퀵 정렬
퀵 정렬(Quick Sort)은 중심(pivot)을 정하고, 벽을 하나 만들어서
중심값보다 작으면 벽 왼쪽으로 넘기고, 더 이상 벽 왼쪽으로 갈 것이 없으면
벽이 있는 위치에 있는 값과 중심값을 교환하고,
또 다시 반복하고...
이런 방식으로 정렬을 해나가는 정렬이다.
좀 더 정제해서 말하자면
- 기준 원소를 고른다.
- 배열을 기준 원소보다 작은 원소의 배열과, 기준 원소보다 큰 원소의 배열, 이렇게 2가지로 분할한다.
- 하위 배열에 대해 재귀적으로 퀵 정렬을 호출한다.
병합 정렬과 마찬가지로 Divide and Conquer 을 사용하는 알고리즘이다.
JS의 대표적인 정렬 함수인 sort()가 바로 퀵 정렬을 이용한 함수이다.
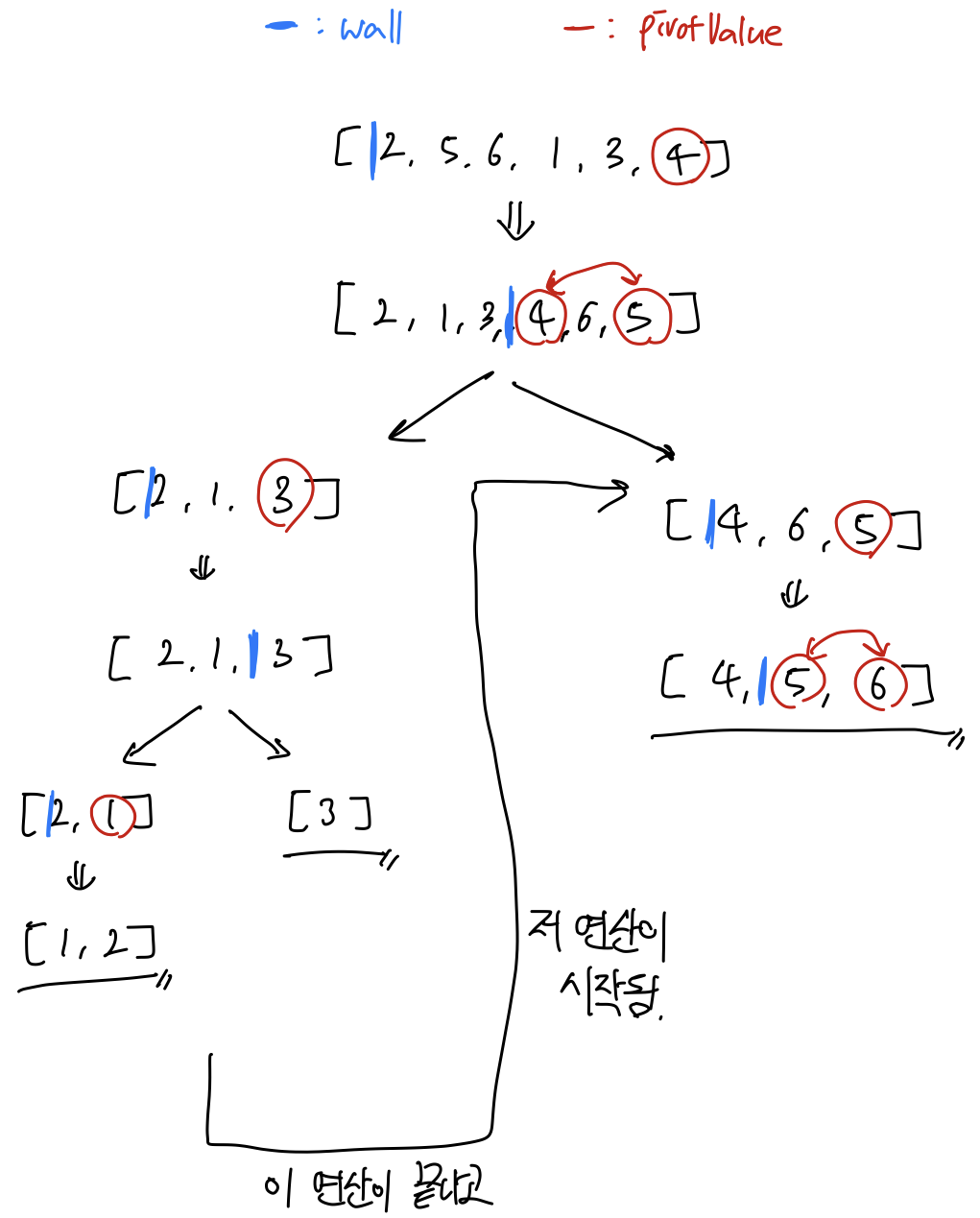
사실 말로는 이게 이해가 잘 안된다.
가장 아래 부분에 조잡하지만 이해를 돕기 위한 그림을 넣어놨으니 참고해주세요 ㅠㅠ
Big O
O(nlog₂n) 의 시간복잡도를 가진다.
스택의 크기가 O(log₂n) 이고, 각 스택마다 요소의 개수만큼 검색하므로
총 O(n) 을 순회하기 때문에
결과적으로 저런 시간복잡도를 지니게 된다.
최악의 경우에는 O(n^2) 의 시간복잡도를 가진다.
장점
in place 알고리즘으로 실행되기 때문에 추가적인 공간이 필요하지않아서
메모리 공간이 절약된다는 장점이 있다.
Unstable
중복값이 존재한다면 중복값끼리 위치가 변화할 수 있으므로 Unstable 한 정렬이다.
구현 방법
// front와 back 자리의 값을 교환하는 함수
function swap(array, front, back) {
// index에 있던 값을 tmp에 할당
const tmp = array[front];
// pivotIndex에 있던 값을 index 자리에 넣는다.
array[front] = array[back];
// index에 있던 값은 wall 자리에 넣는다.
array[back] = tmp;
}
// 배열 맨 끝에 있는 원소를 pivot으로 삼고 시작하는 방법이다.
function lomutoPartition(array, start, end) {
// 배열의 마지막 원소를 pivot으로 삼는다.
const pivotValue = array[end];
// 벽은 정렬하고자 하는 범위의 가장 앞에서부터 시작한다.
let wall = start;
// 배열 맨 앞부터 순회 시작. 이 때 end보다 작은 인덱스까지 순회한다는 점에 주의!
// quickSortWithLomuto()에서 end 값을 배열 마지막 원소의 인덱스로 설정해놨기 때문이다.
// end 값은 pivot이기에 비교하지 않는다.(그렇게 되면 본인 스스로를 비교하는 꼴이므로)
for (let index = start; index < end; index++) {
// 배열의 index번 인덱스에 있는 값이 pivot보다 작으면
if (array[index] < pivotValue) {
// index의 값을 wall에 있는 값과 swap한다.
swap(array, index, wall);
// wall을 한칸 뒤로 미룬다.
wall += 1;
}
}
// pivot 값보다 크거나 같은 값들만 wall 뒤쪽에 남아 있으므로
// wall과 end값을 교환해준다.
swap(array, wall, end);
// wall의 현재 위치를 반환한다.
return wall;
}
// 퀵 정렬
// 시작 인덱스와 끝 인덱스는 파마리터에서 초기화해줬다.
function quickSortWithLomuto(array, start = 0, end = array.length - 1) {
// 시작 인덱스가 끝 인덱스보다 같거나 크면 연산을 그대로 종료한다.
if (start >= end) {
return;
}
// 벽이 될 자리를 지정한다.
let wall = lomutoPartition(array, start, end);
// Divide and Conquer
// wall 앞 부분에 있는 것을 다시 퀵 정렬 해준다.
quickSortWithLomuto(array, start, wall - 1);
// 앞 부분 처리가 완료된 array는 아직 wall 뒷 부분이 정렬되지 않았으므로
// wall 뒷 부분에 있는 것들을 다시 퀵 정렬 해준다.
quickSortWithLomuto(array, wall + 1, end);
return array;
}
console.log(quickSortWithLomuto([2, 5, 6, 1, 3, 4]));위 코드의 실행 결과는 다음과 같다.

사실 코드만 보면 이해가 쉽지 않기 때문에 손으로 과정을 따라가봤다.
조잡한 글씨지만 이해에 도움이 되기를 바랍니다 ㅠㅠ...
추가 사항
위에서는 in place 알고리즘으로 돌아간다고했고, 구현 방법도 그 방법으로 작성했지만
in place 가 아닌 방법으로도 구현할 수 있다.
다만, 그럴 경우 메모리 공간이 별도로 필요해지기 때문에 데이터 양이 많으면
공간 낭비가 심해져서 잘 쓰이지 않는다.
추가로, in place 가 아닌 방법으로 구현하면 Stable 한 정렬이 된다.
참고 자료
제이JY님의 tistory 블로그
인프런 Minseok Heo님의 성공적인 코딩 인터뷰를 위한 코딩 인터뷰 정복하기 - 코딩 테스트
춤추는 개발자님의 medium 블로그
