
문제 정의
신용카드 대금의 채무 불이행 고객으로 인한 손실이 늘어나고 있는 상황이다.
신용카드 채무 불이행이 예상되는 고객들을 예상 및 한도를 관리하여 손실을 방지하려 한다.
데이터 확인
소스코드 : GitHub
고객 ID별 카드 상세
-
ID LIMIT_BAL SEX EDUCATION MARRIAGE AGE 고객 아이디 신용한도 성별(1-남성, 2-여성) 교육수준(1-대학원, 2-대학교, 3-고등학교, 4-기타, 5-모름, 6-모름) 결혼(1-기혼, 2-독신, 3-기타) 나이 -
PAY_0 PAY_2 PAY_3 PAY_4 PAY_5 PAY_6 05년9월 상환상태(-2-무소비, -1-정액 결제, 0-리볼빙크레딧, 1-한달 지연, ..., 9-9개월 지불지연) 05년8월 상환상태 05년7월 상환상태 05년6월 상환상태 05년5월 상환상태 05년4월 상환상태 -
BILL_AMT1 BILL_AMT2 BILL_AMT3 BILL_AMT4 BILL_AMT5 BILL_AMT6 05년9월 청구서 금액 05년8월 청구서 금액 05년7월 청구서 금액 05년6월 청구서 금액 05년5월 청구서 금액 05년4월 청구서 금액 -
PAY_AMT1 PAY_AMT2 PAY_AMT3 PAY_AMT4 PAY_AMT5 PAY_AMT6 05년9월 지불금액 05년8월 지불금액 05년7월 지불금액 05년6월 지불금액 05년5월 지불금액 05년4월 지불금액 -
default payment next month 채무 불이행 여부
EDA & 전처리
기본 정보 확인
수치형 데이터로 구성이 되어 있다.
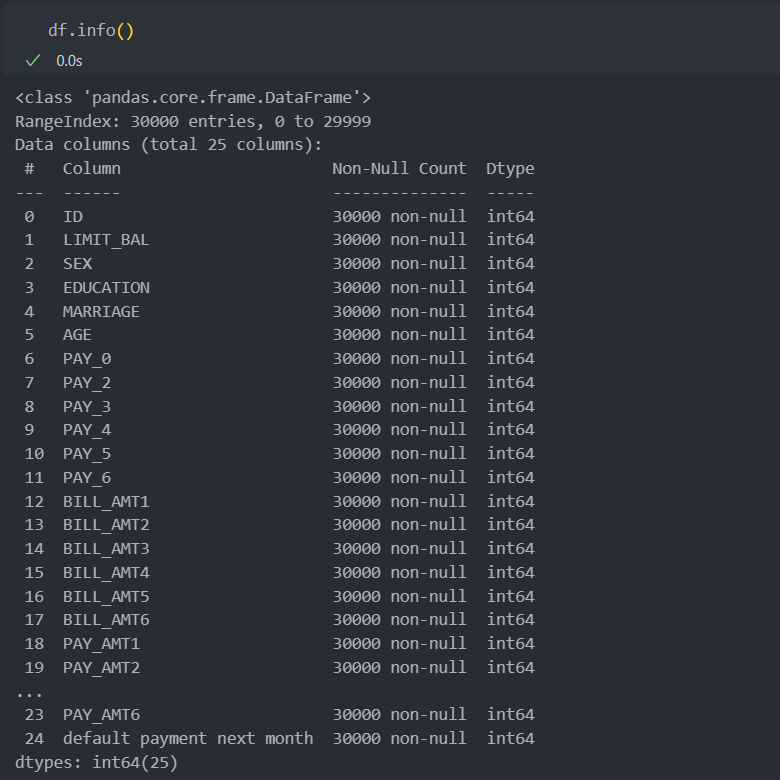
수치형 데이터이지만 범주형 데이터와 연속형 데이터가 혼재되어 있는 것으로 확인이 된다.
금액으로 추정되는 특징(컬럼)들은 최소값과 최대값의 차이가 많이 나는 것도 확인이 된다.
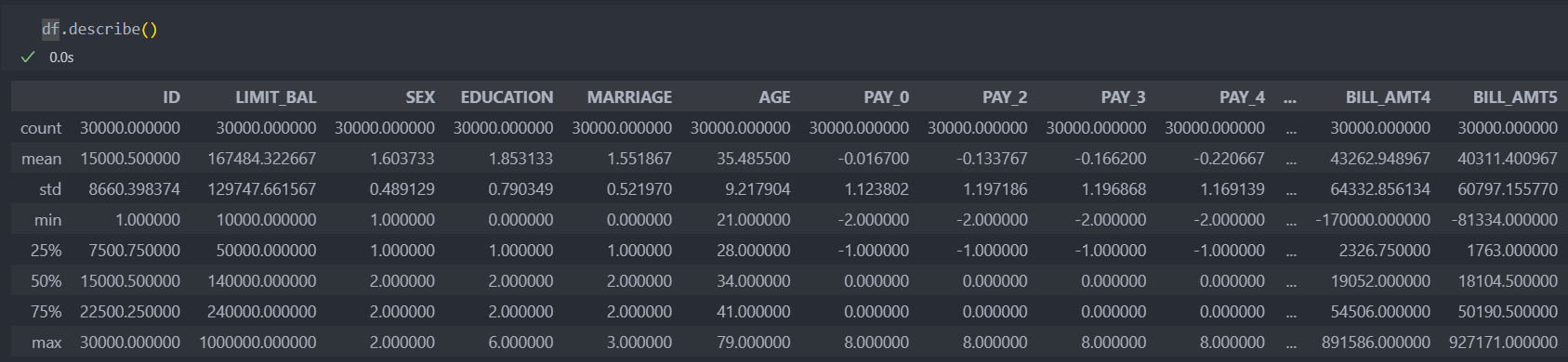
그리고 금액적인 부분에서, 청구서 및 지불 금액에서 데이터의 쏠림 현상이 나타난다.
결측치는 없다.
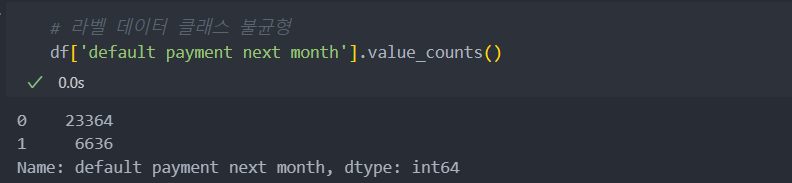
라벨 데이터의 클래스 불균형이 보이고,
채무 불이행의 데이터는 전체 데이터의 22% 정도 확인이 된다.

모든 컬럼에 대한 채무 불이행 클래스의 비율을 catplot으로 확인해보자.
변수들 중에서 범주형 변수에 대한 채무 불이행을 상세 확인할 수 있다.
대표적으로 몇 가지를 확인하고,
후에 특징(컬럼)별 상세 확인 때 유용할 것이라 생각된다.
for col in df.columns:
sns.catplot(x=f"{col}", kind="count",palette="pastel", hue='default payment next month', edgecolor=".6",data=df)
plt.title(f'{col}')
plt.gcf().set_size_inches(25, 3)
plt.show()성별

학력별

결혼 유/무

나이별

범주형 변수 통합
학력에 대한 변수는 0, 4, 5, 6은 '기타'와 '알 수 없음'에 대한 변수로써, 데이터도 적고 카테고리 범위만 넓어지기에 통합시킨다.
- 교육수준(1-대학원 2-대학 3-고등학교 4-기타)
df['EDUCATION'] = np.where((df['EDUCATION']>=4) | (df['EDUCATION']==0) , 4, df['EDUCATION'])
청구금액 대비 지불 수준 확인
청구금액 대비하여 지불 수준이 낮다면 연체일 확률이 높을 것으로 예상된다.
예로 청구금액이 100만원인데 50만원의 지불 수준이라면, 지속될 시 연체가 될 확률이 높다.
ID별 청구금액과 지불금액 데이터를 생성하고, 총 청구금액 대비 지불 수준을 확인하는 컬럼을 생성하여 확인해보자.
# 청구 수준 대비 지불 수준 확인
# 필요 컬럼
df[['ID', 'BILL_AMT1', 'PAY_AMT1', 'BILL_AMT2', 'PAY_AMT2', 'BILL_AMT3', 'PAY_AMT3', 'BILL_AMT4', 'PAY_AMT4', 'BILL_AMT5', 'PAY_AMT5', 'BILL_AMT6', 'PAY_AMT6']]
# 과거 6개월 동안 총 청구 대비 지불 수준을 확인하기 위해 새로운 col 생성
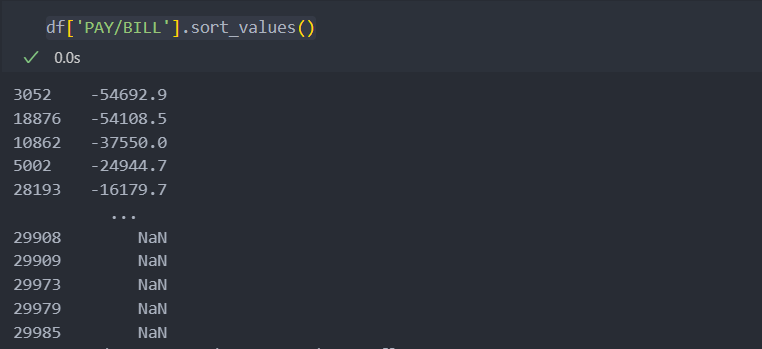
df['PAY/BILL'] = round(((df['PAY_AMT1'] + df['PAY_AMT2'] + df['PAY_AMT3'] + df['PAY_AMT4'] + df['PAY_AMT5'] + df['PAY_AMT6'])
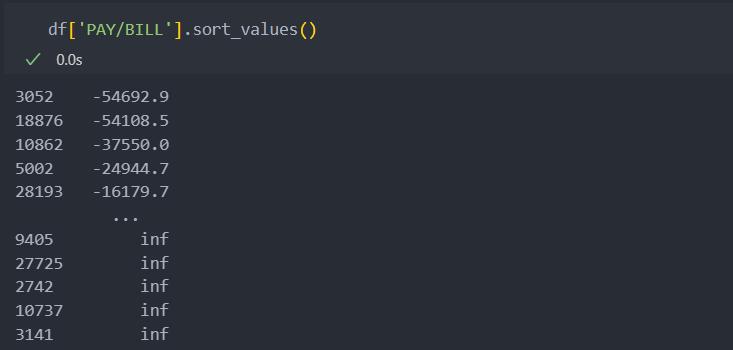
/ (df['BILL_AMT1'] + df['BILL_AMT2'] + df['BILL_AMT3'] + df['BILL_AMT4'] + df['BILL_AMT5'] + df['BILL_AMT6'])) * 100, 1)새로운 컬럼은 청구금액 대비 지불금액으로 나눈 것으로 청구된 금액이 없거나 지불 금액이 없다면, 즉 분자에 0이나 분모에 0이 있을 경우 NaN값 혹은 inf값이 생기기에 0으로 대체한다.
# NaN, inf값 0으로 대체
df['PAY/BILL'] = df['PAY/BILL'].replace([np.inf, -np.inf], np.nan)
df['PAY/BILL'] = df['PAY/BILL'].fillna(0)그리고 데이터 상의 6개월이기에 데이터 6개월 이전의 데이터에 대한 청구 혹은 지불 금액이 계속 쌓여왔을 것이기에,
그러한 데이터들은 이상치 데이터라 보고 처리를 해준다.
# 이상 Data 처리(0 ~ 100의 범위를 벗어나는 데이터 처리)
df['PAY/BILL'] = np.where(df['PAY/BILL']>100, 100, df['PAY/BILL'])
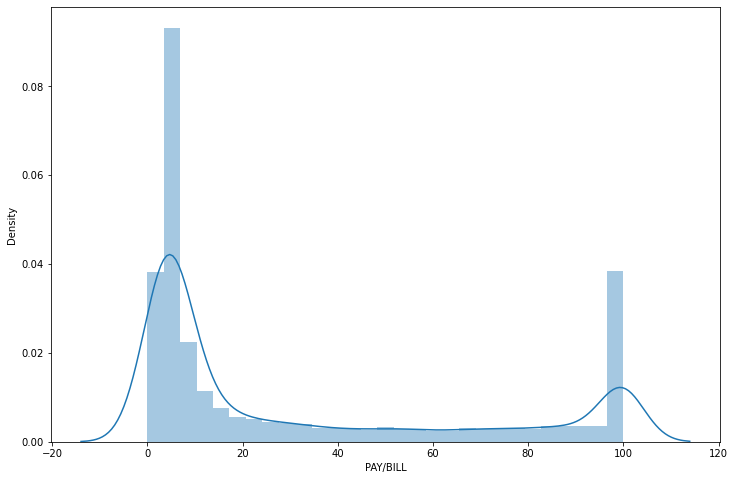
df['PAY/BILL'] = np.where(df['PAY/BILL']<0, 0, df['PAY/BILL'])마지막으로 데이터의 분포를 확인해보면,
청구금액 대비해서 지불을 매우 못하거나 매우 잘하는 데이터로 양분되는 것을 볼 수 있다.
범주형 컬럼별 채무 비율 확인
범주형 변수들의 카테고리별 채무 비율을 확인하는 함수를 작성하여 확인해보자.
def get_ratio(col_idx):
# 확인하려는 컬럼 groupby
df_profile=pd.DataFrame(df['default payment next month'].groupby(df[col_idx]).value_counts())
df_profile.columns=['cnt']
df_profile=df_profile.reset_index()
# pivot_table 적용
df_profile = pd.pivot_table(df_profile, # 피벗할 데이터프레임
index = col_idx, # 행 위치에 들어갈 열
columns = 'default payment next month', # 열 위치에 들어갈 열
values = 'cnt') # 데이터로 사용할 열
# reset index
df_profile = df_profile.reset_index()
df_profile.columns.names=['']
# 채무 비율 확인
df_profile['sign_ratio'] = round((df_profile.iloc[:,2] / (df_profile.iloc[:,1] + df_profile.iloc[:,2])) * 100,1)
df_profile=df_profile.sort_values(by=['sign_ratio'], ascending=False)
df_profile
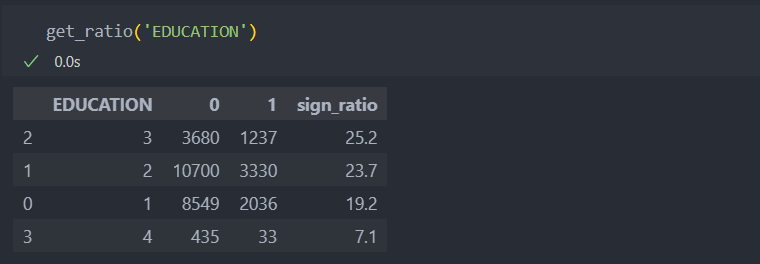
return df_profile학력
학력이 낮을수록 채무율이 낮아지는 경향이 있다(평균 채무율 : 22%)
성별
성별이 남성인 경우가 채무율이 더 높은 경향이 있다.

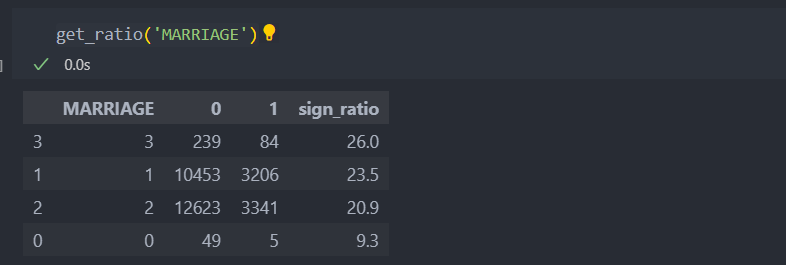
결혼
0, 4는 데이터가 적어서 유의미하지 않아보이고,
1 기혼의 채무율이 2 독신보다 높은 경향을 보인다.
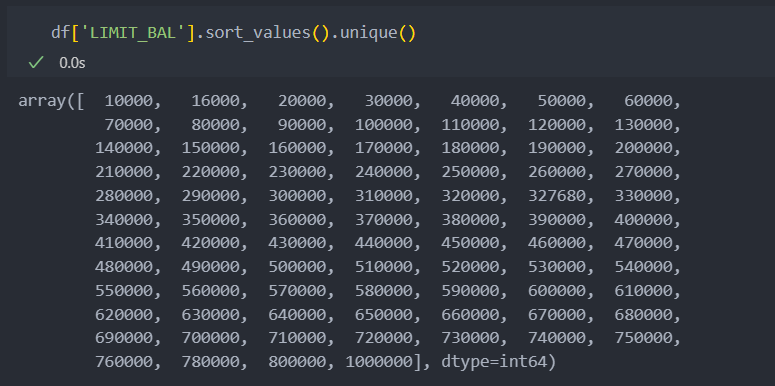
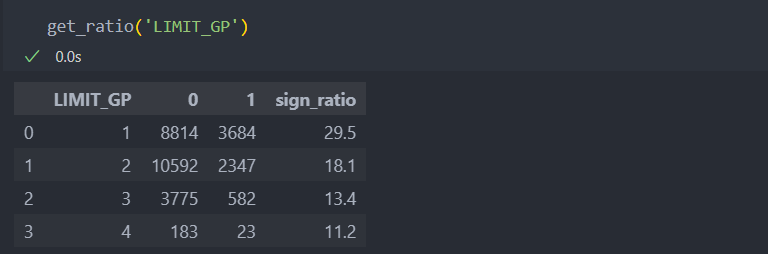
신용한도
연속형 변수인 신용한도를 가지고 총 4개의 그룹으로 나눠 범주형 변수로 변환한 뒤에 채무비유을 확인해보자.
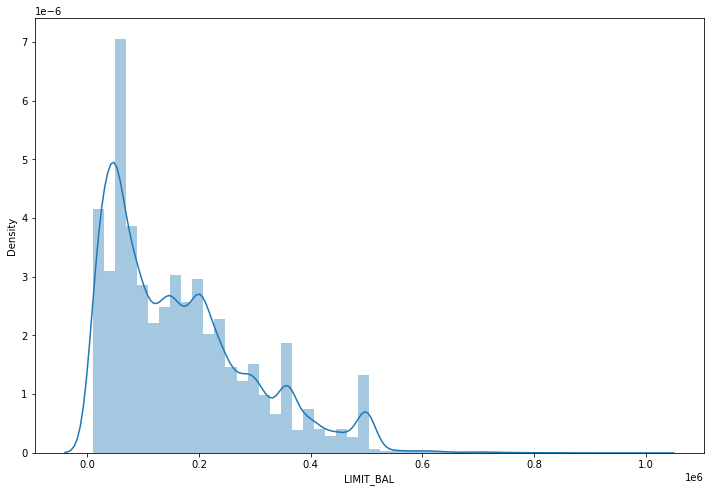
먼저 신용한도의 분포를 살펴보자.
대부분 1만에서 50만 사이에 대부분의 값이 몰려 있는 것을 확인할 수 있다.
0부터 차트 1칸당 2만이라고 보여진다면, 10만까지에 가장 큰 값이 몰려있고 그 다음이 30만까지 값이 떨어지다가 50만 이후로 밀도값이 많이 떨어지는 것을 확인할 수 있다.
구간 1-10, 10-30, 30-50, 50이상으로 4그룹으로 범주형 변수를 생성한다.
# Numeric(연속형) 변수의 구간화 작업
# 100,000 이하, 100,000 초과 300,000 이하, 300,000 초과 500,000 이하, 500,000 초과(4 Group)
df['LIMIT_GP'] = np.where (df['LIMIT_BAL'] <= 100000, 1,
np.where(df['LIMIT_BAL'] <= 300000, 2,
np.where(df['LIMIT_BAL'] <= 500000, 3, 4)))그리고 위에서 생성한 비율 함수에 다시 적용시키면 아래와 같다.
신용한독 작을 수록 연체 비율이 크다는 것을 확인할 수 있다.
모델링
범주형 변수들, 그리고 금액에 대한 채무 불이행 여부를 확인하기 위해 Tree 계열의 앙상블 모델 RandomForestClassifier사용한다.
그리고 채무 이행/불이행의 이진 분류기의 성능을 확인하기 위해 평가 지표로 roc_auc_score를 사용한다.
데이터 나누기
# 라벨 데이터 분리
X = df.drop(['ID', 'default payment next month'], axis=1)
Y = df[['default payment next month']]
# 학습/평가 데이터 분리
train_x, test_x, train_y, test_y = train_test_split(X, Y, stratify=Y)하이퍼 파라미터
# RandomForestClassifier의 하이퍼 파라미터
param_grid = ParameterGrid({
'max_depth':[3, 5, 10, 15, 30, 50, 100],
'n_estimators':[100, 200, 400, 600, 800],
'random_state':[29, 1000],
'n_jobs':[-1]
})모델 선택
roc_auc_score를 평가지표로 가장 높은 점수에 해당하는 하이퍼 파라미터를 찾기 위해 반복문 진행.
best_score = -1
iter_num = 0
for p in param_grid:
model = RFC(**p).fit(train_x, train_y)
pred = model.predict_proba(test_x)[:, 1]
score = roc_auc_score(test_y, pred)
if best_score < score:
best_score = score
best_param = p
iter_num += 1
print(f'{iter_num}/{max_iter} : best score : {best_score} | score : {score}')모델의 최종 하이퍼 파라미터는 아래와 같다.
아래의 파라미터를 가지고 다시 학습을 진행하여 결과를 확인한다.

model = RFC(**best_param).fit(train_x, train_y)
train_pred = model.predict_proba(train_x)[:, 1]
test_pred = model.predict_proba(test_x)[:, 1]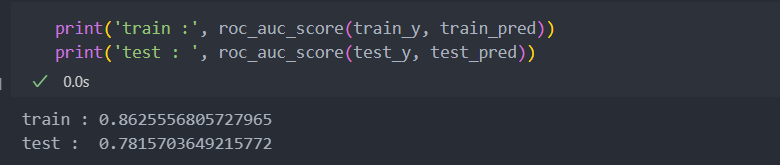
model = RFC(**best_param).fit(train_x, train_y)
train_pred = model.predict(train_x)
test_pred = model.predict(test_x)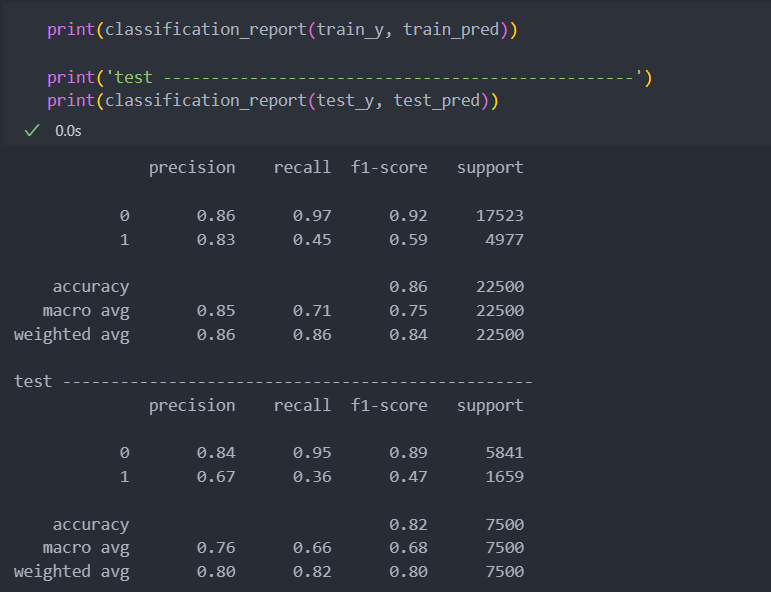
학습/평가 데이터를 가지고 확인을 했을 시 과적합은 아닌 것으로 확인이 된다.
해당 모델 뿐만이 아니라, 다른 특징들을 생성하거나 제외시켜 모델링을 새롭게 진행하였을 때에도 사용할 수 있도록 중요 특징을 확인하는 함수를 작성하고, 해당 모델에 영향을 끼친 특징을 확인해보자.
def get_feature_importances(model, data):
ftr_importances_values = model.feature_importances_
ftr_importances = pd.Series(ftr_importances_values, index = data.columns)
ftr_top20 = ftr_importances.sort_values(ascending=False)[:30]
plt.figure(figsize=(12, 8))
plt.title('Feature Importances')
sns.barplot(x=ftr_top20, y=ftr_top20.index)
plt.rc('xtick', labelsize=5)
plt.show()
get_feature_importances(model=model, data=train_x)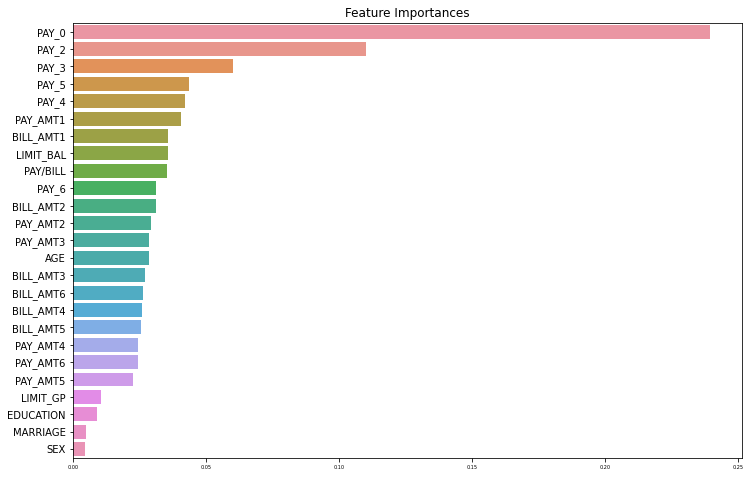
기대효과
예측한 고객들을 대상으로 신용한도 조정 및 블랙리스트 관리를 통한 손실 방어.
