
보스턴 하우징 데이터셋을 활용한 주택 가격 예측
✔️ 보스턴 하우징 데이터 셋 케라스에 포함되어 있는 buston_housing 데이터를 이용해 주택 가격을 예측하는 회귀 문제를 구현할 수 있다.

우선 케라스에서 제공하는 boston_housing 데이터를 import해주고
train_data와 test_data를 호출하여 데이터 셋을 load해주었다.
이 데이터는 13개의 특성값을 가진 numpy배열로 구성되어 있고
train_data는 404개로 학습 샘플과 test_data는 102개의 테스트 샘플이 있는 2차원의 배열임을 확인할 수 있다.
✔️ 데이터 전처리-Scaling

특성의 스케일이 다른 값들을 신경망에 학습시키면 최적의 값을 찾는 것에 어려움이 발생한다.
그래서 우선 데이터를 표준편차를 이용해 정규화(표준화)를 시켜 각 특성의 범위를 동일하게 해준다.
(딥러닝에서는 minmax scailing보다 표준편차 scailing을 사용해주는 것이 더 좋다.)
mean = train_data.mean(axis=0)
➡️ train_data의 각 항목(축)의 평균을 구한다.
train_data -= mean
➡️ 전체 data에서 평균치를 빼면 각 특성의 평균이 0이 되도록한다.
std = train_data.std(axis=0)
train_data /= std
➡️ std함수로 표준편차를 구해준 후 train_data로 나눠주면 각 특성의 표준편차가 1이된다.
위와 같은 scaling 작업을 해주면, 각 특성이 다른 범위를 가지더라도
모든 특성이 동일한 범위를 갖게 해주어 모델 학습에 도움을 준다.
Scaling 작업을 거친 train_data의 배열은 13개로 동일한 것도 확인해볼 수 있다.
✔️모델의 구성
신경망 모델을 구현하기 앞서 필요한 모듈들을 아래와 같이 import해준다.

Sequential()은 선형적 연산하는 함수로 model 매개변수에 저장한다.
layer는 3개를 생성하였고 입력층과 중간층의 활성화 함수는 'relu'를 사용한다.
input_shape=(train_data.shape[1],)은 첫 번째 요소는 하나의 튜플(tuple)로 정의되며,두 번째 요소는 입력데이터의 특성 개수를 나타낸다.
샘플 개수를 지정하지 않았다면, 입력 데이터의 샘플 개수가 가변적인 경우에 사용할 수 있다.
마지막 층의 유닛은 집값이라는 1개의 값만 필요하므로, (1)을 지정해주었다.
옵티마이저는 'rmsprop', 회귀 알고리즘에서에서 손실은 'mse'라는 예측한 값과 실제 값 사이의 평균 제곱 오차를 사용하고, metrics도 동일하게 사용된다.
✔️ K-folder 검증을 사용한 훈련 검증
buston_housing 훈련 데이터 샘플이 404개로 적은 편에 속한다.
이때 사용하면 가장 좋은 검증 방법은 K-겹 교차 검증(K-fold cross-validation)을 쓰는 것이다.
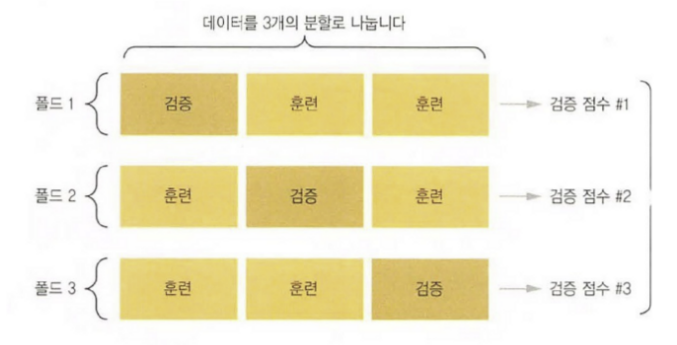
데이터를 K개의 분할로 나누고 K개의 모델을 각각 만들어
K – 1개의 분할에서 훈련하고 나머지 분할에서 평가하는 방법이다.
모델의 검증 점수는 K개의 검증 점수 평균이 된다.

총 404개 폴더를 k개로 나눠주면 한 폴더의 데이터수를 알 수 있다.
k=4 일때, 1개의 폴더의 사이즈는 101개가 된다.
이것을 반복하며 실험하기위해 all scores라는 변수에 미리 리스트 형태로 만들어준다.

검증 데이터, 학습 데이터, 모델 학습, 모델 검증까지 k번 반복하는 for for문에 i 루프 변수가 사용해 "처리중인 폴드 #i"에 출력된다.
✔️ 검증 데이터 준비 : k번째 분할

우선 학습용 데이터와 학습용 라벨을 잘라준다.
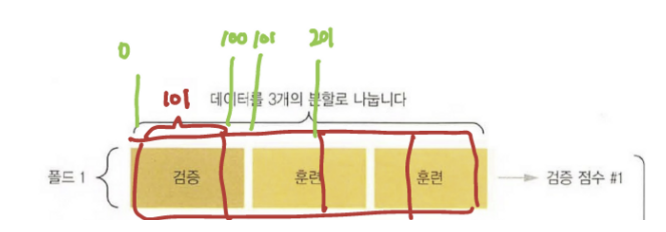
4개로 분할된 데이터의 각 폴더를 슬라이싱하여 끝점을 구해준다.
끝점을 알면 폴더 내 데이터를 쪼갤 수 있다.
✔️ 학습 데이터 준비 : 다른 분할 전체

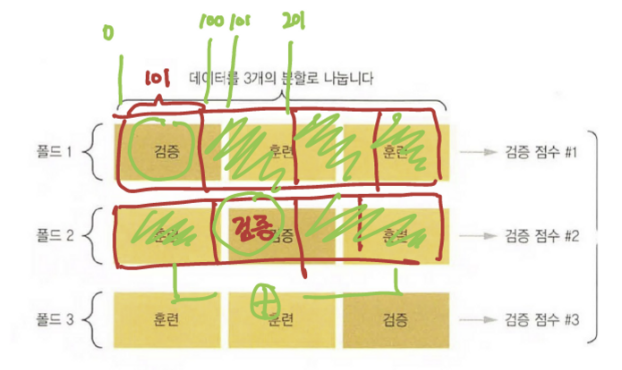
가운데 폴더는 4로 나눴기 때문에 2개(data1, data2)로 나눠서 저장해준다.
이 두 데이터의 구조가 똑같다면 numpy에 있는 concatenate 함수를 사용해 두개를 합쳐줄 수 있다. (data1, data2)의 각 데이터를 구해 대입해주면 된다.
하지만 이때 길이가 동일한 가로축으로 병합하기 위해 axis = 0 값을 준다.
✔️ 모델 학습 : 케라스 모델 구성(컴파일 포함)

404개의 데이터를 k=4개로 나누어 주었기 때문에, 4개가 100번씩 학습된다.
verbose=0이면 훈련상황을 생략한다. 바로 결과볼 수 있다.
verbose=1이면 훈련상황을 보여준다.
✔️ 모델 검증

이전까지 모델 검증 수행하는 메서드로 fit()함수를 사용했다.
fit()함수는 입력 데이터와 타깃 데이터를 모델에 제공해 가중치(w)를 조정하며 최적의 가중치를 찾는 것이다.
검증 데이터에 대한 성능 지표로 accuracy, loss 등을 사용한다.
evaluate()함수는 학습된 모델의 성능을 평가하는 메서드이다.
입력데이터와 타깃 데이터를 모델에 제공하여, 입력데이터를 예측한 결과와 타깃 데이터 간의 차이를 계산한다. 이를 통해 모델의 일반화 성능을 평가하고, 검증 데이터에 대한 성능 지표를 계산한다.
즉, fit()함수는 모델을 학습하면서 모델의 성능을 평가하는 역할을 수행.
evaluate()함수는 학습이 완료된 모델의 성능을 평가하는 역할을 수행한다.
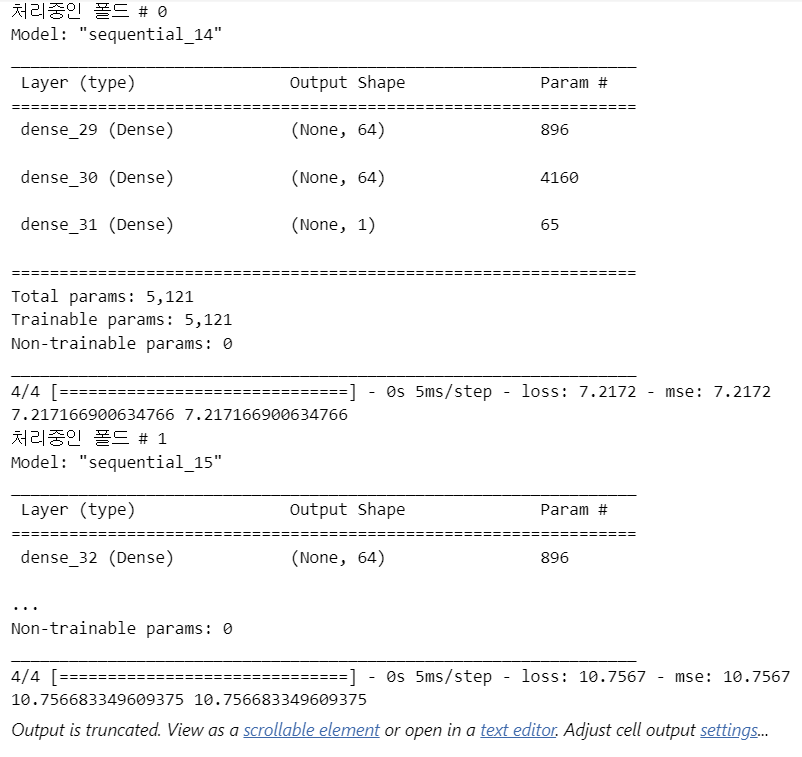
같은 성능이면 params(모델의 학습 가능한 파라미터 수)계수가 낮아야 좋다.
모델이 더 적은 학습 가능한 파라미터로도 같은 수준의 성능을 내기 때문이다. 즉, 효율적인 모델이라고 할 수 있다.

검증된 데이터의 성능 지표와 all_scores 배열의 평균값을 비교하였다.
비슷한 결과 값을 확인했고 이는 모델이 일관된 성능을 보인다는 것을 의미한다.
