
문제 정의
주식 및 코인 투자가 열풍이 불면서 은행의 정기 예금 가입자가 감소하고 있으며
마케팅 비용 투자 대비 효율이 낮은 상황이다.
- 고객의 프로필 조건에 따른 가입률 비교를 통해 예금 상품 가입율을 높이려고 한다.
- 고객의 프로필 조건들을 분석하여 가입/미가입의 차이점을 파악하고 상품 가입을 예측한다.
- 고객의 어떤 프로필 조건들이 상품 가입에 큰 영향을 미치는 조건들인지 파악한다.
데이터 확인
- 고객마다 과거 진행한 마케팅에 대한 이력과, 현재 캠페인에서 수행된 데이터
- 연속형과 범주형 데이터 혼합
| age | job | marital | education | default | housing | loan | contact | month | day_of_week | duration | campaign | pdays |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 나이 | 직업 | 결혼 | 교육 | 신용카드 | 주택 | 대출 | 연락처 | 마지막 연락 월 | 마지막 연락 요일 | 통화시간 | 캠페인 기간동안 고객연락횟수 | 이전 캠페인 연락 후 지난일 |
| previous | poutcome | emp.var.rate | cons.price.idx | cons.conf.idx | euribor3m | nr,employed | y |
|---|---|---|---|---|---|---|---|
| 현재 캠페인 전에 연락횟수 | 이전 마케팅 결과 | 고용 변동률 | 소비자 물가 지수 | 소비자 신뢰 지수 | 유리보 3개월 비율 | 직원수 | 정기예금 가입여부 |
EDA & 전처리
기본 정보 확인
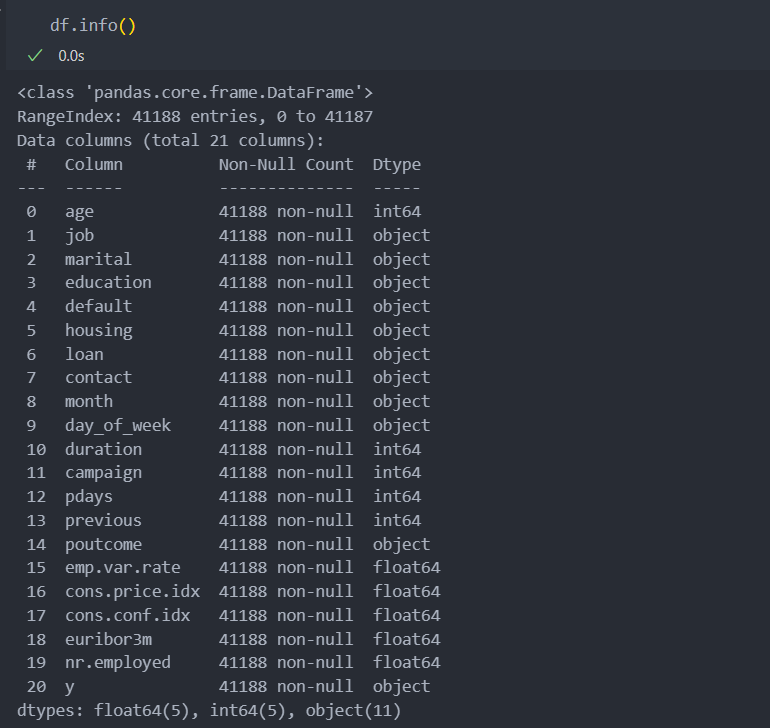
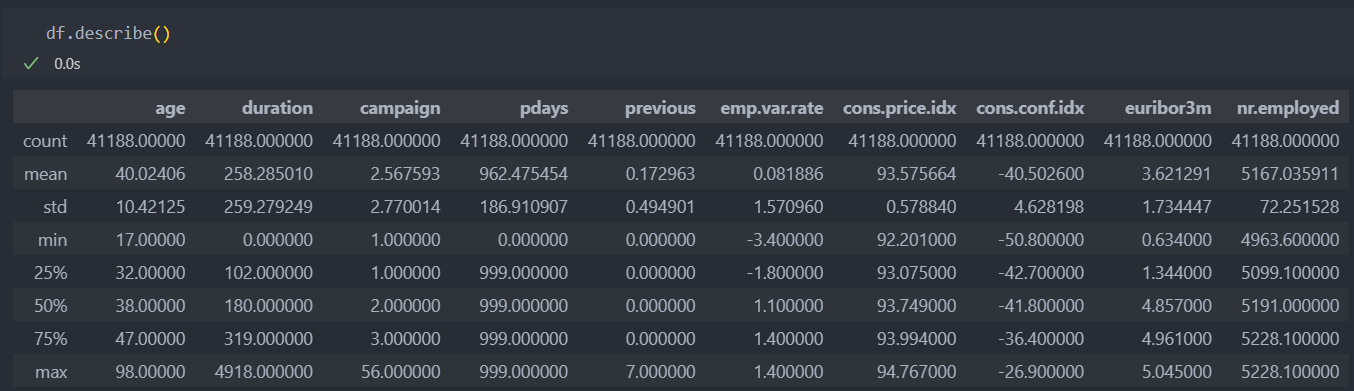
데이터의 shape은 41188, 21으로 되어 있다.
기본 정보와 통계량을 확인해보자.
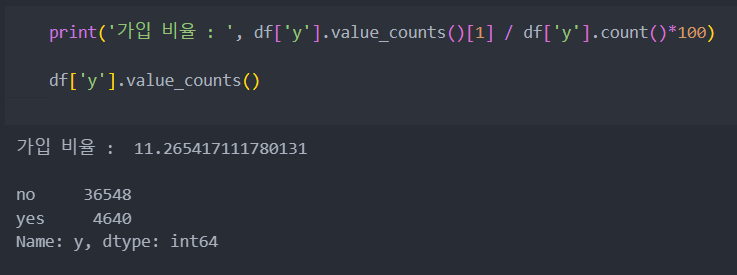
전체 데이터 중에서 가입 비율은 대략 11%정도로 생각보다 높은 수치를 보여준다.
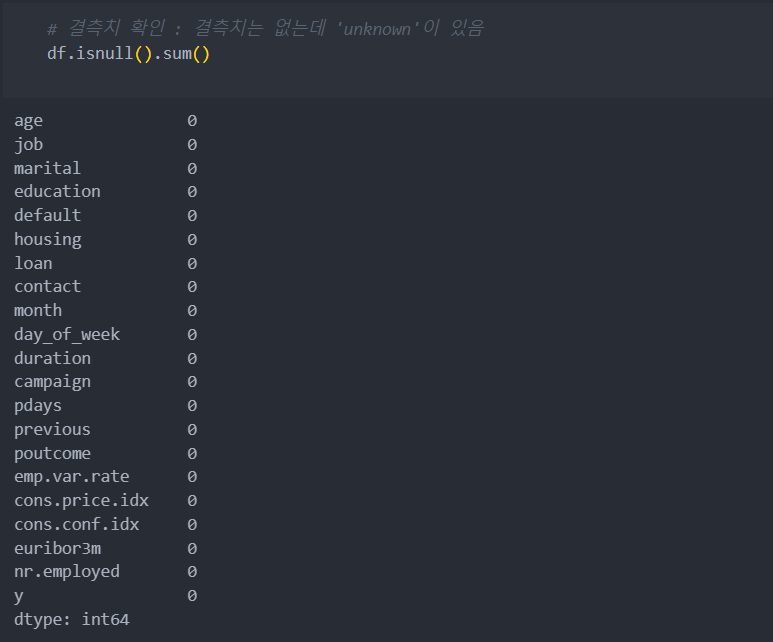
그리고 결측치는 없으나, 정보가 없는 경우 'unkonwn'으로 처리 되어 있다.
숫자형/문자형 데이터 확인
추후 분석에 용이하도록 분리시켜 놓자.
num_list, str_list = [], []
for i in df.columns:
if df[i].dtypes == 'O':
str_list.append(i)
else:
num_list.append(i)-
숫자형
['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'day_of_week', 'poutcome', 'y'] -
문자형
['age', 'duration', 'campaign', 'pdays', 'previous', 'emp.var.rate', 'cons.price.idx', 'cons.conf.idx', 'euribor3m', 'nr.employed']
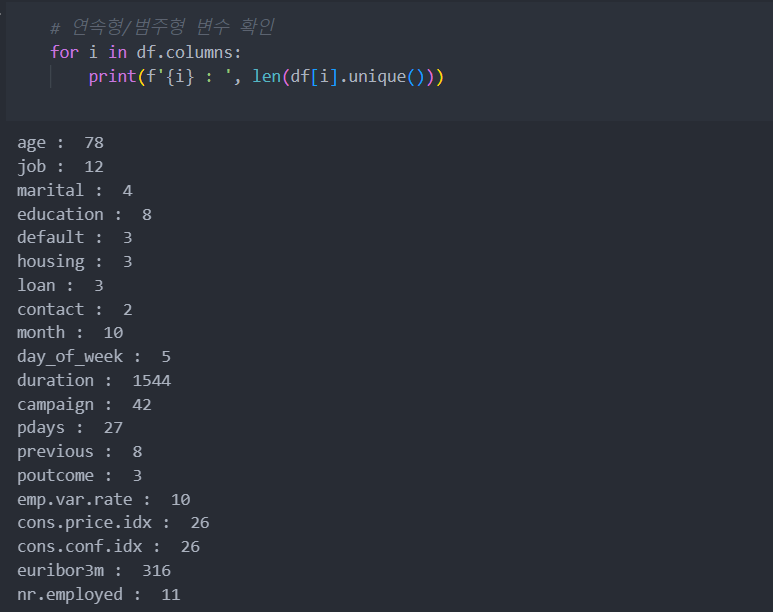
연속형/범주형 변수 확인
숫자형 변수라고 해서 반드시 연속형 변수는 아니므로 데이터를 꼼꼼히 확인할 필요가 있다.
각 특징(컬럼)별 데이터들의 범주는 다음과 같이 대략적으로 확인 된다.
대략 값이 8이하인 값들은 범주형 변수들이라고 파악할 수 있다.
치우침 변수 확인
변수들이 얼마나 치우쳐있는지 확인해보자.
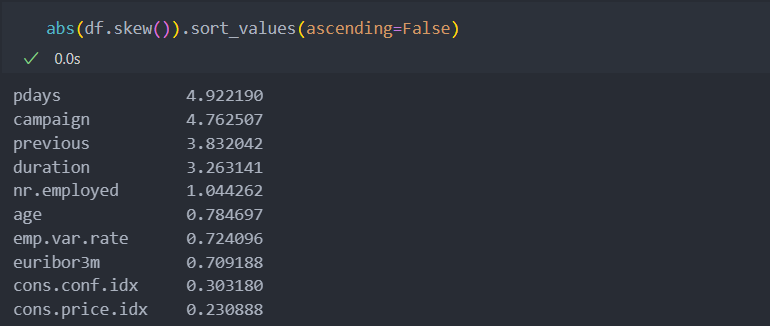
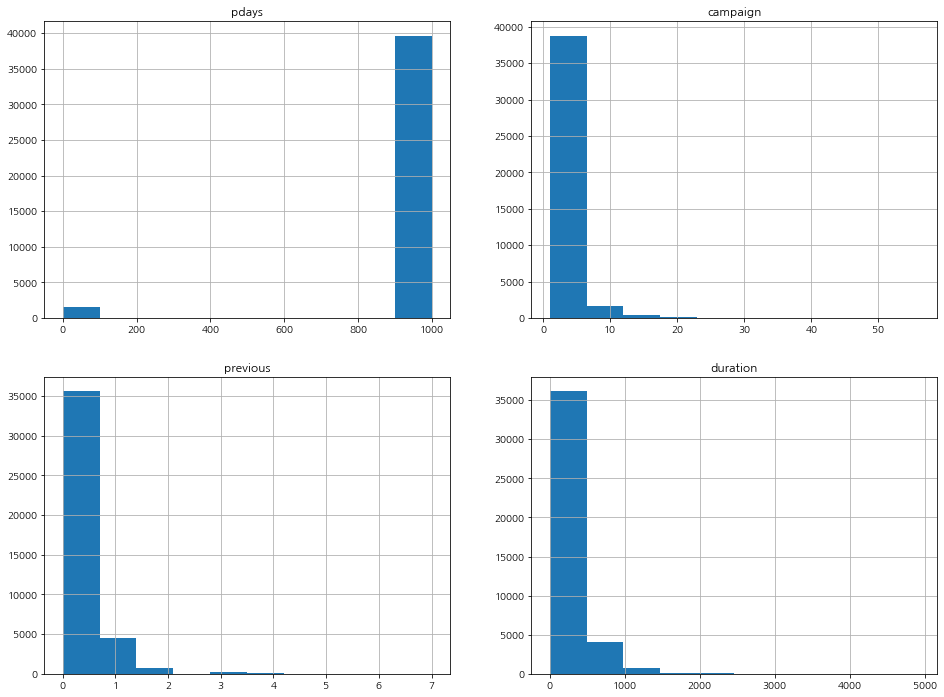
그리고 그래프를 그려 시각화를 해보면, 치우쳐이다고 해석하기 보다는 대부분의 값을 제외한 값들은 이상치라고 보는 것이 더 합당할 수 있을 것 같다.
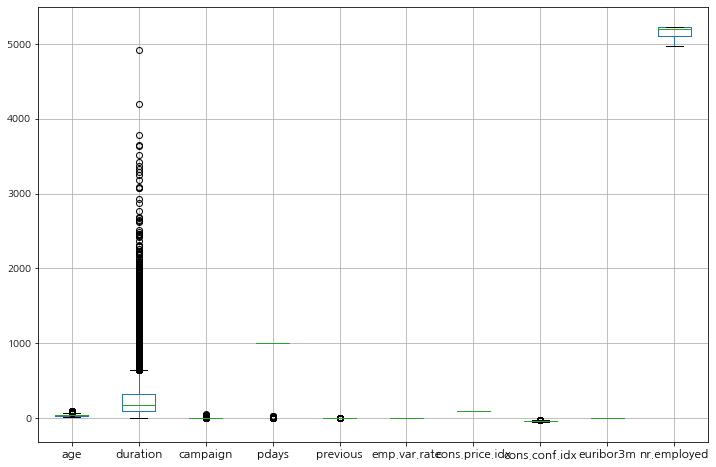
이상치 확인
이상치는 박스 플롯으로 확인해보자.
duration(통화 시간) 아무래도 가입을 원하는 고객들에 한해서 길어지는 경향을 보인다고 예상할 수 있다. 가입을 원하지 않는다면 통화를 길게 할 필요성이 없기 때문이다.
스케일이 다른 값이 있어 분리하여 다시 보자.
나이는 제외하고 가입 전 연락 횟수('campaign')도 연속형 변수라고 보기에는 어려워보인다. 이는 연락 횟수에 따른 가입율을 확인해 보아야 할 것 같다.
딱히 제외시킬 이상치는 보이지 않는다.
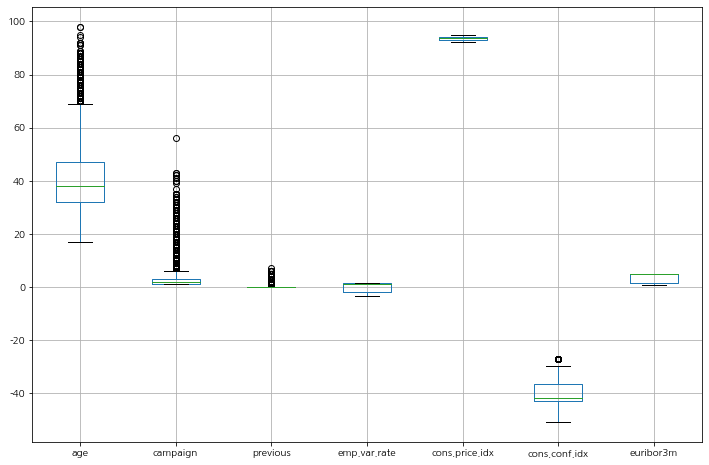
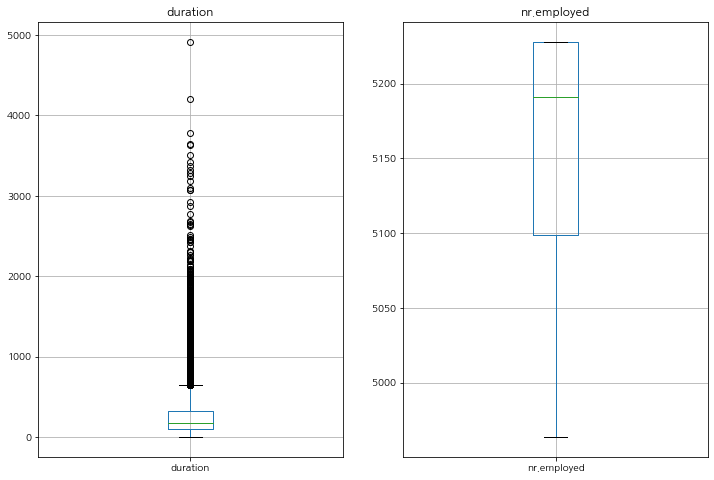
가입/비가입 기준 데이터 비교
가입과 비가입으로 나눠 데이터를 확인해보자.
catplot
범주형 변수(가입/비가입)를 기준으로 데터를 비교할 때, catplot로 시각화를 하면 유용하게 데이터를 확인할 수 있다.
모든 특징을 가져와서, 비교할만한 것들을 골라내서 보도록 하자.
for i in df.columns:
sns.catplot(x=f"{i}", hue="y", kind="count",palette="pastel", edgecolor=".6",data=df, aspect=2)
plt.title(f'{i}', fontsize=16)
plt.gcf().set_size_inches(25, 3)
plt.xticks(fontsize=16)
plt.show()각 특징(컬럼)별 비교를 진행해보자. 연속형 데이터에서는 비교하기 어렵다.










데이터 기반 상품 가입 예측
가입률을 데이터를 기반으로 하여 특징(컬럼) 좀 더 자세하게 들여다보고, 그것을 바탕으로 가입률을 예측해보자.
직업별
admin, blue-collar가 사람이 가장 많은데, 두 그룹에 대한 가입 전략도 다르게 접근해야 하는 것은 아닌지 생각해 봐야 한다.
# 직업별로 가입 유무 나누고
df_job = df.groupby(['job', 'y'], as_index=False)['age'].count().rename(columns={'age':'count'})
# 'yes', 'no'를 컬럼으로 만들기
df_job = pd.pivot_table(df_job, index='job', columns='y', values='count').reset_index()
# 직업별 가입 비율 확인
df_job['sign_ratio'] = round((df_job['yes'] / (df_job['yes'] + df_job['no'])) * 100, 1)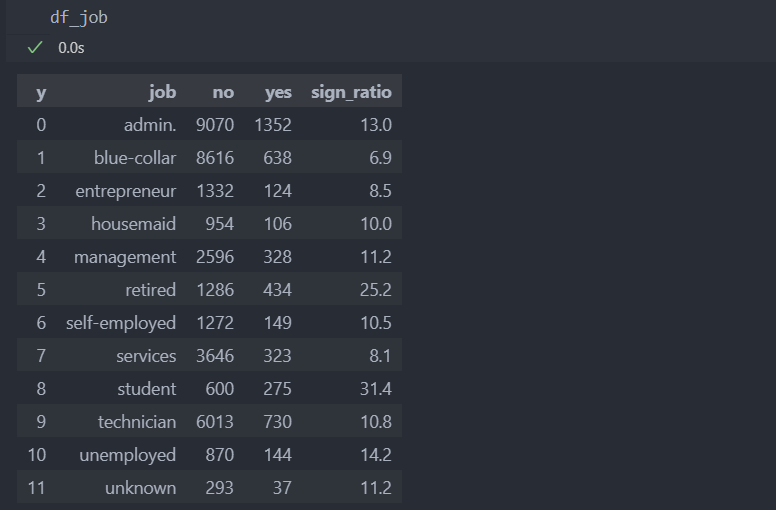
그래프로 그려보면 다음과 같다.
의외로 직장을 다니는 사람보다, 은퇴했거나 학생, 실직자들의 예금 가입 비율이 상대적으로 조금 더 높다.
직업이 없어 예금에 압박을 받는 사람들이 조금 더 가입을 할 비율이 높다고 판단할 수도 있을 것 같아 보인다.
그런데 학생의 경우는 전체에서 학생의 비율이 높지 않다는 것도 확인할 수 있다.
sns.catplot(data=df_job, x='job', y='sign_ratio', kind='bar', palette='ch:.25', aspect=2)
plt.gcf().set_size_inches(25, 6)
plt.xticks(fontsize=16)
plt.show()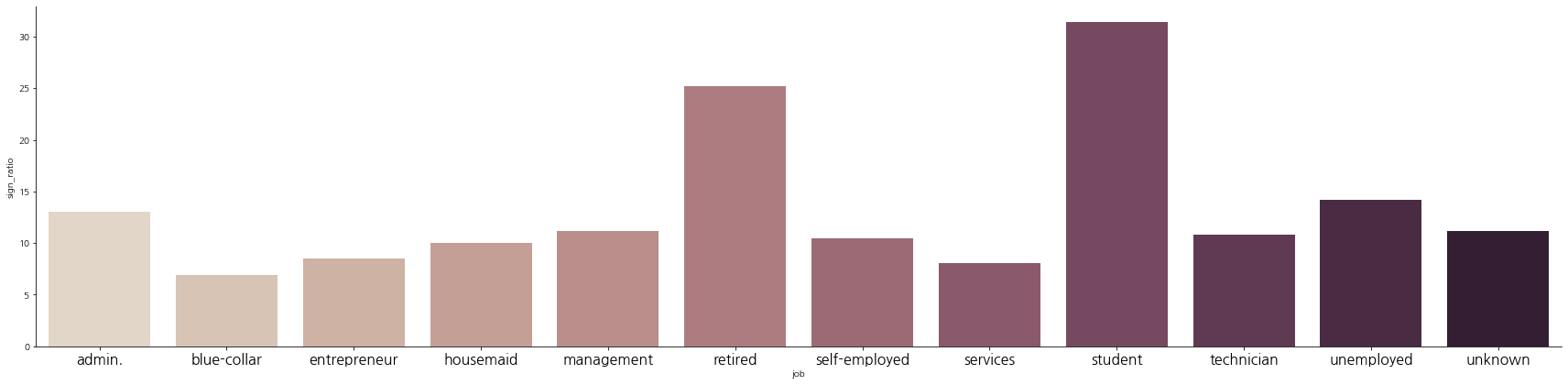
결혼
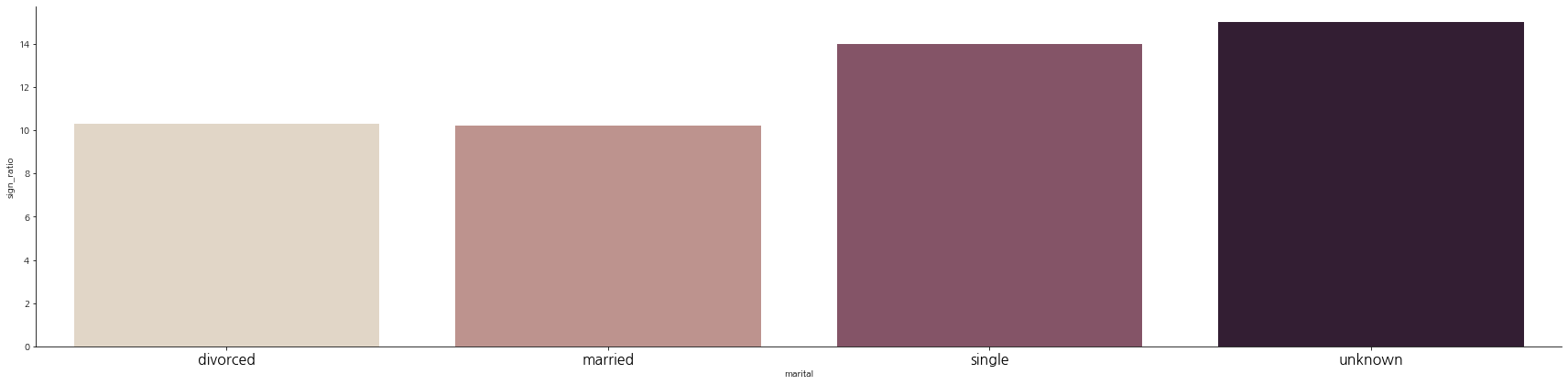
나머지 특징(컬럼)들도 진행해보자.
비율
각 케테고리별로 가장 높은 가입 비율을 가지는 '군'만 따로 확인해보자.
여기서 유의해야 할 점은 범주 변수 중에서 비율은 높지만 그룹 자체의 수가 적어 대표성을 띄지 못하는 경우도 있으니 확인작업을 진행해야 한다.
특징별로 하나씩 보면서 확인 작업을 진행해보자.
i = 'housing'
# 1단계
df_gp=pd.DataFrame(df['y'].groupby(df[i]).value_counts())
df_gp.columns=['cnt']
df_gp=df_gp.reset_index()
# 2단계
df_gp = pd.pivot_table(df_gp, # 피벗할 데이터프레임
index = i, # 행 위치에 들어갈 열
columns = 'y', # 열 위치에 들어갈 열
values = 'cnt') # 데이터로 사용할 열
# 3단계
df_gp = df_gp.reset_index()
# 4단계
df_gp['sign_ratio'] = round((df_gp['yes'] / (df_gp['yes'] + df_gp['no'])) * 100,1)
df_gp=df_gp.sort_values(by=['sign_ratio'], ascending=False)
df_gp아래와 같이 결혼 관련 정보에서 'unknown'이 비율이 높지만 대표성을 띈다고 말할 수는 없다.
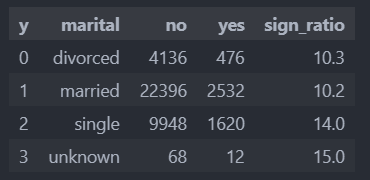
그리고 기존의 가입률 11% 보다는 높은 비율을 가지는 그룹이어야 한다.
'housing'의 경우에는 비율이 11.6%로 유의미한 특징은 아닌 것으로 보인다.
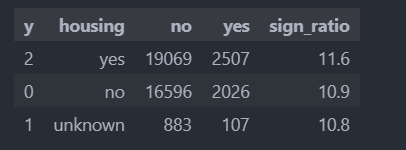
'contact'의 경우는, 아래와 같이 '집전화'가 아닌 '휴대젼화'로만 텔레마케팅을 해야겠다는 유의미한 결과가 도출 되기도 한다.
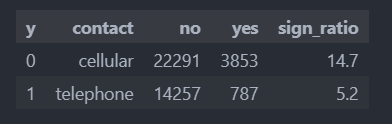
월 같은 경우 '3'월의 경우 가입률이 높고, '5'월에 가입률이 현저히 낮은 것을 확인할 수 있다.
40% 넘게 가입한 월을 집중적인 마케팅 기간으로 정해야 할 것으로 보인다.
하지만 40% 넘게 가입한 월은 마케팅 수 자체가 낮은 경향이 있다.(특별한 이유가 있는지 확인작업을 해야한다)
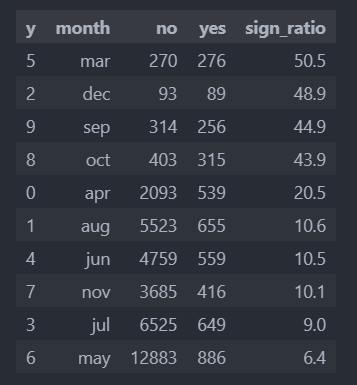
확인한 것을 바탕으로, 가장 높은 비율을 가지고 유의미한 결과를 보일 수 있는 그룹만 묶어서 확인해보자.
먼저 카테고리별로 가장 높은 비율을 가지는 변수명을 dict()자료형에 담는다.
# key:카테고리, values:가입 비율이 높은 군
df_dict = {}
for i in str_list[:-1]:
# 카테고리, 가입유무로 groupby
tmp = df.groupby([f'{i}', 'y'], as_index=False)['age'].count().rename(columns={'age':'count'})
tmp = pd.pivot_table(tmp, index=f'{i}', columns='y', values='count').reset_index()
tmp['sign_ratio'] = round((tmp['yes'] / (tmp['yes'] + tmp['no'])) * 100, 1)
df_dict[i] = tmp.sort_values(by='sign_ratio', ascending=False).iloc[0, :].values[0] # 가장 높은 비율을 가진 값의 이름
결과:
df_dict
{'job': 'student',
'marital': 'unknown',
'education': 'illiterate',
'default': 'no',
'housing': 'yes',
'loan': 'no',
'contact': 'cellular',
'month': 'mar',
'day_of_week': 'thu',
'poutcome': 'success'}그리고 유의미하다 생각된 카테고리들만 사용하여(타겟 정하기) 가입 비율을 비교하며 확인해보자.
best_ratio = df[
(df['job'] == df_dict['job']) |
# (df['marital'] == df_dict['marital']) | # 사용 X
# (df['education'] == df_dict['education']) | # 사용 X
# (df['default'] == df_dict['default']) | # 사용 X
# (df['housing'] == df_dict['housing']) | # 사용 X
# (df['loan'] == df_dict['loan']) | # 사용 X
(df['contact'] == df_dict['contact']) |
(df['month'] == df_dict['month']) |
(df['day_of_week'] == df_dict['day_of_week']) |
(df['poutcome'] == df_dict['poutcome'])
]가입률이 높은 타겟만 선별하여 비율을 보면 약 14%로, 기존보다 가입률이 높아진 것을 볼 수 있다.

모델링
모델 선정 및 데이터 분리
연속형/범주형이 혼합되어 있고 데이터 샘플도 충분하여 LGBMClassifier와 RandomForestClassifier 모델을 사용하여 진행한다.
from lightgbm import LGBMClassifier as LGB
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.preprocessing import LabelEncoder as LE
from sklearn.model_selection import train_test_split
from sklearn.model_selection import ParameterGrid
from sklearn.metrics import f1_score, accuracy_score, precision_score, recall_score, classification_report라벨 데이터가 문자 형태로 되어 있어서 숫자형태로 변환한다.
# 라벨 데이터 수치형으로 변환
data['y']=np.where(data['y']=='yes', 1, 0)
data['y'].value_counts()문자로 되어있는 데이터를 LabelEncoder를 사용하여 역시 수치형으로 변환시킨다.
for col in str_list: # 미리 지정된 문자형 컬럼 리스트
le = LE() # 인스턴스
data[col] = le.fit_transform(data[col]) # 기존 문자 -> 숫자형 변환라벨 데이터를 분리시키고 학습/평가 데이터로도 분리시킨다.
X = data.drop(['duration', 'y'], axis=1)
Y = data['y']
train_x, test_x, train_y, test_y = train_test_split(X, Y, stratify=Y)
train_x.shape, train_y.shape, test_x.shape, test_y.shape하이퍼 파라미터 조정
model_parameter_dict = dict()
# RandomForestClassifier 조정
RFC_param_grid = ParameterGrid({
'max_depth':[3, 5, 10, 15],
'n_estimators':[100, 200, 400],
'n_jobs':[-1]
})
# LGBMClassifier 조정
LGM_param_grid = ParameterGrid({
'max_depth':[3, 5, 10, 15],
'n_estimators':[100, 200, 400],
'learning_rate':[0.05, 0.1, 0.2]
})
model_parameter_dict[RFC] = RFC_param_grid
model_parameter_dict[LGB] = LGM_param_grid학습
f1 score를 학습 평가 지표로 설정하고 모델을 학습하여 최종 모델을 선정한다.
best_score = -1
iteration_num = 0
for m in model_parameter_dict.keys():
for p in model_parameter_dict[m]:
model = m(**p).fit(train_x.values, train_y.values)
pred = model.predict(test_x.values)
score = f1_score(test_y.values, pred)
if score > best_score:
best_score = score
best_model = m
best_parameter = p
iteration_num += 1
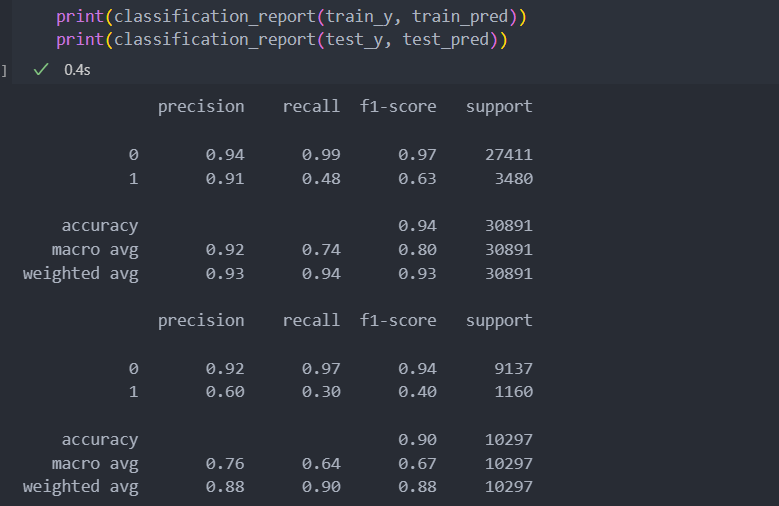
print(f'iter_num-{iteration_num}/{max_iter} => score : {score:.3f}, best score : {best_score:.3f}')최종 모델 선택 및 예측 진행
model = best_model(**best_parameter)
model.fit(train_x, train_y)
train_pred = model.predict(train_x)
test_pred = model.predict(test_x)재현율의 지표가 좋아 보이지는 않지만, 타겟 마케팅에는 정밀도가 조금 더 중요한 지표로 작동을 할 것이다.
타겟 마케팅을 예측하고 가입할 것이라 예측된 상대를 타겟으로 마케팅을 진행할 것이기 때문이다.
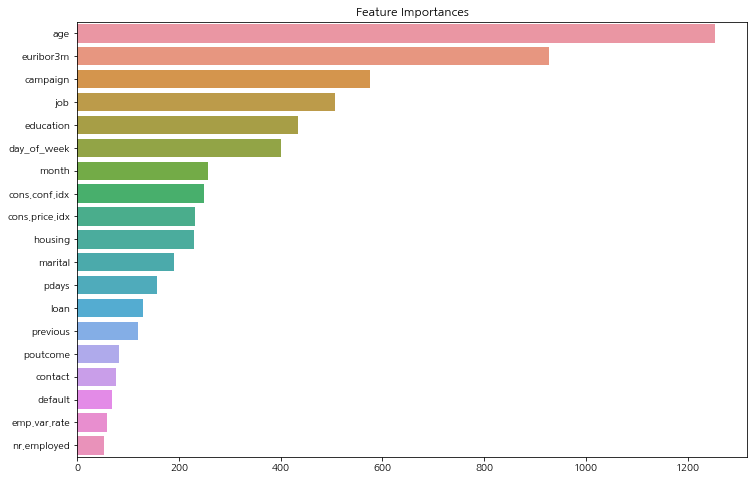
모델 결과에 영향을 준 특징들을 보면 아래와 같다.
나이 컬럼이 모델이 예측을 할 때 가장 많은 영향을 준 것으로 나타난다. 나이의 범위를 청년층, 장년층 등으로 범주화시켜서 재탐색을 해 볼 필요성이 보인다.
연속형 변수에 대한 가입/비가입 비율을 비교해 볼 필요성이 있다.
그 다음이 경제 지표로 유리보 3개월 비율이다.(유리보 : 유로존 은행이 유로 화폐 시장에서 다른 은행에 무담보 자금을 빌려주는 이자율)
기대 효과
프로필 조건 중 상품 가입에 영향을 미치는 조건을 파악하여 마케팅 범위를 줄임으로써
가입 확률이 높은 사람들 위주로 타겟 마케팅을 하여 상품 가입율을 높일 수 있다.
더불어 상품 가입 모델을 사용하여 가입이 가능한 사람들만 타겟 마케팅하여 마케팅 비용을 낮추거나, 효율을 높인다.
