask를 잘 수행할 수 있음.
-
p(output | input)이라고 하던걸p(output | input, task)라고 표현하면 Multitask를 instruction으로 표현할 수 있음.! -
Translation:
(French | English, translate English to French) -
Question & Answering:
(answer | question with document, answer the question) -
(논문 시기 기준) 최근 연구에 따르면 이런 셋업에서 supervised 훈련이 되긴 되는데 너무 느리다.
-
우리 연구에 의하면 충분히 큰 모델에 대해서는 이런 추론을 하고 예측하는게 가능하다.
-
그렇다는건 unsupervised learning만으로 multitask가 가능하다는 얘기잖아?
-
training gogo
Training datasets
⇒ WebText, Common Crawl, Newspaper3k, LAMBADA, SQUAD 데이터셋 사용
-
Common Crawl (CC) had significant quality issues
-
⇒ 사람이 직접 좋은 document를 뽑아서 데이터셋을 새로 구축함.
-
dataset안에는 4500만개의 링크가 있었고 그 링크를 재구축한 결과 8백만개의 문서, 40GB의 텍스트가 나왔다. (이 과정에서 중복을 제거하려고 Wikipedia 데이터셋은 사용하지 않음)
-
Reddit 답변도 사용 (karma 3이상받은 댓글만 선별하여 사용)
-
위키피디아 데이터만으로는 일반화된 데이터가 만들어지지 않는다. ⇒ 다양한 데이터를 선별하여 수집.
-
8-gram bloom filtering (8단어씩 겹치는지 확인) 을 통해 판별했는데 single spaced-
-
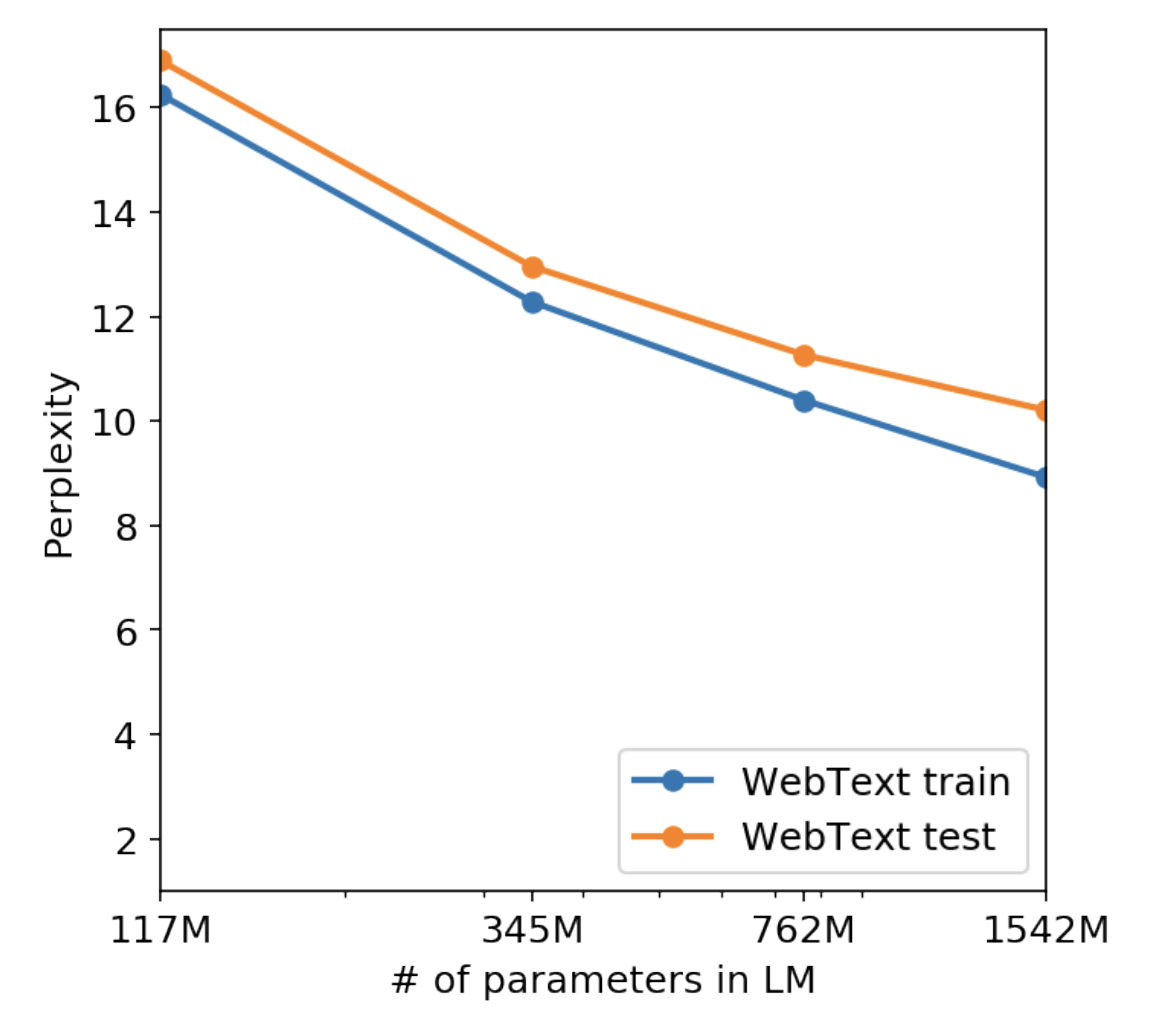
아니 그럼 overfit 된건 아닌가?
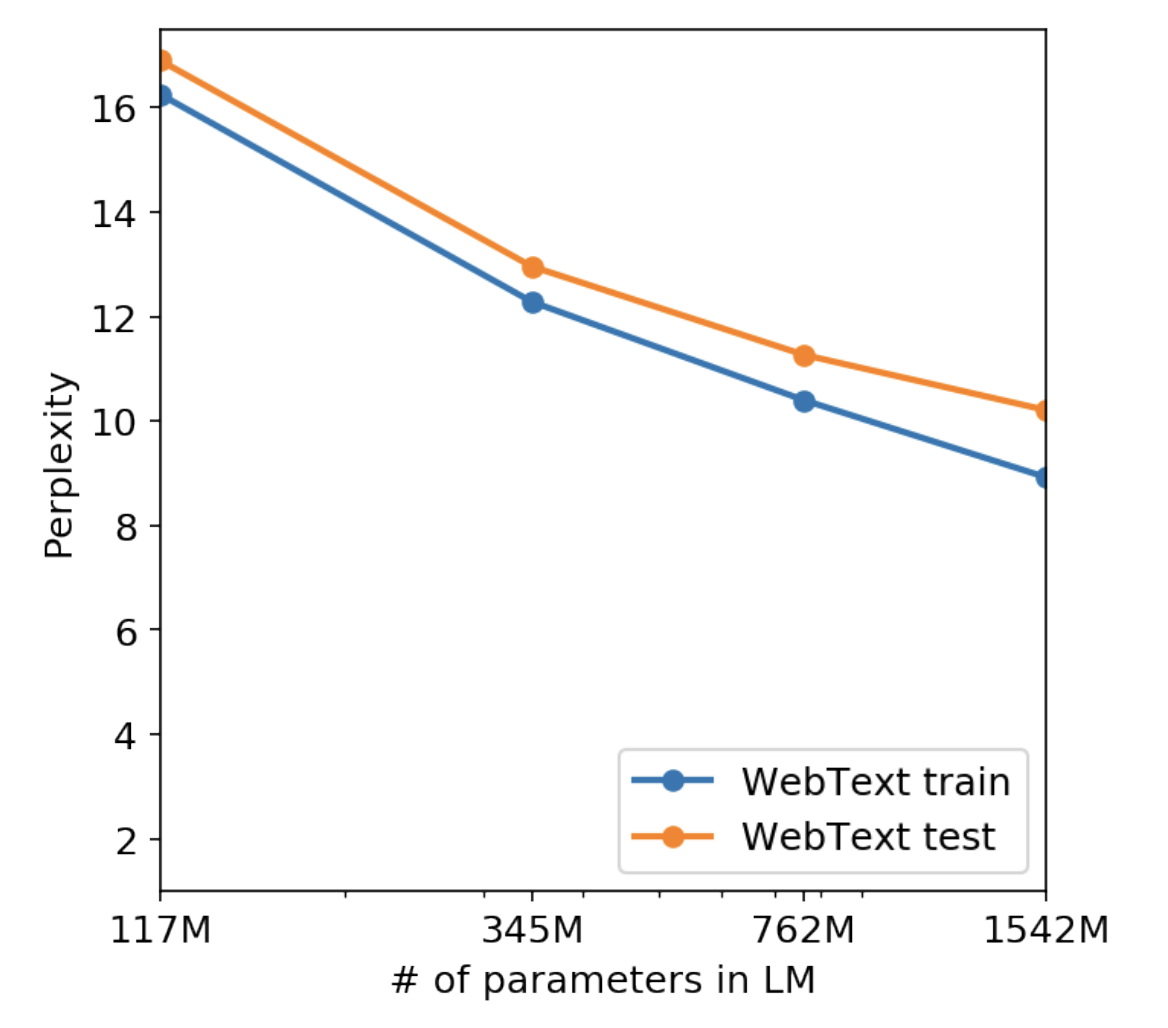
- 둘다 커질수록 perplexity 가 작아지니까 overfit이 된거가 아니라 generalize 를 정말 잘한거였다.
Input Representations (BPE, BLPE)
- 글자와 단어의 중간 단위를 사용할 수 있음.
- general LM은 모든 문자열의 확률을 계산하고 생성해낼 수 있어야함.
- Out of Vocabulary가 거의 안뜸. 이게 진짜 중요.
- WebText를 전체 파싱할때 400억 토큰들 중 토큰이 26개밖에 안뜸.
BPE라는게 뭘까?
aaabbcd 라는게 있을때 가장 많은 문자열인 a를 가장 적은 문자로 치환 (허프만 부호화랑 비슷)
a, b, c, d를 모두 토큰으로 치환
근데 BPE는 ASCII인데 모든 문자열을 표현할 수 있어야해.
- 근데 모든 문자를 토큰화하면 너무 경우의 수가 많아. ⇒ Byte Level Pair Encoding
⇒ 아예 그냥 유니코드를 박아버리자.
-
context size = 1024, batch size = 512 로 증가.
-
Byte상에서 동작하기 때문에 lossy한 pre-processing이 더이상 아님.
-
zero shot 만으로 7/8 SOTA 달성
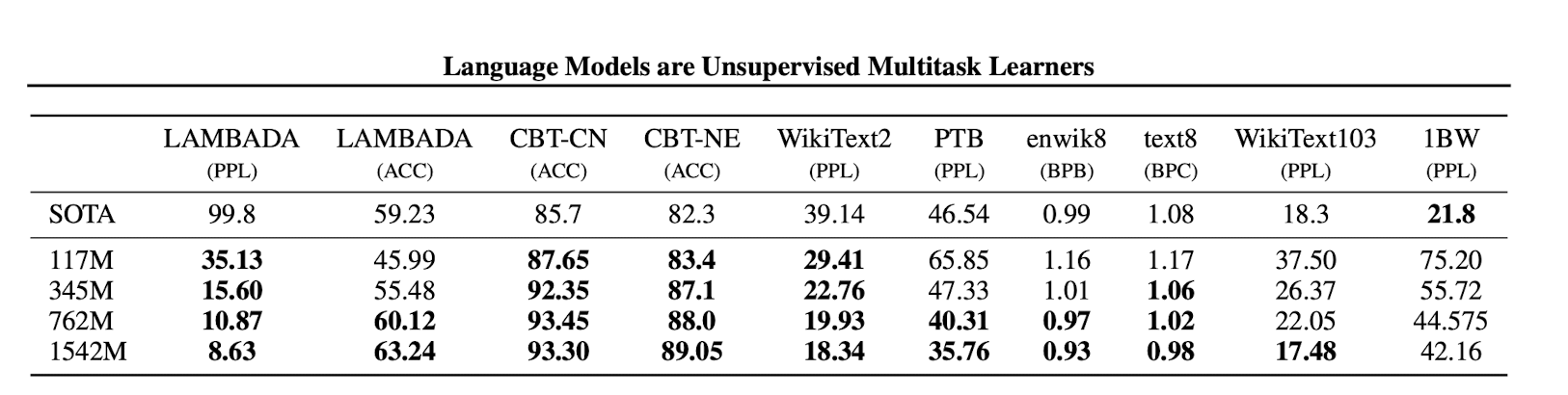
- 근데 greedy algorithm 이라서 여러가지 문제점이 발생할 수 있긴 함.
- 가장 확률이 높은 곳으로만 가려고 하고 단어를 찾았다 싶으면 바로 전환해버리기 때문에 dogma를 dog, ma, 라고 분리할 수가 있음.
- 그리고 그런식으로 두 단어를 합쳤다고 했을때 중간에 글자가 사라지는 경우가 많은데 그 점에 대해서는 잘 대처하지 못함. dog + cat ⇒ docat? (예시가 뭐가 있을까??)
Language Modeling
- 역시나 Transformer Decoder block 을 여러 겹 쌓아서 만듬.
- Layer Normalization이 각 sub block의 input으로 옮겨짐. → why….?
- Layer Normalization이 마지막 decoder block 뒤에 하나 추가됨. → why?
- vocab size가 50600 정도로 확장
Discussion
- unsupervised learning 분야에서 아직 연구할 것이 꽤 남았다.
- 독해 분야에서는 앵간 성능이 잘 나오는데 요약에서는 별로 좋지 못함. (심지어 랜덤하게 생성된 문장보다 별로인적도 있었다)
- zero shot 이니까 감안 가능?
추가
우리가 목표한 성능이 나왔을때 우리가 정말 잘해서 성능이 잘 나온건가에 대한 고민이 필요하다.
추가로 봐야할 한국어 논문 : https://arxiv.org/pdf/2109.04650.pdf
( 한국어는 BPE를 어떻게 적용해야할까? )
https://engineering.clova.ai/en/posts/2022/05/hyperclova-corpus
한국어 데이터셋을 어떻게 넣어야 잘 될까?
