
문제 정의
카드 기록(실제 상거래 데이터)을 활용한 사기 거래 탐지
데이터 확인
출처 : 캐글(kaggle)
소스코드 : GitHub
해당 데이터는 라벨 데이터를 제외한, 매우 많은 특징(컬럼) 432개를 가지고 있다.
그 중에서 중요하다 판단되는 특징만 가져와서 진행한다.

EDA & 전처리
탐색
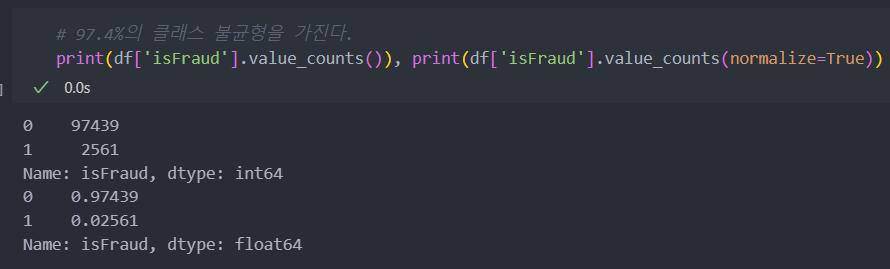
클래스 불균형 - 라벨
해당 데이터와 같은 종류는 으레 데이터 불균형이 존재할 수 밖에 없는 구조다.
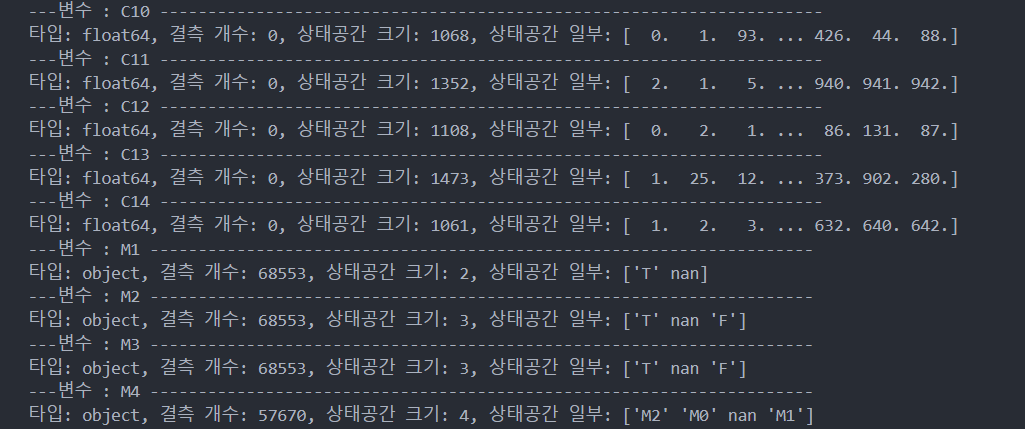
특징(컬럼) 변수형(상태공간) 확인
특징별 특징을 살펴보면 범주형과 연속형 변수가 섞여있고, 결측치도 존재한다.
for col in df.columns:
print(f'---변수 : {col} ---------------------------------------------------------------------')
print("타입: {}, 결측 개수: {}, 상태공간 크기: {}, 상태공간 일부: {}".format(df[col].dtype, df[col].isnull().sum(), len(df[col].unique()), df[col].unique()))
범주형과 연속형 변수를 각각 탐색해보자.
범주형 변수 탐색
ProductCD
결측치가 없다.
그리고 해당 범주형 변수의 빈도값을 확인해보자.
df['ProductCD'].value_counts(normalize=True).plot(kind='bar', fontsize=15)
plt.gcf().set_size_inches(12, 8)
plt.show()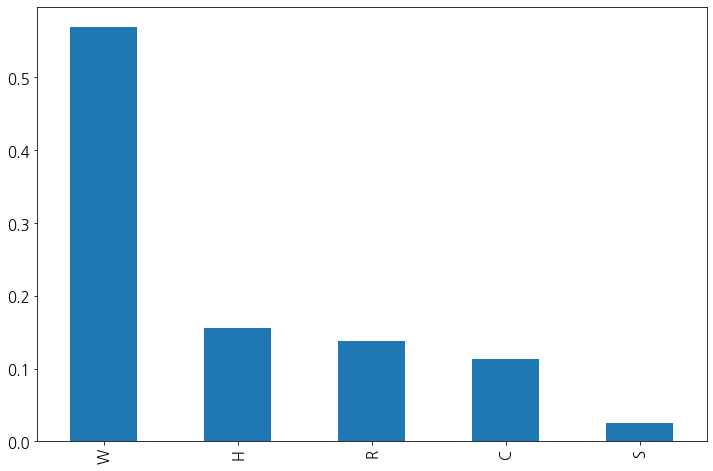
각 변수와 라벨 데이터간의 비유을 살펴보자.
전체 라벨 '1'에 해당하는 비율이 2.5%인데 반해, 'C'의 경우는 값이 비율보다 크고 'S'는 비슷하지만 데이터가 적은 편이라 굳이 신경쓸 필요성은 없어 보인다. 그리고 나머지는 비율보다 적기에 어느 정도의 연관성이 있어 보인다.
문자형 데이터이기에 더미화를 진행한다.


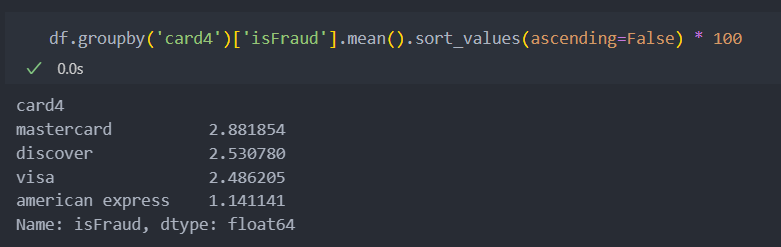
card4(카드 브렌드)
결측치가 7개 밖에 되지 않기에 최빈값으로 대체한다.

해당 범주형 변수의 빈도값을 확인해보자.
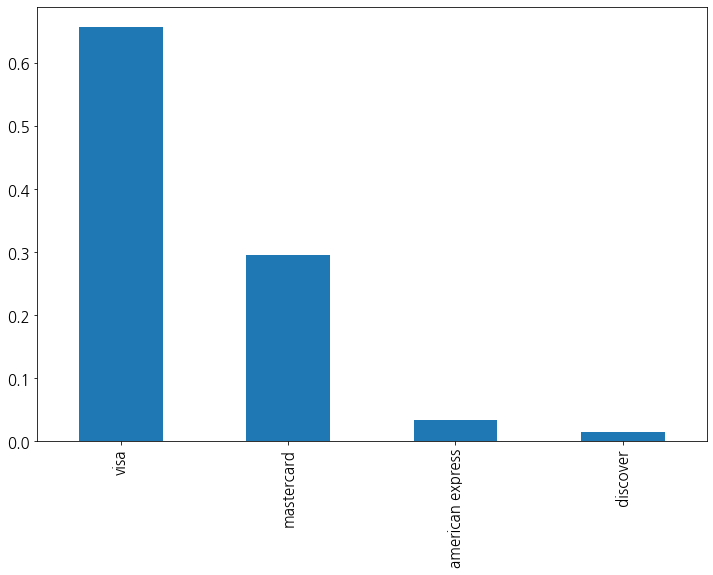
american express만 비율이 기준치 비율(2.5%)보다 작기에, 카드 종류가 american express인지 아닌지를 기준으로 이진화로 분할한다.

card6(카드 종류)
결측치가 4개 밖에 되지 않기에 최빈값으로 대체한다.

해당 범주형 변수의 빈도값을 확인해보자.
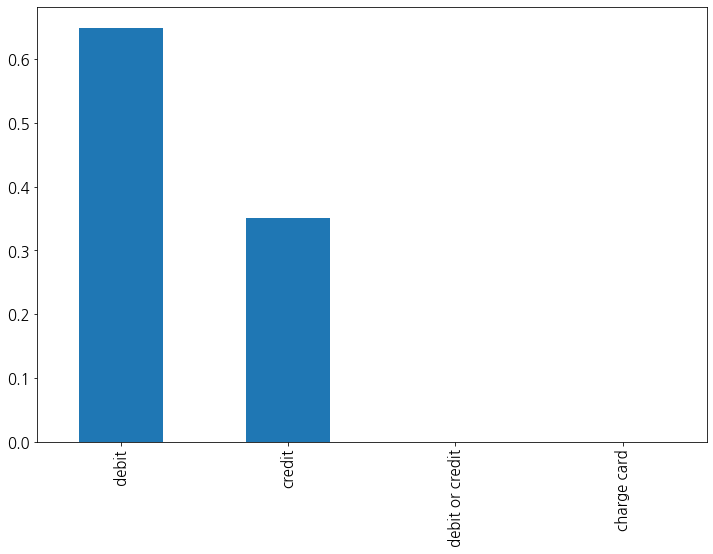
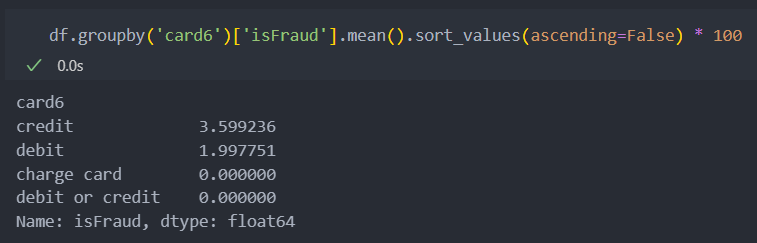
credit과 debit을 제외한 2가지는 데이터가 워낙 적기에 유의미한 변수로 보기 어렵다. 그래서 credit인지 debit인지 확인하는 변수로 대체한다.

e-mail 관련 변수
범주형 변수지만 상태공간의 크기가 큰 편에 속한다.
그리고 결측치가 많이 포함되어 있는 변수인데, 둘 중 하나만 e-mail을 기재했을 수도 있고 아닐 수도 있다.
이 두 특징(컬럼)은 같은 포지션의 변수로 상관관계가 있어 보인다.
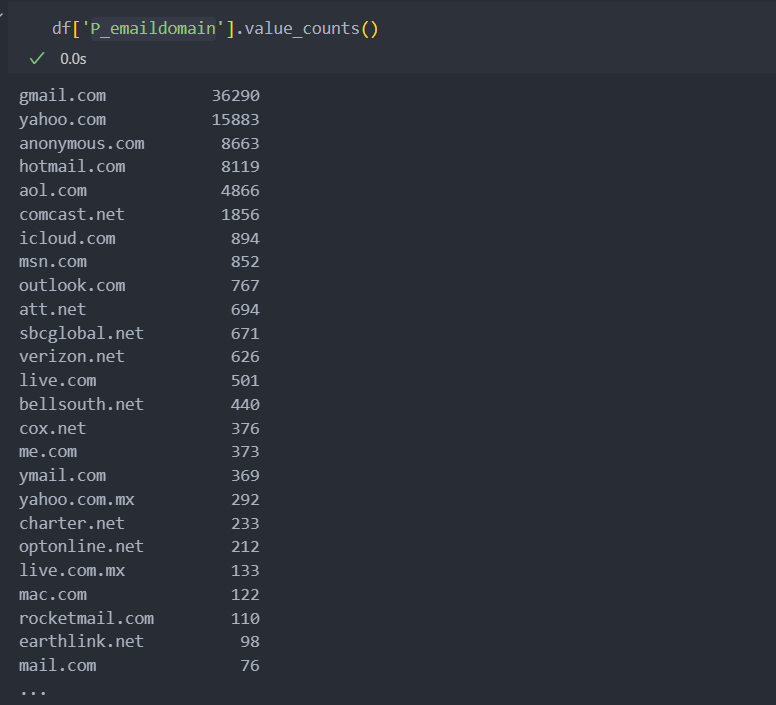
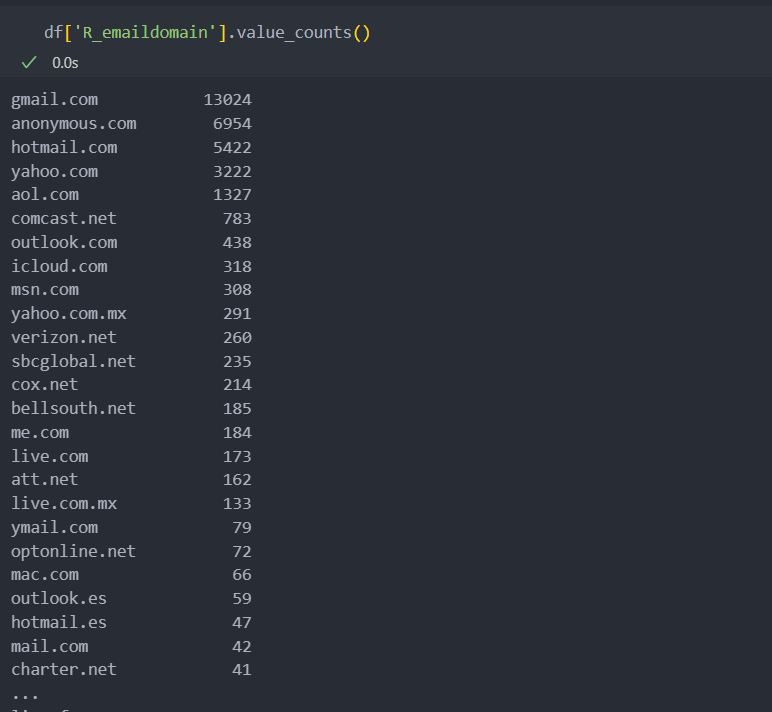
그리고 결측이 가지는 의미가 있는지 살펴보면 아래와 같이,
유의미한 차이점이 있음을 알 수 있다.
'R_emaildomain'인 경우 e-mail이 기재되어 있는 경우에 사기인 경우가 더 많다는 것을 확인할 수 있다.
# 결측치가 의미가 있는지 없는지 확인하기 위해 '컬럼'생성
df['NA_P_emaildomain'] = df['P_emaildomain'].isnull().astype(int)
df['NA_R_emaildomain'] = df['R_emaildomain'].isnull().astype(int)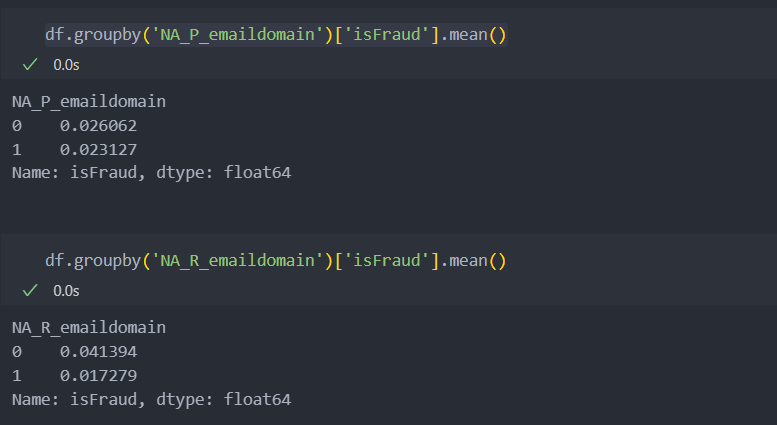
또한 e-mail이 .com 이나 .net을 제외하고 기재된 경우도 있어 통일을 시켜놓자.
df['P_emaildomain'] = df['P_emaildomain'].str.split('.', expand=True).iloc[:, 0]
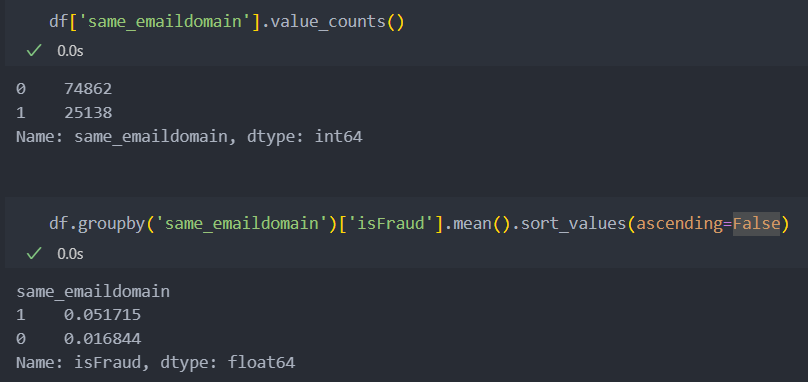
df['R_emaildomain'] = df['R_emaildomain'].str.split('.', expand=True).iloc[:, 0]그리고 두 특징(컬럼)이 같은 e-mail을 가지는지 확인해보자.
df['same_emaildomain'] = (df['P_emaildomain'] == df['R_emaildomain']).astype(int)두 특징이 같은 e-mail을 가지는 변수는 1:3 비율로 유의미한 변수로 적용가능할 것 같아 보이며,
e-mail이 같은 경우 '사기'일 확률이 높고, 아닌 경우 낮은 것을 볼 수 있다.
C3
결측치가 없으며, 대부분이 0의 값을 가진다.
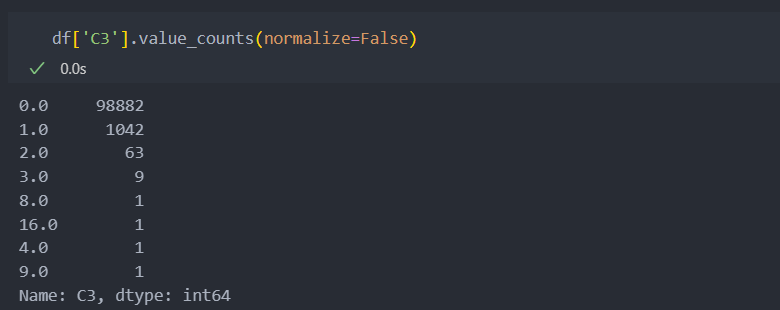
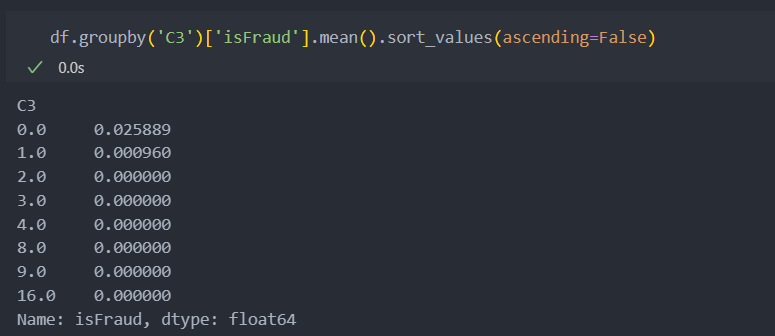
대부분의 값을 가지는 0의 값일 때 가지는 '사기' 비율이 평균 '사기'비율과 거의 유사하기에 큰 의미가 없는 변수라고 판단된다.
하지만 1이 어느 정도의 빈도를 차지하는 것에 반해서 '사기' 비율이 0이기에 1일 때만 유의미하게 작용할 수 있도록 한다.
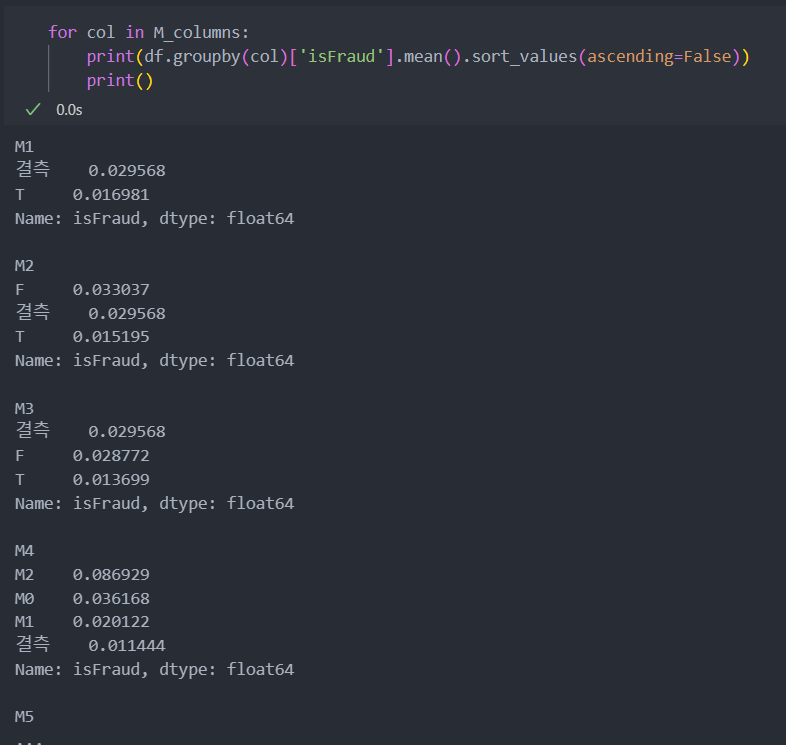
M 변수들
M 변수들은 결측치가 많이 들어가 있다.
대표값이나 최빈값으로 대체하기에는 결측치의 값이 더 많은 경우도 존재하기에 결측치를 하나의 값인 '결측'으로 변환한다.
# M1 ~ 9 변수명 생성
M_columns = ['M' + str(i) for i in range(1, 10)]
df[M_columns] = df[M_columns].fillna('결측')그리고 각 M별 '사기'비율을 확인해보자.
결측일때와 아닐 때 각각 비율의 차이가 있다.
연속형 변수 탐색
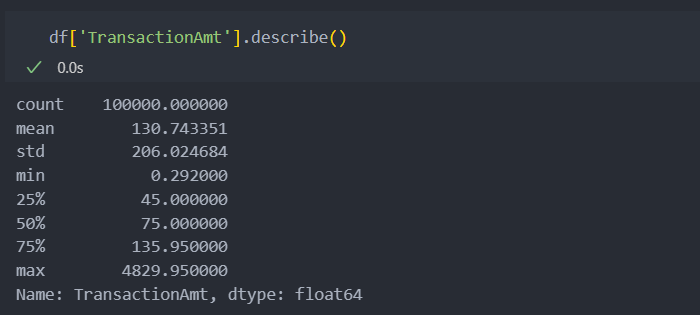
TransactionAmt
거래 금액의 분포를 확인해보자.
1,000달러 미만에 대부분의 값이 분포되어 있다.

그리고 양의 값으로, 평균값보다 표준편차의 값이 더 큰 것으로 보아 값의 분포가 퍼져있음을 알 수 있다.
그리고 IQR 값이나 평균에 비해서 최대값이 매우 큰 것으로 보아 1,000달러 이상의 값은 이상치로 볼 수 도 있다.
'사기'일 때와 아닐 때의 값을 박스 플롯으로 확인해보면,
두 경우의 차이를 아웃라이어로 잡는 것은 애매해 보인다.
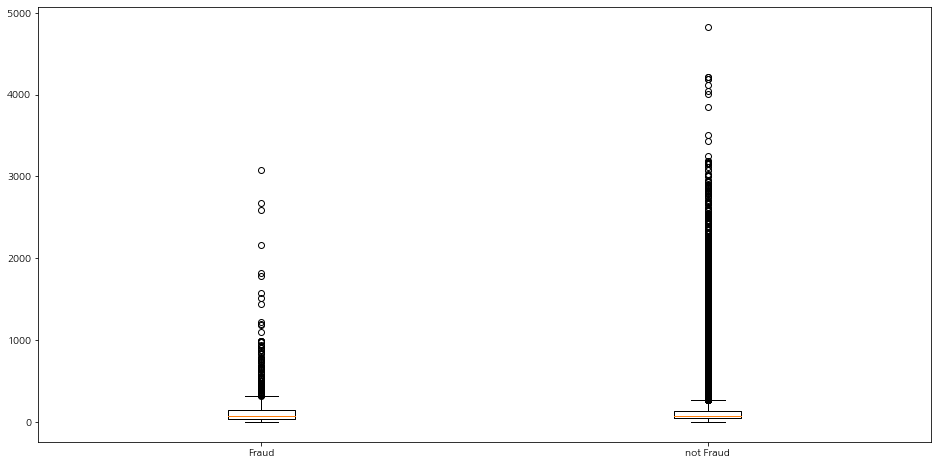
데이터를 확인해보아도 크게 차이나는 점은 찾기 어려워보인다.
데이터의 치우침을 완화하고 다시 살펴보자.
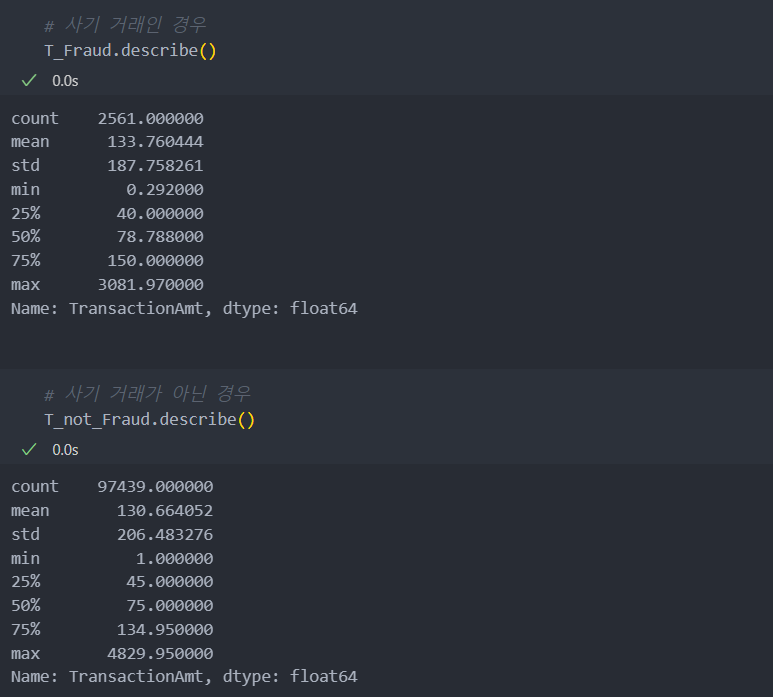
C 관련 변수들
C 관련 변수들은 아래와 같이 중위값과 평균값, 최대값에 차이가 매우 큰 것을 확인할 수 있다.

IQR 범위를 좀 더 자세히 살펴보자.
중위값
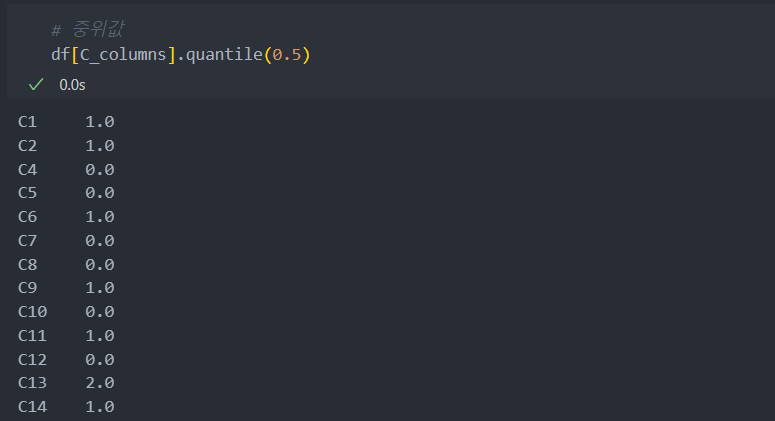
75%
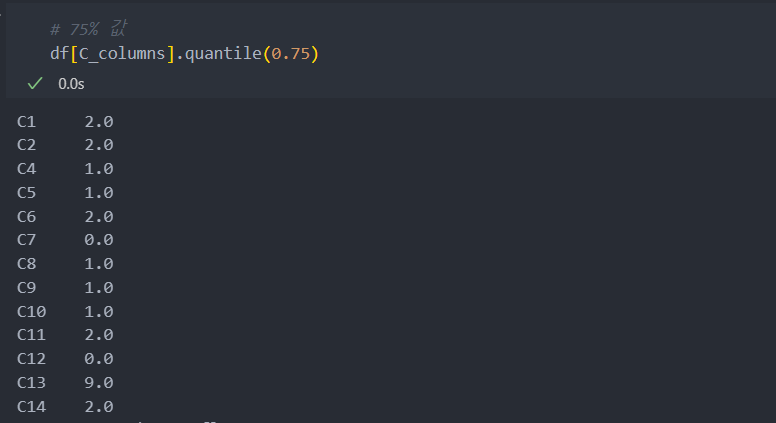
90%
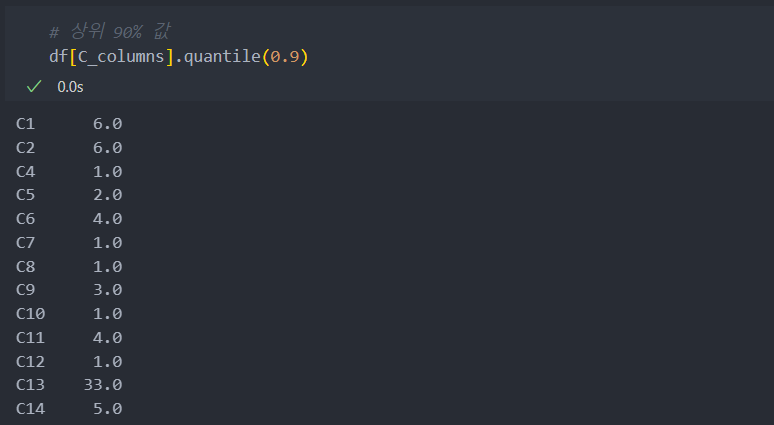
99% : 갑자기 값이 커진다.
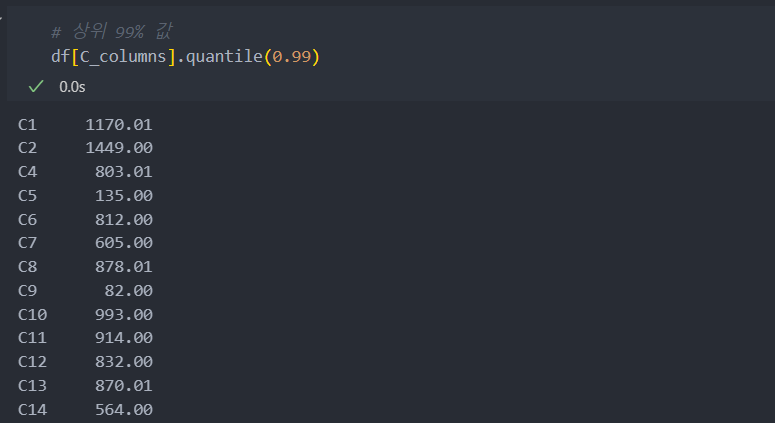
그리고 왜도값을 보면 데이터가 양의 값으로 매우 치우쳐있음을 확인할 수 있다.
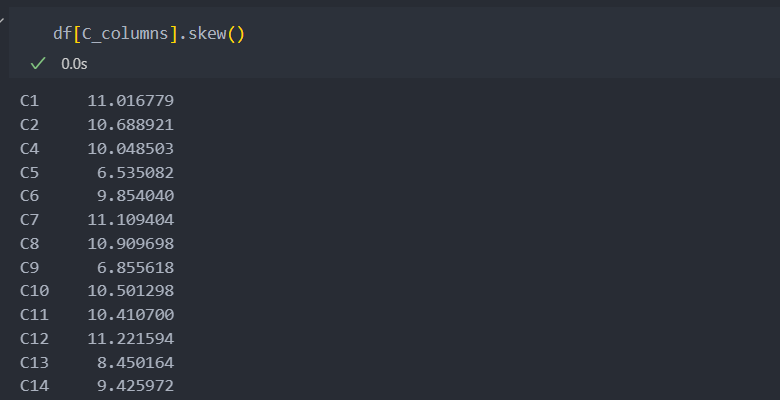
치우쳐있으며 값이 99%쪽에 몰려있는 데이터(이상치)로 범주화하기 어려운 데이터다.
C 관련 데이터들을 활용하기 위해서 Tree 계열 모델을 활용해야 할 것으로 보인다.
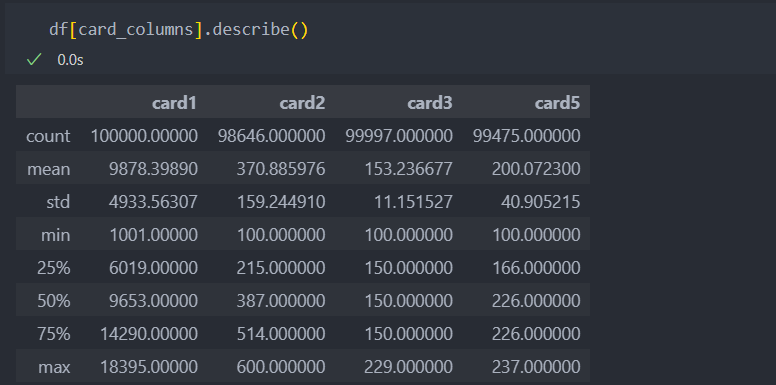
card 관련 변수들
card 관련 변수들의 분포를 확인해보자.
명확하게 card3은 연속형 변수라고 하기엔 애매한 부분이 있다.
card5의 분포는 모양이 조금 이상하게 나타난다.
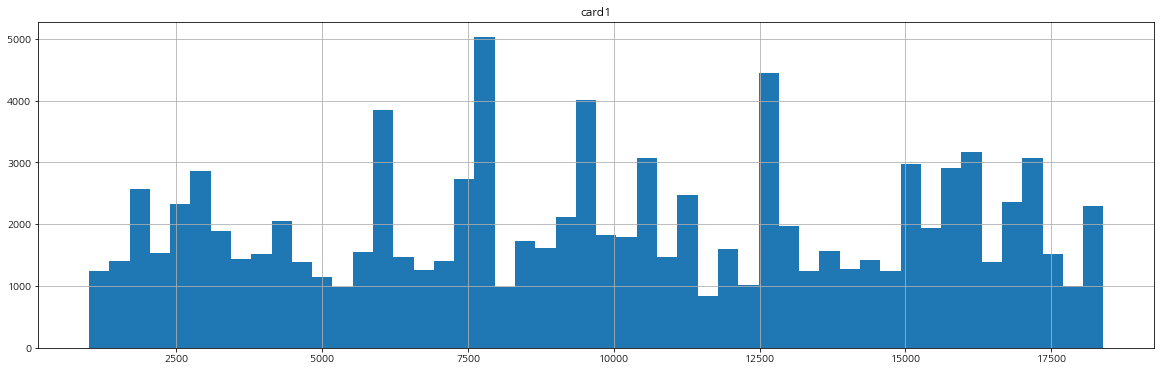
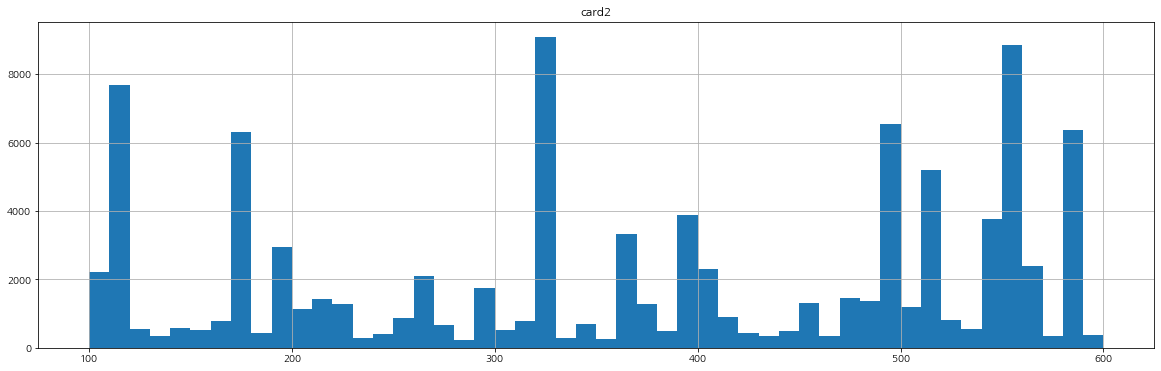
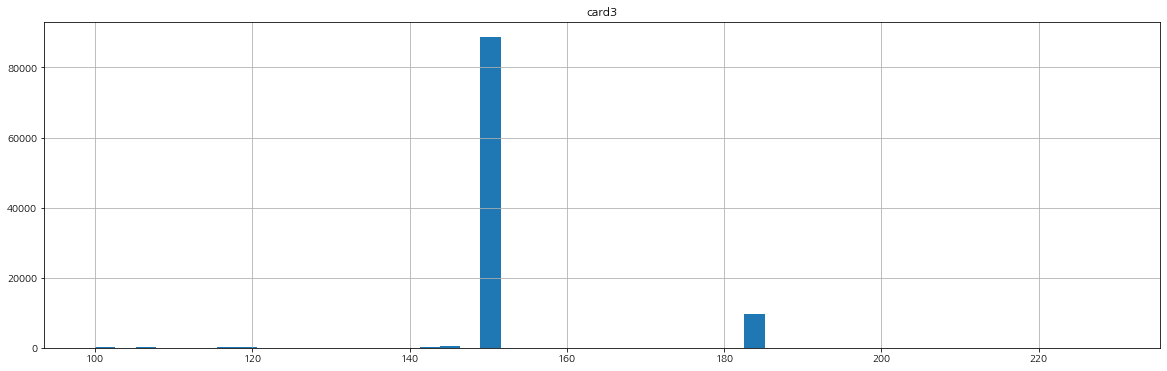
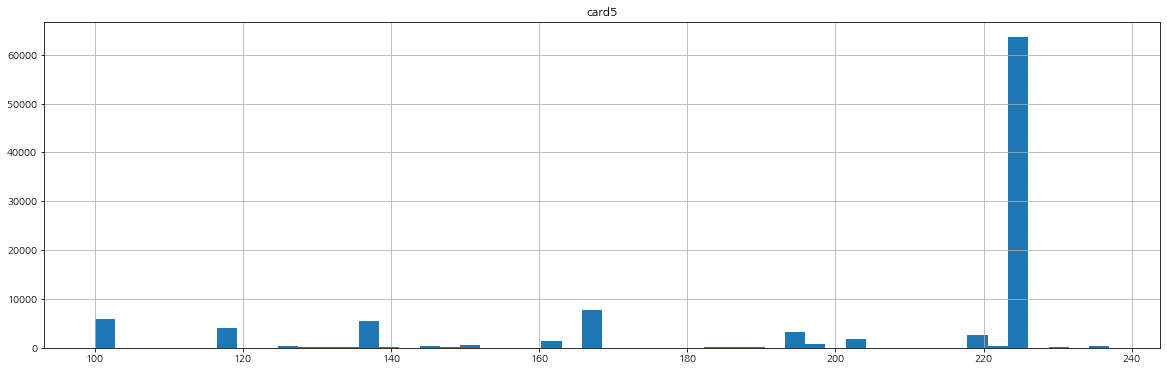
card3은 연속형 변수로 보이지만 150, 185, 그 외로 묶어주어도 될 것 같아 보인다.
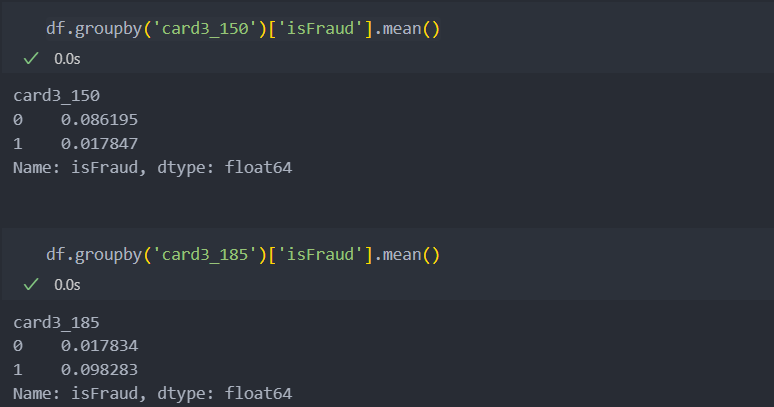
df['card3_150'] = (df['card3']==150).astype(int)
df['card3_185'] = (df['card3']==185).astype(int)변환한 후 '사기' 비율을 확인해보자.
card5도 확인해보자.
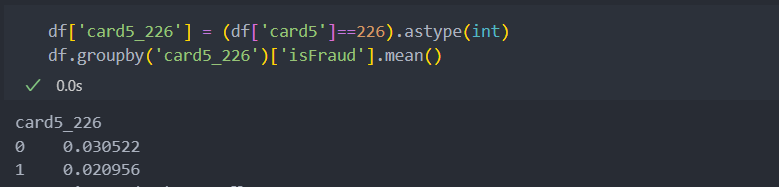
범주형으로 보았을 때 card3, 5는 유의미한 차이가 있어 보인다.
전처리
탐색을 진행하며 처리해야 할 부분들을 진행해보자.
진행하기에 앞서 탐색에서 진행한 부분을 초기화하고(다시 데이터 불러오기) 진행한다면 전처리 부분에서도 적용시켜야 한다.(추천 - pipeline 적용)
범주형 변수 이진화
card4
'american_express'인 변수와 아닌 변수로 이진화 진행.
df['american_express'] = (df.loc[:, 'card4'] == 'american express').astype(int)
df.drop('card4', axis=1, inplace=True)card6
카드 종류가 'credit' 변수와 아닌 변수로 이진화 진행
df['credits'] = (df.loc[:, 'card6'] == 'credit').astype(int)
df.drop('card6', axis=1, inplace=True)e-mail 관련 변수
탐색 진행 시, 결측치 컬럼 생성과 두 e-mail이 같은지 여부의 컬럼 생성을 진행하였기에
기존의 e-mail 컬럼 삭제
df.drop(['P_emaildomain', 'R_emaildomain'], axis=1, inplace=True)C3
0인 변수와 아닌 변수로 이진화 진행.
df['C3_over_1'] = (df['C3'] >= 1).astype(int)
df.drop('C3', axis=1, inplace=True)더미화
ProductCD와 'M'관련 특징들을 'one-hot encoding'을 이용하여 더미화 한다.
인코딩 전
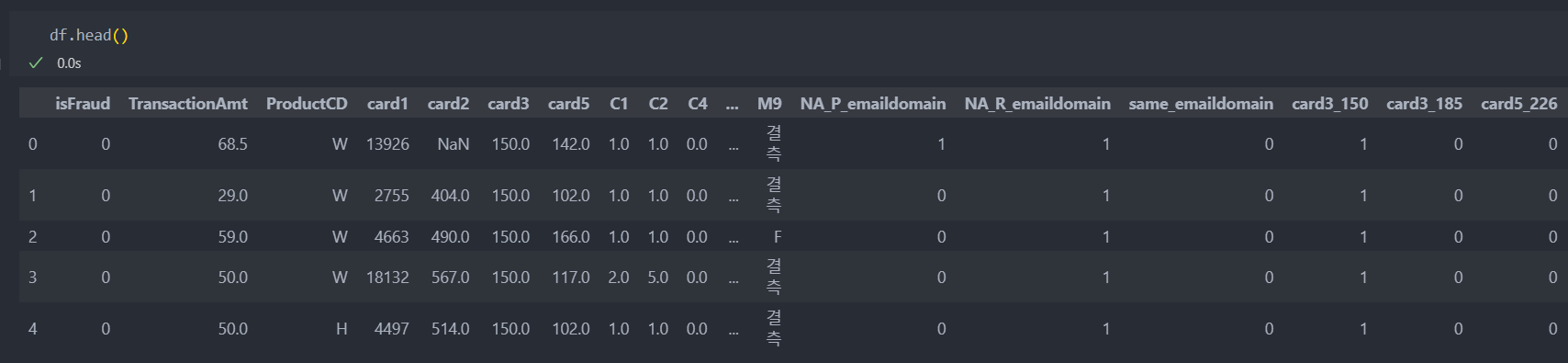
'M'관련 특징들은 이미 결측치를 '결측'으로 처리하였고, 더미화를 진행하면 많으면 5개에서 2개 사이로 더미화가 진행된다.
from feature_engine.categorical_encoders import OneHotCategoricalEncoder as OHE
dummy = OHE(variables=M_columns+['ProductCD'], drop_last=True).fit(df)
df = dummy.transform(df)인코딩 후

치우침 해소
로그 변환으로 치우침을 해소한다.
df['TransactionAmt'] = np.log(df['TransactionAmt'])
연속형 변수 이진화
card3은 150, 185를 기준으로 card5는 226을 기준으로 이미 이진화를 진행하였다.
남은 card3, card5의 컬럼을 삭제한다.
df.drop(['card3', 'card5'], axis=1, inplace=True)특정값 기준 결측치 대체
사이킷런의 impute를 활용하여 결측값을 대체한다.
from sklearn.impute import SimpleImputer as SI
# 인스턴스
imputer = SI().fit(df)
df = pd.DataFrame(imputer.transform(df), columns=df.columns)전

후

클래스 불균형
현재 라벨의 데이터는 불균형이 심하다.
클래스 불균형도 하이퍼 파라미터 튜닝에 포함하여 진행한다.
전체 데이터의 수가 10만이기에 오버샘플링을 수행하기에는 부적절해 보인다.
그래서 언더 샘플링을 진행하여도 약 4천개로 여유가 있기에 언더샘플링과 불균형 기존으로 병행하여 모델링 시 같이 진행하도록 한다.
모델링
모델은 Tree 기반의 앙상블 모델 RandomForestClassifier와 XGBClassifier을 사용하도록 하며, 평가지표는 f1 score를 사용한다.
그리고 특징(컬럼)은 모두 사용하되 차원의 저주를 피하기 위해 특징수를 5개씩 줄여가며 진행하여, 가장 평가지표의 점수가 높게 나온 특징들을 선택하도록 'SelectKBest'을 활용한다. 또한 변수가 범주/연속형이 섞여있으며 라벨 분류 문제이기에 '상호 정보량' mulual_info_classif을 적용한다.
그리고 언더샘플링을 한 데이터와 하지 않은 데이터를 구분하여 하이퍼 파라미터 진행 시 적용하도록 한다.
언더샘플링을 하지 않은 모델은 class_weight를 적용하도록 한다.
모델 학습
먼저 라벨 데이터를 분리하고 평가/학습 데이터로 분리한다.
X = df.drop('isFraud', axis=1)
Y = df[['isFraud']]
train_x, test_x, train_y, test_y = train_test_split(X, Y, stratify=Y)하이퍼 파라미터 튜닝을 진행한다.
# 기본 하이퍼 파라미터 튜닝
RFC_grid = dict({
'n_estimators':[100, 200],
'max_depth':[3, 5, 7, 10]
})
XGB_grid = dict({
'n_estimators':[100, 200],
'max_depth':[3, 5, 7, 10],
'learning_rate':[0.05, 0.1, 0.2]
})일반과 언더 샘플링한 모델을 각각 적용시킨다.
# class_imbalance_ratio : 일반 모델에 적용하기 위한 가중치 계산
class_imbalance_ratio = np.sum(train_y==0) / np.sum(train_y==1)
# 언더 샘플링을 하지 않은 모델의 가중치 적용
RFC_cs_grid = copy.copy(RFC_grid)
XGB_cs_grid = copy.copy(XGB_grid)
RFC_cs_grid['class_weight'] = [{1:class_imbalance_ratio * w, 0:1} for w in [1, 0.9, 0.7, 0.5]]
XGB_cs_grid['class_weight'] = [{1:class_imbalance_ratio * w, 0:1} for w in [1, 0.9, 0.7, 0.5]]
# 파라미터 변환
RFC_cs_grid = ParameterGrid(RFC_cs_grid)
XGB_cs_grid = ParameterGrid(XGB_cs_grid)
RFC_grid = ParameterGrid(RFC_grid)
XGB_grid = ParameterGrid(XGB_grid)
# 일반
grid_for_cs_model = {RFC:RFC_cs_grid, XGB:XGB_cs_grid}
# 언더 샘플링 적용
grid_for_not_cs_model = {RFC:RFC_grid, XGB:XGB_grid}평가지표는 f1 score를 활용할 것이며 각각의 모델에 적용시키기 위해 함수로 만든다.
# f1 평가지표 함수
def model_test(model, test_x, test_y):
pred = model.predict(test_x)
return f1_score(test_y, pred)일반 하이퍼 파라미터 튜닝
# 언더 샘플링을 한 경우와 아닌 경우의 꼬임 방지
tr_x = train_x.copy()
te_x = test_x.copy()
num_iter = 0
best_score = -1
for k in range(train_x.shape[1], 6, -5):
selector = SelectKBest(mutual_info_classif, k = k).fit(tr_x, train_y)
seleced_columns = tr_x.columns[selector.get_support()]
tr_x = tr_x[seleced_columns]
te_x = te_x[seleced_columns]
for func in grid_for_cs_model:
for p in grid_for_not_cs_model[func]:
model = func(**p).fit(tr_x, train_y)
score = model_test(model=model, test_x=te_x, test_y=test_y)
if score > best_score:
best_model = model
best_features = seleced_columns
best_score = score
num_iter += 1
print(f'{num_iter}/{max_iter}, best score : {best_score}')평가지표는 약 73%이고 모델은 XGBClassifier, 특징(컬럼)들의 정보는 아래와 같다.

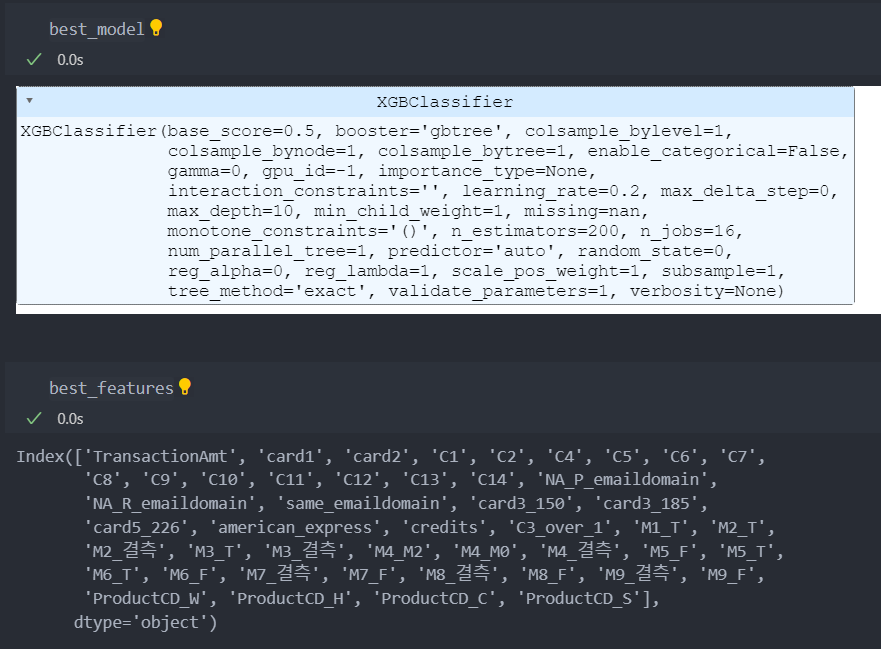
언더 샘플링 하이퍼 파라미터 튜닝
참조 : 언더 샘플링
일반 모델과 성능 비교를 위해서 best_score를 초기화하지 않고 적용시켜서,
언더 샘플링의 best_score가 높으면 적용시킬 것이고 아니면 그냥 일반 모델의 파라미터들을 사용할 것이다.
num_iter = 0
for w in [1, 0.9, 0.7, 0.5]:
# 언더 샘플링으로 인한꼬임 방지
tr_x = train_x.copy()
te_x = test_x.copy()
NM_model = NearMiss(version=2, sampling_strategy={
1:train_y.value_counts().iloc[-1],
0:int(train_y.value_counts().iloc[-1] * w * class_imbalance_ratio)
})
u_tr_x, u_tr_y = NM_model.fit_resample(tr_x, train_y)
u_tr_x = pd.DataFrame(u_tr_x, columns=tr_x.columns)
for k in range(train_x.shape[1], 6, -5):
selector = SelectKBest(mutual_info_classif, k=k).fit(u_tr_x, u_tr_y)
seleced_columns = u_tr_x.columns[selector.get_support()]
u_tr_x = u_tr_x[seleced_columns]
te_x = tr_x[seleced_columns]
for func in grid_for_not_cs_model:
for p in grid_for_not_cs_model[func]:
model = func(**p).fit(u_tr_x, u_tr_y)
score = model_test(model=model, test_x=te_x, test_y=test_y)
if score > best_score:
best_model = model
best_features = seleced_columns
best_score = score
num_iter += 1
print(f'{num_iter}/{max_iter} best score : {best_score}')결과
평가지표와 모델은 아래와 같다.

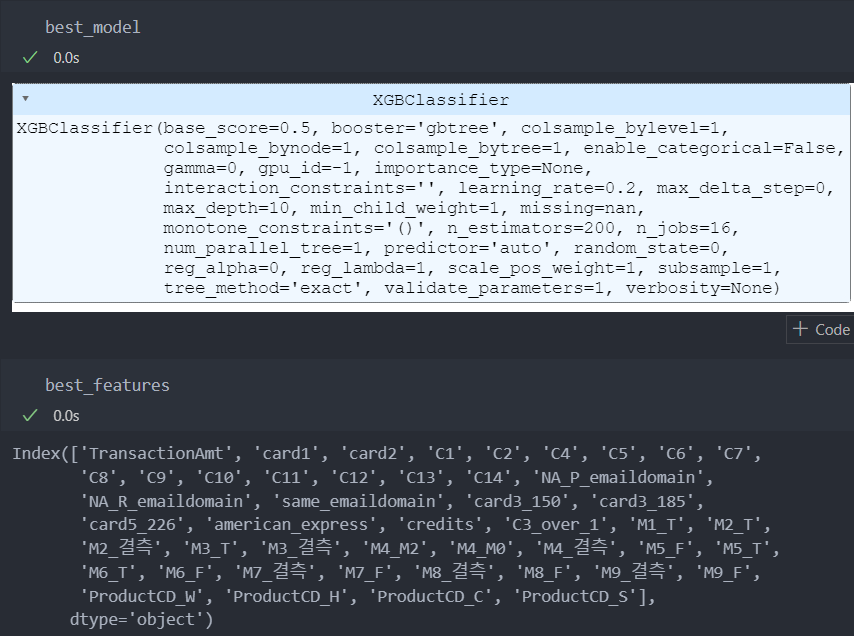
모델에 영향을 많이 끼친 순서대로 features를 함수로 작성해서 확인해보자.
def get_feature_importances(model, data):
ftr_importances_values = model.feature_importances_
ftr_importances = pd.Series(ftr_importances_values, index = data.columns)
ftr_top20 = ftr_importances.sort_values(ascending=False)[:30]
plt.figure(figsize=(12, 8))
plt.title('Feature Importances')
sns.barplot(x=ftr_top20, y=ftr_top20.index)
plt.rc('xtick', labelsize=5)
plt.show()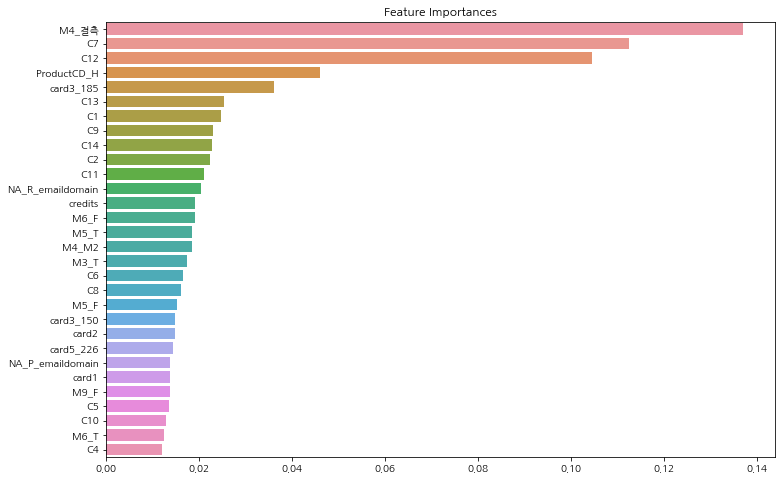
모델 적용
최종 선택된 모델을 적용시킨다.
model = best_model
features = best_features앞으로 새로 만들어지거나 들어올 데이터에 대해서,
데이터 전처리 과정을 똑같이 반복하여 사용할 수 있도록 pipeline을 함수로 만들고 최종 모델과 특징들을 적용시킨다.
def pipeline(input_data, dummy_model, imputer, features, model):
input_data_copy = input_data.copy()
input_data_copy.drop(['TransactionID', 'TransactionDT'], axis = 1, inplace = True)
# 범주형 변수: 이진화 및 파생 변수 생성
input_data_copy['american_express'] = (input_data_copy.loc[:, 'card4'] == 'american express').astype(int)
input_data_copy.drop('card4', axis = 1, inplace = True)
input_data_copy['credits'] = (input_data_copy.loc[:, 'card6'] == 'credit').astype(int)
input_data_copy.drop('card6', axis = 1, inplace = True)
input_data_copy['NA_R_emaildomain'] = (input_data_copy['R_emaildomain'].isnull()).astype(int)
input_data_copy['same_emaildomain'] = (input_data_copy['P_emaildomain'] == input_data_copy['R_emaildomain']).astype(int)
input_data_copy.drop(['P_emaildomain', 'R_emaildomain'], axis = 1, inplace = True)
input_data_copy['C3_over_1'] = (input_data_copy['C3'] >= 1).astype(int)
input_data_copy.drop(['C3'], axis = 1, inplace = True)
M_columns = ['M' + str(i) for i in range(1, 10)]
input_data_copy[M_columns] = input_data_copy[M_columns].fillna("결측")
input_data_copy = dummy_model.transform(input_data_copy)
# 연속형 변수 처리
input_data_copy['TransactionAmt'] = np.log(input_data_copy['TransactionAmt'])
input_data_copy['card3_150'] = (input_data_copy['card3'] == 150).astype(int)
input_data_copy['card3_185'] = (input_data_copy['card3'] == 185).astype(int)
input_data_copy['card5_226'] = (input_data_copy['card5'] == 226).astype(int)
input_data_copy.drop(['card3', 'card5'], axis = 1, inplace = True)
input_data_copy = pd.DataFrame(imputer.transform(train_x), columns = input_data_copy.columns)
input_data_copy = input_data_copy[features]
return model.predict(input_data_copy)기대 효과
사기 거래가 예상되는 거래 시, 사기 거래 경보(알람)를 알리는 효과가 향상되어 사기 손실을 줄일 수 있다.
