
문제 정의
와인은 1-9등급까지의 등급이 있고 7등급부터 프리미엄 와인으로 고가에 판매가 되는데, 공정에서 최대한 많은 프리미엄 와인의 생산을 증대시키려고 한다.
품질 등급에 영향을 끼치는 공졍을 확인하여 일정한 맛의 와인을 프리미엄 등급으로 생산을 증대하고자 한다.
데이터 확인
소스코드 : GitHub
데이터 컬럼 상세

레드와인
화이트 와인
EDA & 전처리
'와인 품질 등급 분석 - 1'에서 진행한 부분은 제외하고 진행하겠다.
품질 주요 인자들을 탐색하고 공정 변수들을 확인하여 프리미엄 와인 생산을 증대시키는 방향으로 탐색을 한다.
품질 등급을 프리미엄과 일반으로 나누고,
프리미엄과 일반을 구분하는 변수를 파악하기 위해 회귀 분석 모델과 분류 분석 모델을 설정하여 진행하도록 한다.
기본 정보 탐색
데이터의 가장 낮은 등급은 3이고 높은 등급은 9인데, 최소값과 최대값을 살펴보면 낮은 등급은 수치들이 대부분 낮은 분포를 가지고 있고 높은 등급은 높은 수치들의 분포를 가지고 있다.
최소값과 최대값, 평균값을 놓고 보았을 때, 특별히 아웃라이어로 정의할 만한 눈에 띄는 데이터는 없어 보인다.
평균값과 최대값의 차이는 눈에 띄게 차이가 나는 것은 아니지만,
좋은 등급은 첨가물 수치의 차이가 나는 것으로 예상된다.
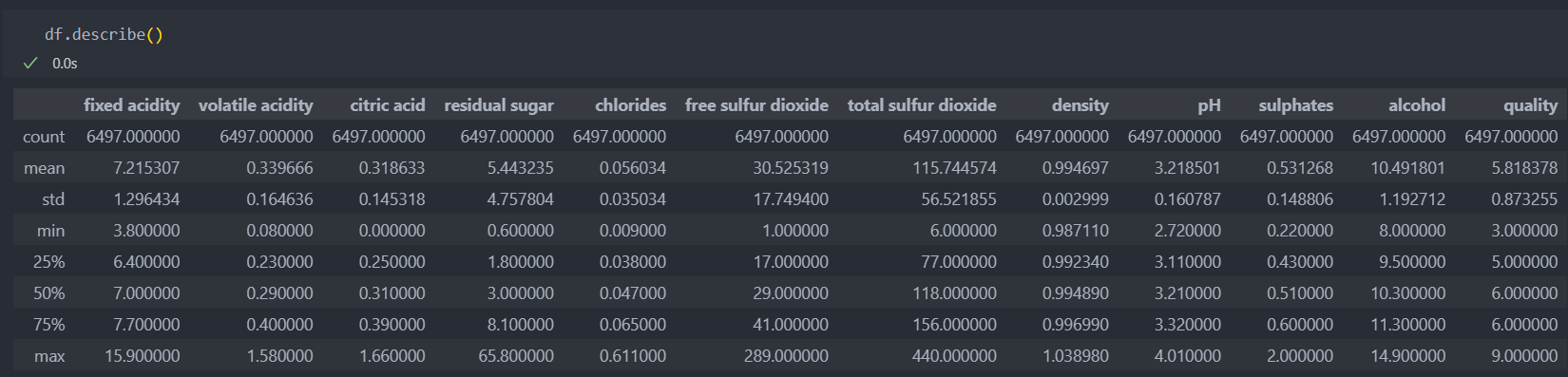
모두 수치형 데이터들이다.
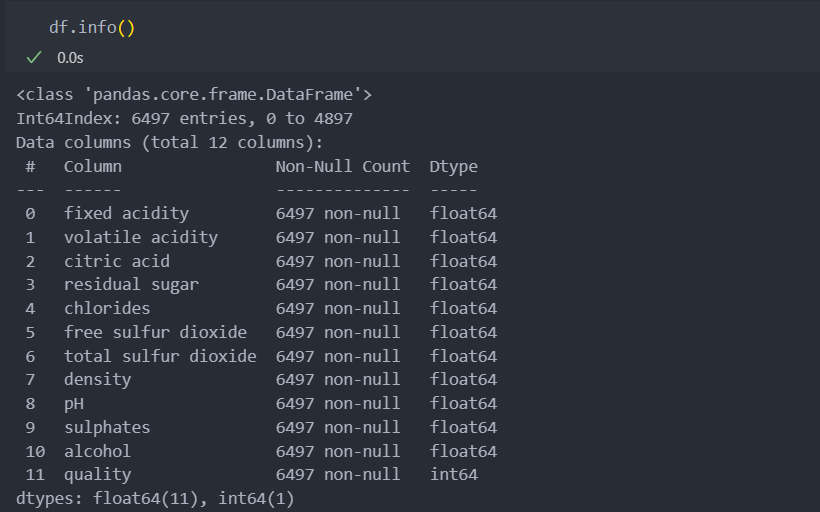
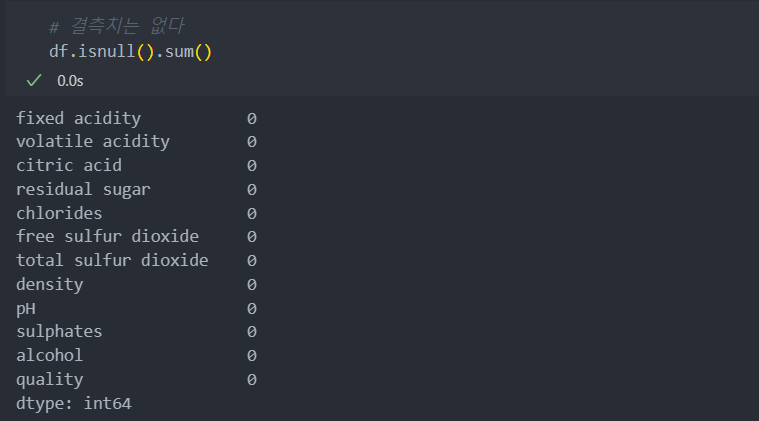
결측치는 없다.
품질의 프리미엄 등급과 아닌 등급으로 등급을 나눠서 진행하도록 한다.
프리미엄 등급(7-9등급)이면 1, 아니면(1-6등급) 0으로 설정.
프리미엄 등급이 약 20%로 클래스 불균형의 문제가 약하게 존재한다.
df['target'] = np.where(df['quality']>6, 1, 0)
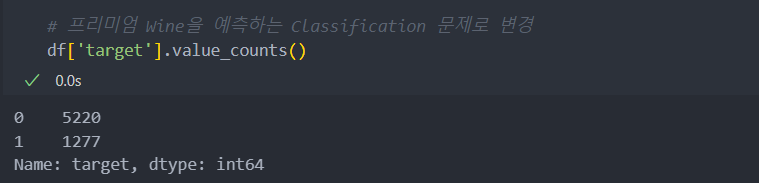
클래스 불균형 확인
현재 프로젝트는 프리미엄 등급의 생산량을 늘리기 위한 주요 인자를 찾기 위한 것이 목적이기에,모델의 성능을 높이기 위한 것이 목적이 아니다.
하지만 성능을 높일수록 등급에 영향을 끼치는 주요 특징(컬럼, 인자)을 조금 더 잘 판별할 수 있을 것이라 보고 불균형을 완화하려 한다.
k-최근접 이웃 모델(KNeighborsClassifier)은 클래스 불균형에 민감한 모델로, 불균형이 존재하면 recall 수치가 낮게 측정이 되는 것을 이용한다.
n_neighbors 인자를 5에서 11까지 확인했을 시 약 20-37% 정도로 재현율이 반환되는 것으로 보아서 불균형이 존재한다.
그래서 SMOTE를 사용하여 2:1 비율까지 업샘플링을 하고, 기존과 업샘플링을 한 데이터를 모델링 시 비교해보자.
먼저 데이터를 나눈다.
from sklearn.model_selection import train_test_split
X = df.drop(['quality', 'target'], axis=1)
Y = df['target']
train_x, test_x, train_y, test_y = train_test_split(X, Y, stratify=Y, random_state=29)불균형을 확인하는 작업을 위해 KNeighborsClassifier 모델을 활용한다.
# kNN을 사용한 클래스 불균형 테스트
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.metrics import *
kNN_model = KNN(n_neighbors = 5).fit(train_x, train_y)
pred_Y = kNN_model.predict(test_x)
print('recall_score: ', recall_score(test_y, pred_Y))
print('accuracy_score: ', accuracy_score(test_y, pred_Y))
결과:
recall_score: 0.3730407523510972
accuracy_score: 0.8073846153846154그리고 업샘플링을 진행하기 위해 SMOTE를 사용한다.
from imblearn.over_sampling import SMOTE
# SMOTE 인스턴스 생성 / 인자 sampling_strategy : 업샘플링 비율 조절 인자
oversampling_instance = SMOTE(k_neighbors = 3, sampling_strategy = {1:int(train_y.value_counts().iloc[0] / 2), # 기존의 0 클래스의 크기에서 1/2 수 만큼 생성
0:train_y.value_counts().iloc[0]}) # 기존의 0 인 클래스 수와 동일하도록
# 오버샘플링 적용
o_Train_X, o_Train_Y = oversampling_instance.fit_resample(train_x, train_y)
# ndarray 형태가 되므로 다시 DataFrame과 Series로 변환 (남은 전처리가 없다면 하지 않아도 무방)
o_Train_X = pd.DataFrame(o_Train_X, columns = X.columns)
o_Train_Y = pd.Series(o_Train_Y)이제 비율을 보면 2:1 비율로 업샘플링이 되었다는 것을 확인할 수 있다.
업샘플링이 진행되었다고 해서 반드시 모델의 성능의 향상을 가져오지는 않기에,
업샘플링을 진행한 데이터와 아닌 데이터를 모델 성능 비교시 같이 본다.
중요한 점은 평가 데이터(test data)는 손을 대면 안 되기에, 미리 데이터를 나누어 놓았다.
품질 정보 탐색
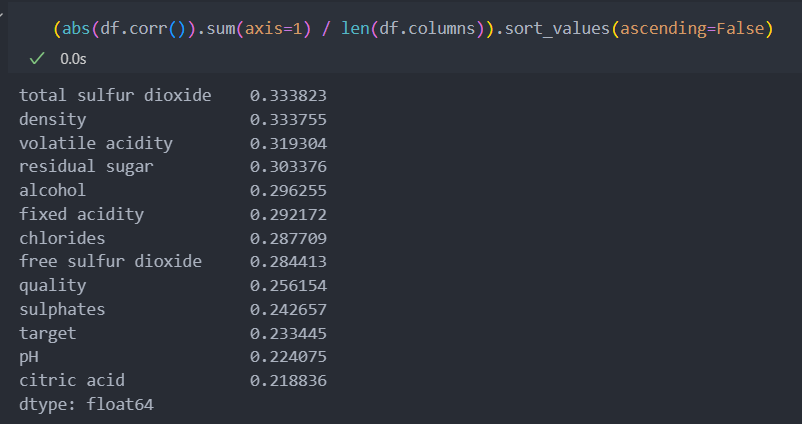
특징(컬럼)들의 상관관계를 확인하기 위해 먼저 히트맵으로 확인해보자.
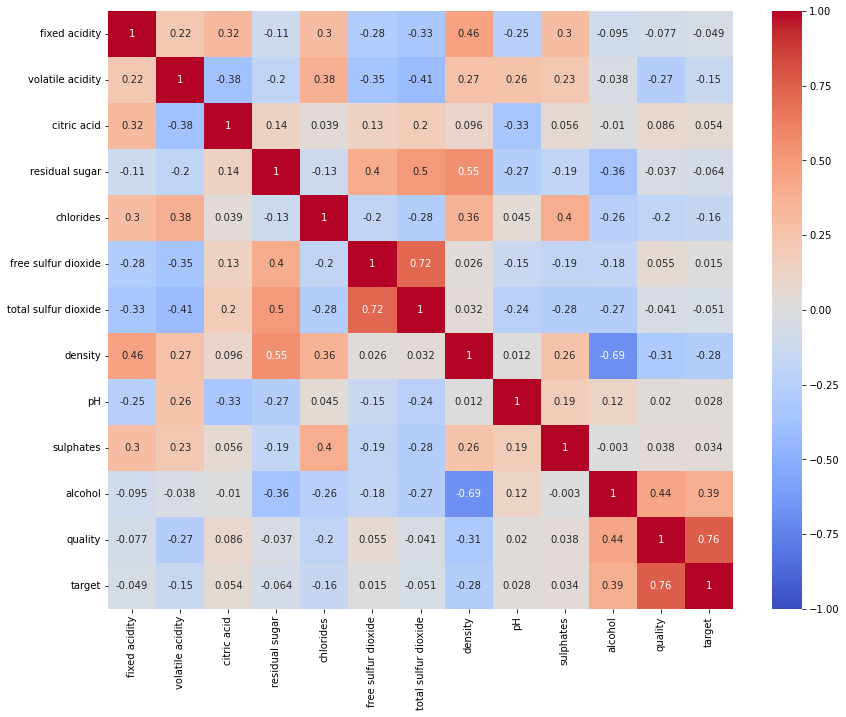
각 특징별로 상관관계들의 절대값들을 더해서 특징수로 나눠서 상관계수가 가장 높게 나타나는 컬럼이 무엇인지 보자.
대표수치라고 할 수는 없지만, 모든 상관계수들의 합이니 합이 높을 수록 각 특정 컬럼들이 미치는 상관성을 대략적으로 볼 수 있다.
그리고 높을수록 프리미엄을 가려내는 중요한 변수가 될 확률이 높다.
이제는 라벨(타겟) 데이터에 영향을 많이 주는 데이트 3개를 산점도 그래프로 그려보자.
'volatile acidity'와 'density'는 등급이 높을수록 수치가 낮은 경향을 보이고, 'alcohol'은 등급이 높을수록 수치가 높은 경향을 보인다.

모델링 1 - 회귀 분석
라벨이 0과 1로 이루어져 있어 분류 문제지만 회귀로도 진행해서 설명력을 갖는지 확인해보자.
선형 회귀 LinearRegression 모델을 사용할 것이다.
0과 1사이 값의 라벨에 대해서 0.26 - 0.27값의 차이가 보이고, r2 score는 설명력인데 그다지 좋아보이지 않는다.
# LR(선형회귀) 모델 활용
from sklearn.linear_model import LinearRegression as LR
from sklearn.metrics import mean_absolute_error, r2_score
lr = LR()
lr.fit(train_x, train_y)
pred_train = lr.predict(train_x)
pred_test = lr.predict(test_x)
mae_train = mean_absolute_error(train_y, pred_train)
r2_train = r2_score(train_y, pred_train)
mae_test = mean_absolute_error(test_y, pred_test)
r2_test = r2_score(test_y, pred_test)
print(f'mae train: ', mae_train)
print('r2 train: ', r2_train)
print('-'*20)
print('mae test: ', mae_test)
print('r2 test: ', r2_test)
결과:
mae train: 0.267818619333233
r2 train: 0.19844504769653282
--------------------
mae test: 0.27467166147572714
r2 test: 0.17100151159564436그리고 클래스 불균형을 조금 해소한 데이터로 다시 진행해보자.
정답과 예측값의 차이는 더 벌어졌고, r2를 보면 설명력도 줄어들어서 업샘플링한 것의 좋지 못한 결과를 볼 수 있다.
lr = LR()
lr.fit(o_Train_X, o_Train_Y)
pred_train = lr.predict(o_Train_X)
pred_test = lr.predict(test_x)
mae_train = mean_absolute_error(o_Train_Y, pred_train)
r2_train = r2_score(o_Train_Y, pred_train)
mae_test = mean_absolute_error(test_y, pred_test)
r2_test = r2_score(test_y, pred_test)
print(f'mae train: ', mae_train)
print('r2 train: ', r2_train)
print('-'*20)
print('mae test: ', mae_test)
print('r2 test: ', r2_test)
결과:
mae train: 0.34575993988535864
r2 train: 0.24948126270298
--------------------
mae test: 0.31956417608207155
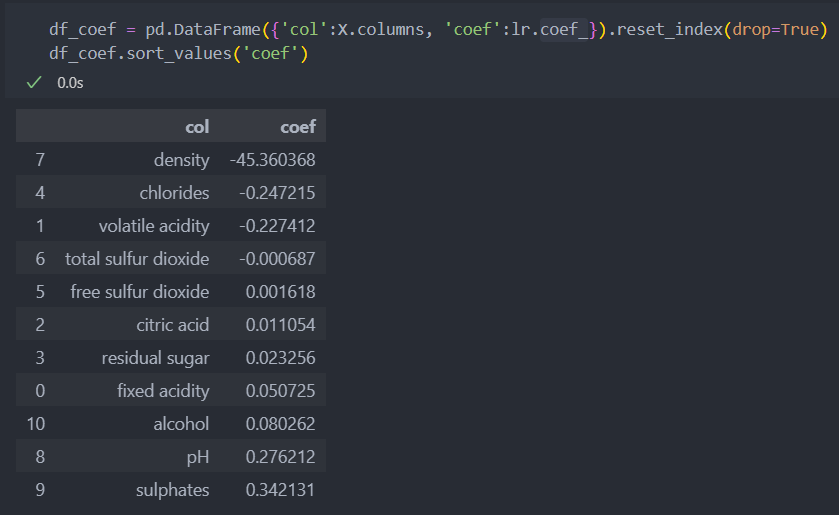
r2 test: 0.07133318420475421사실 분류 문제를 가지고 회귀분류를 진행한 것은 선형 모델을 사용하려는 것 보다는, 모델의 계수(model.coef_)를 보여주기 때문이다.
계수를 보면 'density'는 음수로 density가 낮아져야 등급이 올라가며, 'sulphates' 양수로 sulphates가 높아지면 등급이 올라간다고 유추해 볼 수 있다.
회귀 문제를 볼 때에는 다중공선성도 생각해야 한다.
다시 말해서 특징간의 상관성이 높을수록 수치가 높은 특징만 반영이 되고 다른 특징은 반영이 되지 않을 수 있거나, 여러 특징들 중 어느 특징에 의해서 결과가 도출이 되었는지 확인이 어려운 문제가 있다.
그래서 표준화 및 정규화로 완화 및 PCA를 통해서 해소하거나 상관성이 있는 특징(컬럼) 중 하나를 삭제하는 방향으로 갈 수도 있다.
여기에서는 다중공선성을 확인하고 제거하는 방향으로 진행해보자.
상관계수가 0.5 이상인 것들만 가져와서 확인하고 데이터를 다시 분할하여 진행한다.
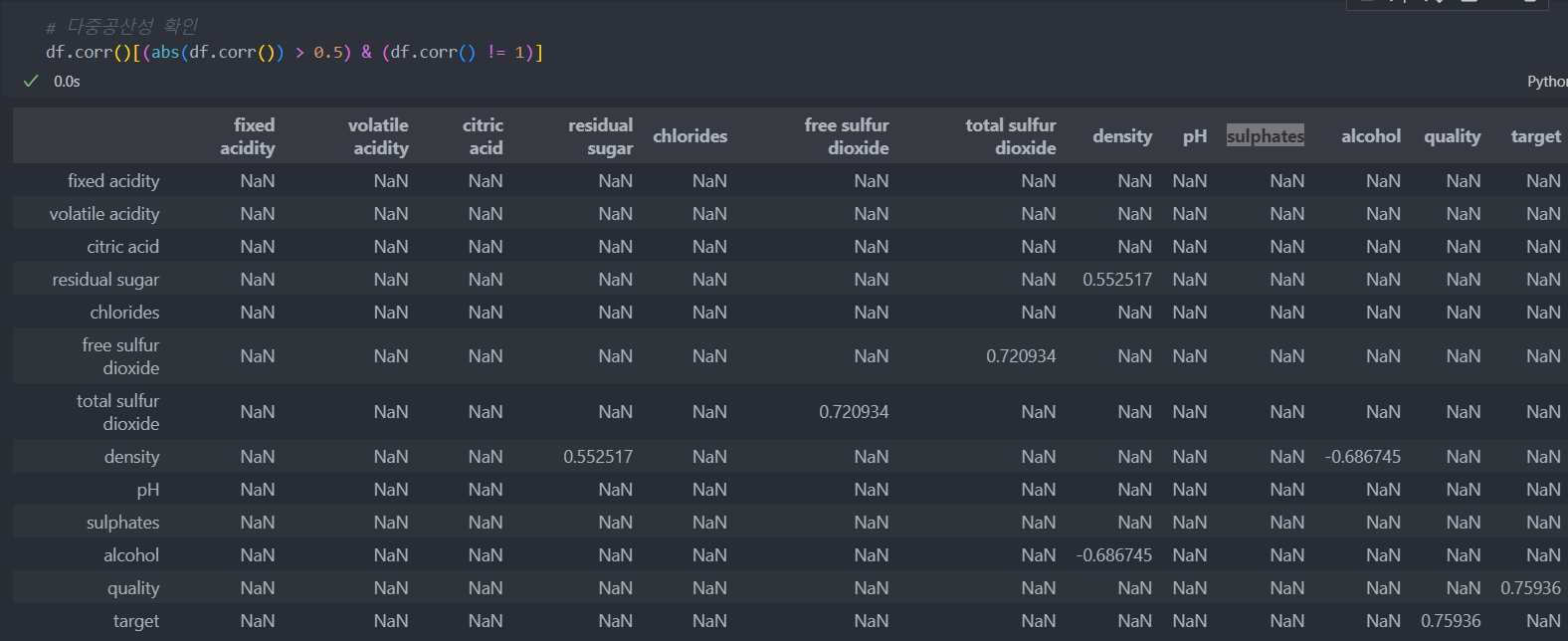
'residual sugar', 'free sulfur dioxide' 두개의 특징을 삭제하고 다시 진행해본다.
mae값이 조금 좋아졌지만 r2값도 떨어진 것을 볼 수 있다.
X = df.drop(['residual sugar', 'free sulfur dioxide', 'quality', 'target'], axis=1)
Y = df['target']
train_x, test_x, train_y, test_y = train_test_split(X, Y, stratify=Y)
lr.fit(train_x, train_y)
train_pred = lr.predict(train_x)
test_pred = lr.predict(test_x)
mae_train = mean_absolute_error(train_y, train_pred)
r2_train = r2_score(train_y, train_pred)
mae_test = mean_absolute_error(test_y, test_pred)
r2_test = r2_score(test_y, test_pred)
print(f'mae train: ', mae_train)
print('r2 train: ', r2_train)
print('-'*20)
print('mae test: ', mae_test)
print('r2 test: ', r2_test)
결과:
mae train: 0.2708489542877124
r2 train: 0.1820203764199536
--------------------
mae test: 0.27115793184807047
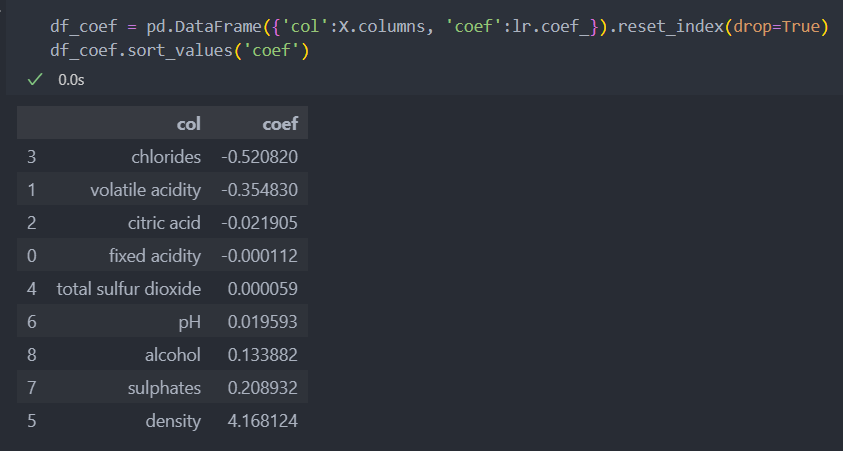
r2 test: 0.16415797208797311달라진 점은 density의 계수가 양수로 바뀌었다.
생각해볼 것은, 음에서 양으로 바뀌었다면 특징 2가지를 지우기 전에 모델의 해석이 바뀌었을 수 있다. 그리고 원래 양수였는데 음수로 잘못 나왔었는데 이제는 제대로 나온 것일 수도, 원래 음의 계수가 맞는데 지금이 잘못 나온 것일 수도 있다.
회귀 분석으로만 본다면, 계수가 높은 순으로 density, chlorides, volatile acidity, sulphates, alcohol 5개 정도가 등급에 영향을 크게 미치는 특징으로 관리를 해야 하는 인자라고 볼 수 있다.
하지만 분류 문제를 회귀 문제로 가져와서 보는 것도 의미가 있을 수는 있으나 너무 깊게 들어가지는 않겠다.
모델링 2 - 분류 분석
모델은 앙상블 계열의 LGBMClassifier과 RandomForestClassifier을 가지고 진행을 해보자.
from lightgbm import LGBMClassifier as LGB
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.metrics import classification_report
from sklearn.model_selection import ParameterGrid
from sklearn.metrics import f1_score, accuracy_score기존과 업샘플링을 진행한 데이터를 가지고 진행한 후, 비교를 위해 다시 업샘플링을 진행한다.
데이터를 다시 나누고,
X = df.drop(['quality', 'target'], axis=1)
Y = df['target']
train_x, test_x, train_y, test_y = train_test_split(X, Y, stratify=Y, random_state=29)다시 업샘플링을 진행한다.
# SMOTE 인스턴스 생성
oversampling_instance = SMOTE(k_neighbors = 3, sampling_strategy = {1:int(train_y.value_counts().iloc[0] / 2), # 기존의 -1 클래스의 크기에서 1/2 수 만큼 생성
0:train_y.value_counts().iloc[0]}) # 기존의 -1 인 클래스 수와 동일하도록
# 오버샘플링 적용
o_Train_X, o_Train_Y = oversampling_instance.fit_resample(train_x, train_y)
# ndarray 형태가 되므로 다시 DataFrame과 Series로 변환 (남은 전처리가 없다면 하지 않아도 무방)
o_Train_X = pd.DataFrame(o_Train_X, columns = X.columns)
o_Train_Y = pd.Series(o_Train_Y)
하이퍼 파라미터 튜닝을 진행을 할 것인데,
다음과 같이 인스턴스화 된 모델에 get_params() 속성을 확인하면, 조절해야 할 파라미터들과 그 default값을 보여준다.
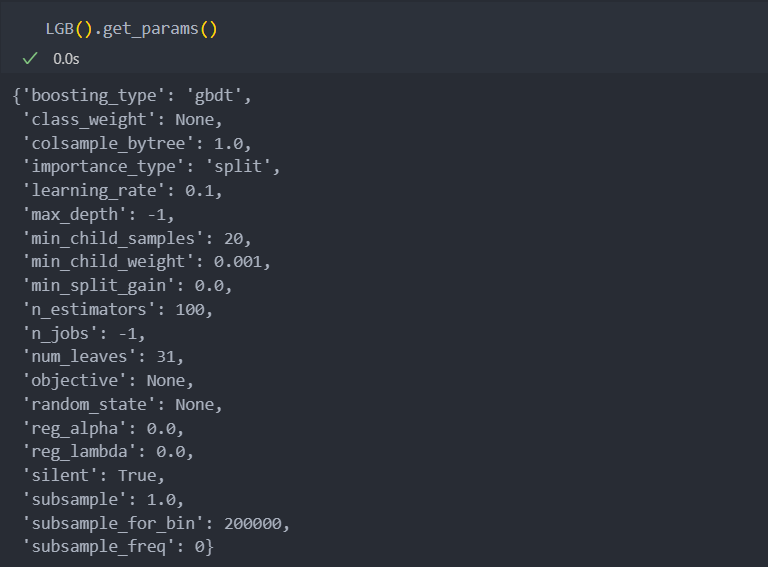
model_parameter_dict = dict()
RFR_param_grid = ParameterGrid({
'max_depth':[3, 5, 10, 15],
'n_estimators':[100, 200, 400],
'n_jobs':[-1]
})
LGB_param_grid = ParameterGrid({
'max_depth':[3, 5, 10, 15],
'n_estimators':[100, 200, 400],
'learning_rate':[0.05, 0.1, 0.2]
})
model_parameter_dict[RFC] = RFR_param_grid
model_parameter_dict[LGB] = LGB_param_gridf1 score를 평가지표로 삼아서 학습 및 예측을 하여 최적의 모델을 선택한다.
best_score = -1
iteration_num = 0
for m in model_parameter_dict.keys():
for p in model_parameter_dict[m]:
model = m(**p).fit(train_x.values, train_y.values)
pred = model.predict(test_x.values)
score = f1_score(test_y.values, pred)
acc = accuracy_score(test_y.values, pred)
if score > best_score:
best_score = score
best_model = m
best_parameter = p
accuracy = acc
iteration_num += 1
print(f'iter_num-{iteration_num}/{max_iter} => score : {score:.3f}, best score : {best_score:.3f} | acc : {accuracy}')최고 점수를 뽑아낸 모델과 파라미터, 그리고 점수는 다음과 같다.
lightgbm 모델은 데이터의 최소 샘플수가 1만개는 넘어갈 때 쓰는 것이 보통 좋은 성능을 낸다고 한다.

그리고 최적의 모델과 파라미터를 가지고 재학습하여 classification_report를 확인해보자.
# best 모델 학습
model = best_model(**best_parameter).fit(train_x.values, train_y.values)
train_pred = model.predict(train_x.values)
test_pred = model.predict(test_x.values)재현율이 조금 낮은 것을 볼 수 있다.
그런데 학습 데이터로 다시 돌려보았을 때 모두 1이 나온 것으로 봐서 과적합일 확률이 높아 보인다.
하지만 평가 데이터의 타겟값 0(일반 등급)의 값은 평가 지표가 좋은 것을 보면 약간의 과적합 정도일 것 같아 보이기도 한다.
이럴 때에는 LGBMClassifier보다는 RandomForestClassifier의 파라미터를 조금 더 세세하게 조정해서 성능을 조금 높여보는 것도 좋겠다.
LGBMClassifier의 방식이 부스팅 방식이라서 데이터의 샘플이 적으면 과적합이 될 우려가 있다.
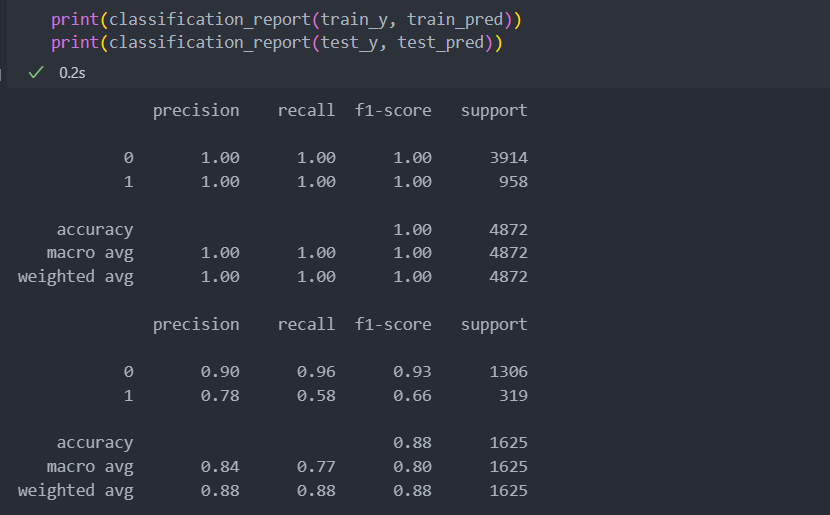
업샘플링한 데이터로 다시
업샘플링한 데이터로 f1 score로 최적의 모델을 확인한다.
best_score = -1
iteration_num = 0
for m in model_parameter_dict.keys():
for p in model_parameter_dict[m]:
model = m(**p).fit(o_Train_X.values, o_Train_Y.values)
pred = model.predict(test_x.values)
score = f1_score(test_y.values, pred)
acc = accuracy_score(test_y.values, pred)
if score > best_score:
best_score = score
best_model = m
best_parameter = p
accuracy = acc
iteration_num += 1
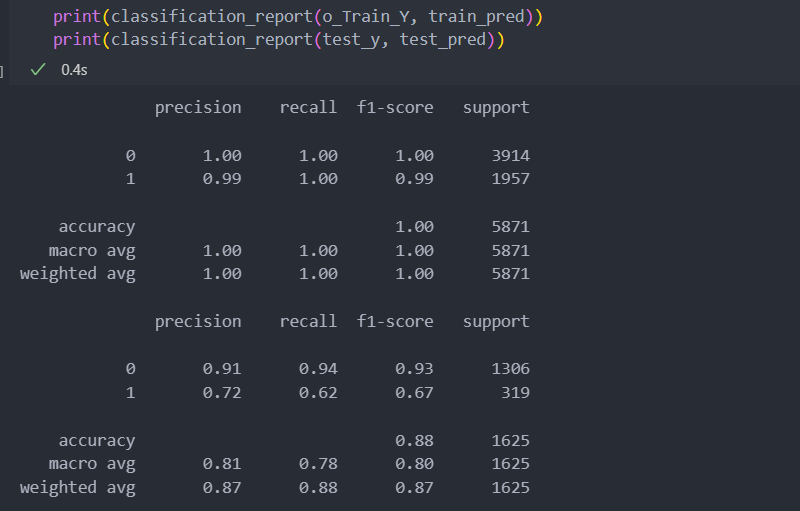
print(f'iter_num-{iteration_num}/{max_iter} => score : {score:.3f}, best score : {best_score:.3f} | acc : {accuracy}')그리고 확인을 해보면 평가 지표 accuracy는 0.7정도 하락했고 f1 score는 0.4정도 올라서 별차이가 없어보인다.

# best 모델 학습
model = best_model(**best_parameter).fit(o_Train_X.values, o_Train_Y.values)
train_pred = model.predict(o_Train_X.values)
test_pred = model.predict(test_x.values)하지만 아래의 classification_report를 보면 재현율(recall)이 타겟값 1(프리미엄 등급)에 대한 지표가 4정도 올라간 것을 볼 수 있다.
평가 지표 전체를 놓고 보면 분류에서는 업샘플링한 데이터로 학습한 모델이 조금 더 좋은 성능을 보인다고 해석할 수 있다.
아니면 lightgbm의 모델은 데이터의 샘플수가 많을 수록 좋은 성능을 낸다고 알려져 있으니,
업샘플링으로 인해 데이터가 많아져서 좋은 성능이 나왔다고 해석할 수도 있다.
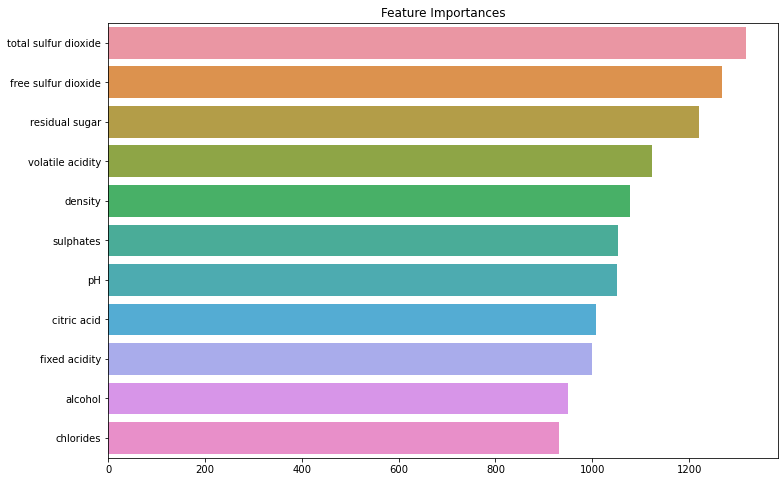
마지막으로 분류 모델을 통해서 타겟값을 예측할 때 중요한 변수는 다음과 같다.
ftr_importances_values = model.feature_importances_
ftr_importances = pd.Series(ftr_importances_values, index = X.columns)
ftr_top20 = ftr_importances.sort_values(ascending=False)[:21]
plt.figure(figsize=(12,8))
plt.title('Feature Importances')
sns.barplot(x=ftr_top20, y=ftr_top20.index)
plt.show()예상했던 것 보다 density의 중요도가 회귀 분석 때와는 다르게 낮고, 낮은 계수를 가지던 total sulfur dioxide 특징이 높아진 것을 볼 수 있다. 그리고 total sulfur dioxide와 free sulfur dioxide은 서로 상관 관계를 가지고 있었던 특징으로 적용되어 둘 다 같이 확률이 높다.
하지만 회귀 분석 때에는 r2의 설명력이 낮아서 신뢰하지 못하는 수준이라 판단이 되고,
해당 분류 분석의 지표가 더 신뢰할 수 있을 것이라 판단 된다.
기대효과
생산 공정에서 프리미엄 등급에 영향을 끼치는 인자를 판별하여 조금 더 신중하게 관리를 함으로써 프리미엄 등급의 생산을 증대시킬 수 있다.
이제 일정한 맛을 내는 프리미엄 등급의 와인 생산을 증대함으로써 영업 이익을 높일 수 있다.
