
로이터 데이터 셋을 활용한 뉴스 기사 분류
✔️ 로이터 데이터셋
케라스에 포함되어 있는 로이터 데이터셋을 이용해 뉴스기사를 분류하는 과정을 구현해본다.

위와 같이 필요한 모듈을 import해준다.
num_words=10000 매개변수는 데이터에 가장 자주 등장하는 단어 10000개로 제한한다.
✔️ 데이터 준비
레이블을 벡터로 바꾸는 방법은 2가지가 있다.
첫 번째는 레이블의 리스트를 정수 tensor로 변환하는 것
[참고] 영화리뷰 분류
두 번째는 원-핫 인코딩은 레이블의 인덱스 자리는 1이고
나머지는 모두 0인 벡터이다.

vectorize_sequences 함수는 정수로 이루어진 리스트 ‘sequences’와
one-hot-incoding된 벡터의 차원 ‘dimesion’은 기본값이 10,000으로 설정.
zero(len(sequences), dimension)은 크기가 (len(sequences), dimension)이고
모든 원소가 0인 2차원 행렬로 인코딩 된다.
for문을 통해 sequence 리스트에 서 각각의 시퀀스를 반복.
enumerate() 함수는 순서가 있는 자료형(list, tuple, dictionary, string)을
입력받아 인덱스 값을 포함하는 enumerate 객체를 리턴한다.
results[ i ]에서 특정 인덱서의 위치를 1로 반환한다.

데이터를 벡터로 변환하는 것은 뉴럴 네트워크를 투과하는 과정에서
행렬끼리의 연산이 필요하기에 데이터를 벡터로 변환해주어야 한다.
vectorize_sequences함수를 사용해 각각 학습용 데이터와
테스트 데이터를 벡터로 변환하여 저장해준다.

- 라벨 데이터를 카테고리 데이터로 One-Hot incoding해주는 이유는?
수치에 대한 정보에 초점을 맞추기 위해서 사용한다.
예를 들어, 아이스크림의 종류를 분류하는 문제라면,
아이스크림 종류가 (메로나, 바밤바, 비비빅)이렇게 3가지 종류가 있다고 가정해 이를 라벨 데이터로 사용하게 된다면 (0,1,2)로 표현된다.
여기에서 1+1=2라고 처리를 하게되면, '바밤바+바밤바=비비빅'이라는 공식이 적용되게 된다. 각 카테고리의 특징을 반영하고 수치적 특성을 없애주기 위해 라벨 인코딩을 대신 원핫 인코딩으로 특징을 반영하고 수치적 특성을 없애주기 위해 one-hot 인코딩으로 카테고리 데이터로 변환시켜주는 것이다.
✔️ 신경망 모델 제작
to_categorical()함수를 사용하여 레이블을 One-Hot 인코딩할 수 있어
필요한 모듈을 우선 import 해준다.

sequential() 선형적 연산을 하는 모델 함수를 사용한다.
모델의 layer는 3개를 만들어주었다.
입력층과 중간층의 Dense 유닛 개수는 64개, 활성화함수는 'relu',
input_shape(10000,)은 1차원의 10,000개 요소를 가지는 입력모양으로 지정해준다.
출력층은 다중 분류데이터의 마지막층에서 사용되는 softmax 활성화 함수를 사용한다.

옵티마이저는 'rmsprop', 손실 함수로 'categorical_crossentropy',
metrics평가는 'accuracy'을 사용해 모델을 컴파일 해준다.
✔️ 훈련 검증 1
데이터가 학습하는 동안 학습 데이터에 대한 모델의 정확도를 측정해 매개변수에 지정한다.

10,000개의 샘플 데이터를 쪼개서 검증하기 위해 위와 같이 준비해준다.

학습 반복 횟수 epochs는 20번, 학습 데이터 개수 batch_size는 512개를
vaildation_data 각각의 매개변수에 검증 데이터를 전달한다.
✔️ 그래프 시각화
그래프 시각화를 위해 우선 matplot 모듈을 import해준다.

학습 데이터의 손실과 정확도,
검증 데이터의 손실과 정확도를 각 매개변수에 저장한다.

위 colormap 설정값과 라벨을 지정해 아래와 같은 그래프를 시각화한다.
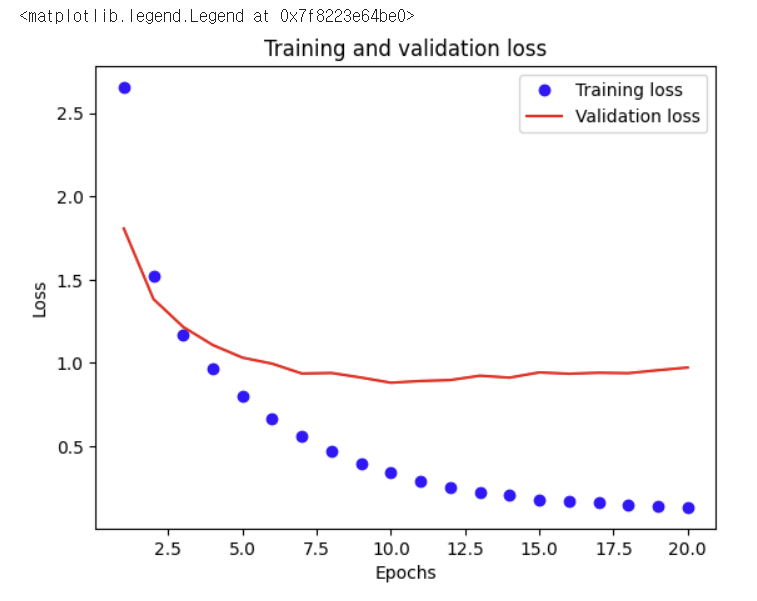

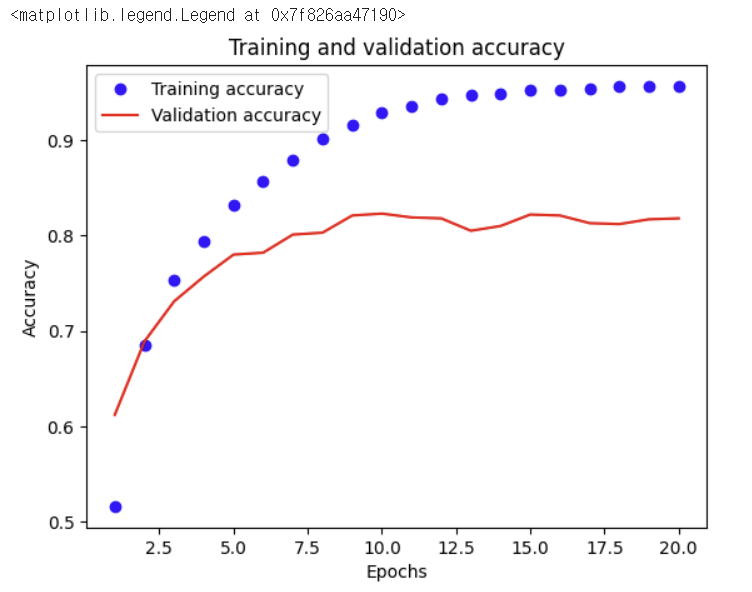
✔️ 훈련 검증 2
검증된 결과로 모델을 다시 학습시키고 평가한다.

1번째 훈련 검증에서 10번째 epochs가 가장 좋았던 것을 확인할 수 있었다.
그래서 2번째 검훈련 검증에서 epochs 값을 20에서 10으로 바꿔주었다.

모델의 정확도는 78%로 이고 손실은 0.97이라는 결과를 얻어냈다.
