알고리즘 및 자료구조
1.[알고리즘] JS - 버블 정렬(Bubble Sort)
거품처럼 연쇄적으로 자기 자리를 찾아간다고 해서 버블 정렬(거품 정렬)로 불린다.데이터를 두 개씩 묶어서, 더 큰 값이 뒤로 가도록 자리를 바꿔가며 정렬이 진행된다.처음부터 끝까지 한 번 정렬을 했다면, 다시 처음부터 끝까지 정렬을 하고,이 것을 배열의 길이만큼 반복한
2.[알고리즘] JS - 선택 정렬(Selection Sort)

선택 정렬 가장 앞의 값을 기준으로 삼고, 배열 내에서 최소값을 찾는다. 최소값을 가장 앞의 값과 교환한다. 두 번째 값을 기준으로 삼고, 그 뒤의 배열에서 최소값을 찾는다. 최소값을 두 번째 값과 교환한다. ... 이렇게 반복되는 구조로 정렬이 진행되는 것을 선택
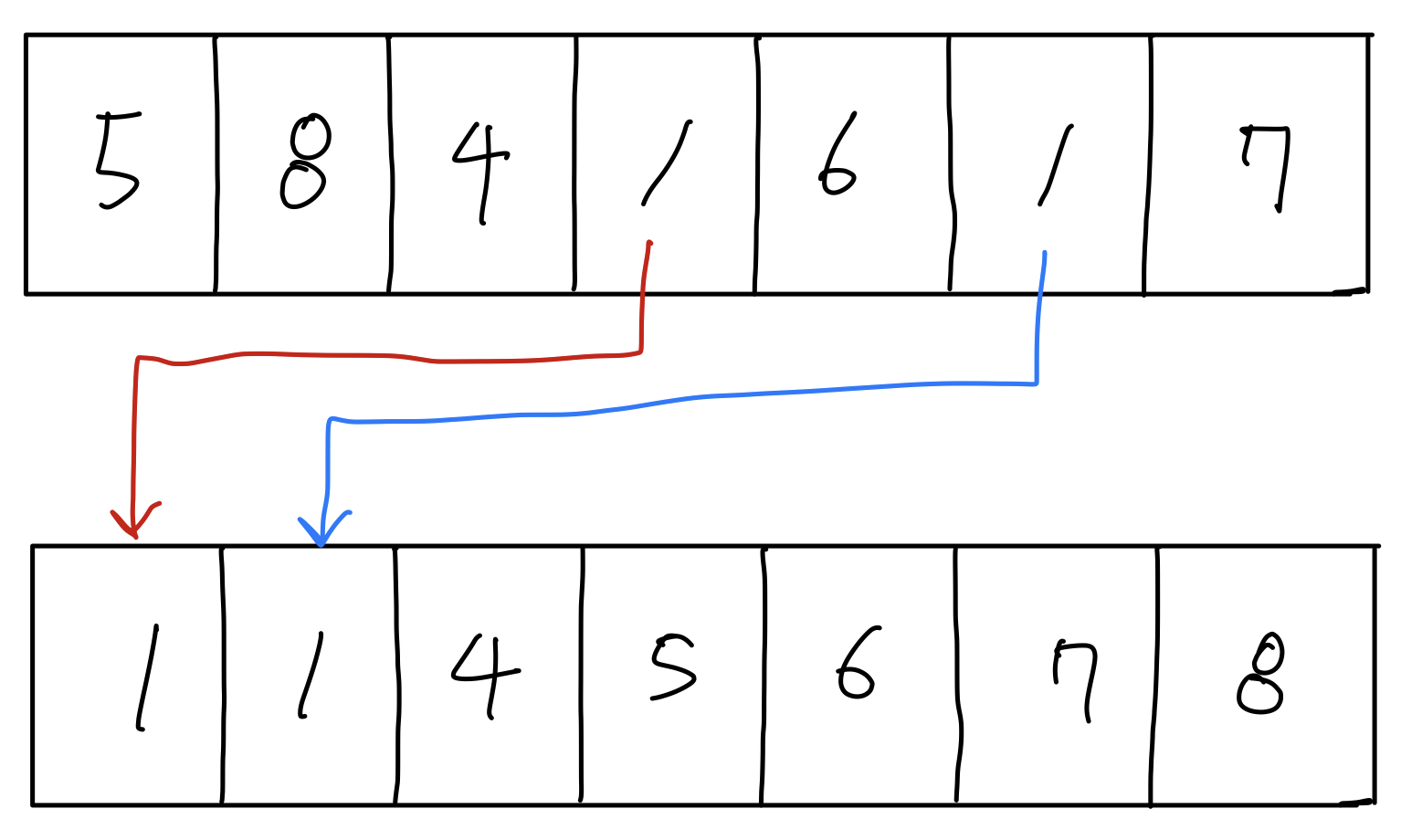
3.[알고리즘] JS - 삽입 정렬(Insertion Sort)
삽입 정렬 삽입 정렬(Insertion Sort)는 왼쪽에서 오른쪽으로 가면서 각 요소를 왼쪽 요소들과 비교하여 알맞은 자리에 삽입하는 형식을 정렬 방법이다. 참고 이미지 위 그림처럼 붉은색 요소(오른쪽 요소)를 회색 요소(왼쪽 요소)와 비교하면서 시작된다. 1회차
4.[알고리즘] JS - 병합 정렬(Merge Sort)
병합 정렬(합병 정렬) 데이터들을 잘게 쪼갠 다음 하나로 합치는 과정에서 정렬하는 방법이다. 참고 이미지 위 그림처럼 데이터를 반으로 쪼개나면서, 더 이상 쪼개지지않을 때까지 나눈 뒤 그들끼리 정렬을 하면서 다시 합병을 하는 과정을 거친다. 아래 영상을 보면 이해
5.[알고리즘] JS - 퀵 정렬(Quick Sort)
퀵 정렬 퀵 정렬(Quick Sort)은 중심(pivot)을 정하고, 벽을 하나 만들어서 중심값보다 작으면 벽 왼쪽으로 넘기고, 더 이상 벽 왼쪽으로 갈 것이 없으면 벽이 있는 위치에 있는 값과 중심값을 교환하고, 또 다시 반복하고... 이런 방식으로 정렬을 해나가는
6.[자료 구조] Linear Probing 방식의 Hash Table 구현
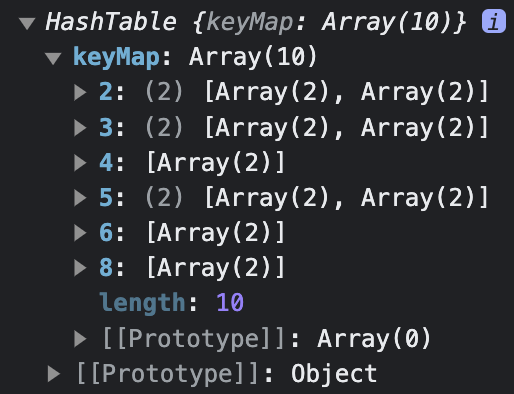
\_hash()를 통해서 해시 값을 생성한 뒤, Hash Table의 해당 주소에 key-value pair를 추가한다.이 때, Linear Probing 방식으로 해쉬 충돌을 해결하기 위해서 추가 작업이 필요하다.\_hash()를 통해 같은 값이 나온 경우, 주소 값