
- 전체보기(26)
- opencv(5)
- 머신러닝(4)
- 분석 절차(1)
- 합성곱(1)
- 과대과소(1)
- 프로세스(1)
- MDP(1)
- sigmoid(1)
- sharpening(1)
- 쓰레드(1)
- matcher(1)
- confusion matrix(1)
- OOP(1)
- 다채널 합성곱(1)
- corner(1)
- ubuntu(1)
- ROC(1)
- 엣지검출(1)
- dataloader(1)
- histogram(1)
- AI 기반 압축 모델(1)
- opencv 특징점(1)
- 로버츠(1)
- CNN과정(1)
- Markov Decision Process(1)
- perspective(1)
- 프리윗(1)
- blurring(1)
- 적합(1)
- 기계학습(1)
- 프로토콜(1)
- 무손실 압축(1)
- ReLU(1)
- affine(1)
- Dzip(1)
- 블러링(1)
- 소벨(1)
- Tanh(1)
- 샤프닝(1)
- 우분투 한글(1)
- dnqnsxn gksrmf(1)
- CNN(1)
산술부호화(Arithmetic coding)
산술 부호화는 주어진 메시지를 더 작은 비트 시퀀스로 압축하는 엔트로피 부호화 방법 중 하나이 방법은 메시지 전체를 하나의 숫자로 표현하여, 기호의 빈도에 따라 효율적으로 데이터를 압축합니다. 기호의 확률메시지를 구성하는 각 기호의 출현 확률을 계산한다.이 확률은 기호
Dzip(deepzip v2)
Deepzip의 두번째 버전인 Dzip첫번째 버전 출처 : https://github.com/mohit1997/DeepZip두번째 버전 출처 : https://github.com/mohit1997/Dzip-torch확률적 데이터 모델링을 따르는 예측
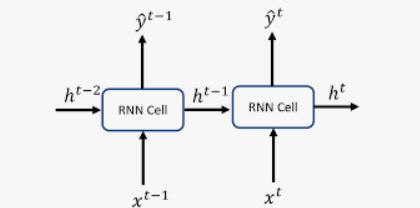
순환 신경망 RNN
RNN(Recurrent Neural Network)은 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층으로 보내면서 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징을 가지고 있다.x는 입력층의 입력 벡터이고 y는 출력층의 출력 벡터이다.RNN 은닉층에서
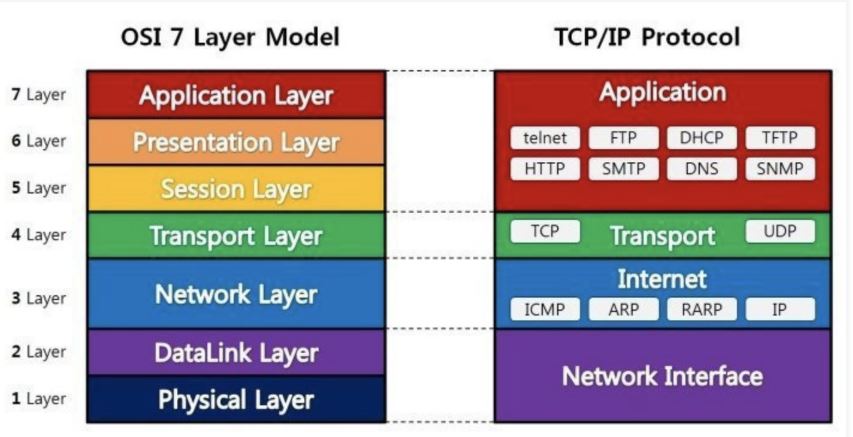
TCP/IP
보통 하나로 부르지만 TCP와 IP는 별개이다. 네트워크의 경우 계층이 정의되어있고 각 계층마다 하는 역할과 책임지는 영역이 나눠져있다.TCP를 알기전에 네트워크 계층을 이해해보자.OSI 7 계층은 국제표준화기구(International Standard Organiza
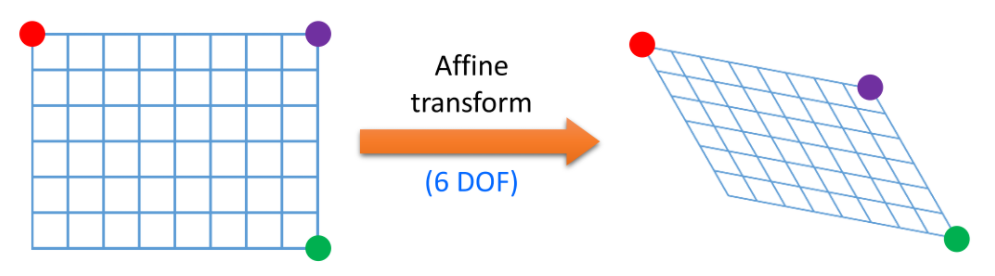
어파인 변환과 투시 변환
어파인 변환 : 영상을 평행 이동시키거나 회전, 크기 변환, 전단 변환 등을 통해 만들 수 있는 변환을 통칭한다.영상에서 어파인 변환을 적용할 경우, 직선은 그대로 직선으로 나타나고, 직선 간의 길이 비율과 평행 관계가 그대로 유지된다. 어파인 변환에 의해 직사각형 영
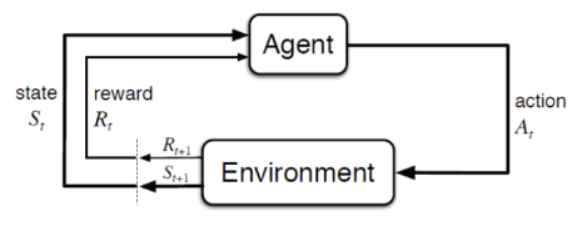
강화학습 (Markov Decision Process)
Agent(에이전트)가 Environment(환경)와 상호작용하며 강화학습의 목표는 Environment(환경)에서 Agent가 최대 reward를 얻을 수 있도록 Agent(에이전트)를 학습하는 것이다.캡Agent(에이전트) : 주어진 문제 상황에서 행동하는 주체이다
객체지향 프로그래밍
프로그램 설계 방법론으로 프로그램을 단순히 데이터와 처리 방법으로 나누는 것이 아니라, 프로그램을 수 많은 객체(object)라는 기본 단위로 나누고 이들을 상호 작용으로 서술하는 방식큰 문제를 작게 쪼개는 것이 아니라, 먼저 작은 문제들을 해결할 수 있는 객체들을 만
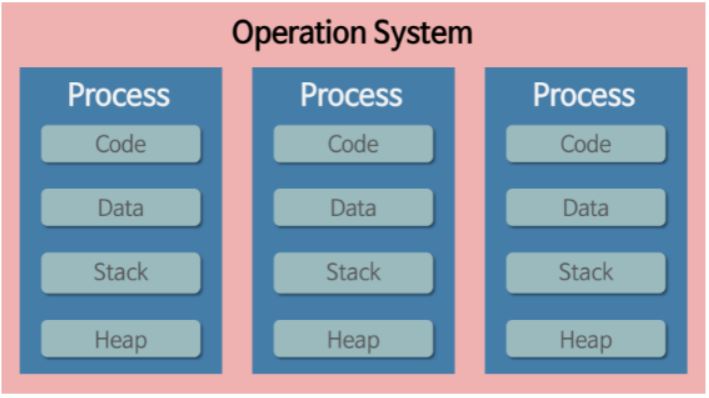
프로세스와 쓰레드
출처 : https://gmlwjd9405.github.io/2018/09/14/process-vs-thread.html멀티코어를 가진 CPU가 보편적이기 때문에 멀티 코어를 활용할 수 있어야한다.프로세스는 사용 중인 파일, 데이터, 프로세서의 상태, 메모리
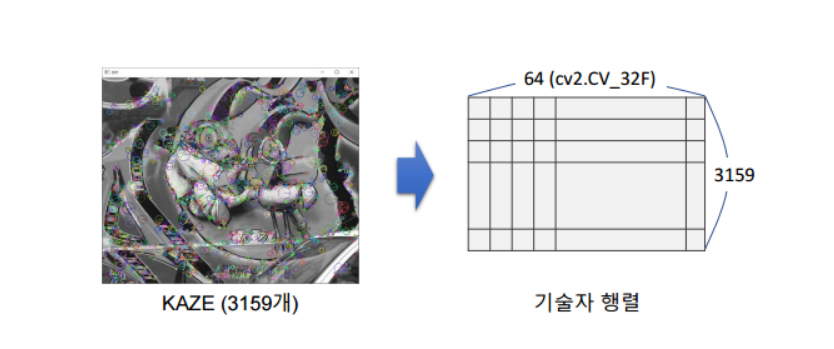
특징점 매칭
특징점 매칭은 특징점을 검출하고 특징점 주변의 정보(기술자)를 통해서 매칭한다.기술자는 서로 다른 영상에서 특징점이 어떤 연관성을 가졌는지 구분하게 하는 역할을 한다.기술자는 검출된 특징점 근방의 영상을 표현하는 실수 또는 이진 벡터이다. 영상의 방향, 밝기, 크기,
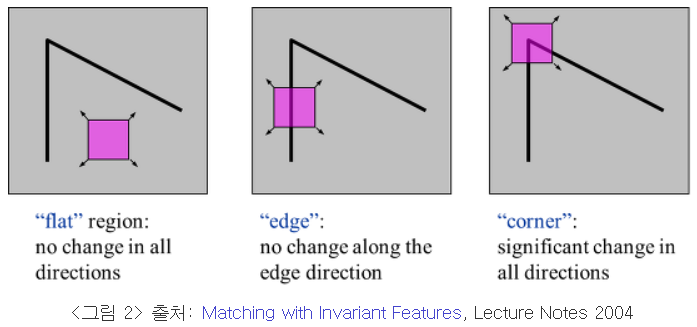
특징점 추출
Harris corner 1988 SIFT 2004 FAST 2006 영상 특징점이란?영상에서 물체를 추적하거나 인식할 때, 영상과 영상을 매칭할 때 가장 일반적인 방법은 영상에서 주요 특징점을 뽑아서 매칭하는 것이다. 특징점을 영어로는 보통 keypoint 또는
pytorch DataLoader
튜토리얼을 기반으로 적어보는 사용자 정의 DataLoader출처 : https://tutorials.pytorch.kr/beginner/basics/data_tutorial.html기본형\_\_init\_\_ 함수는 Dataset 객체가 생성(instantia
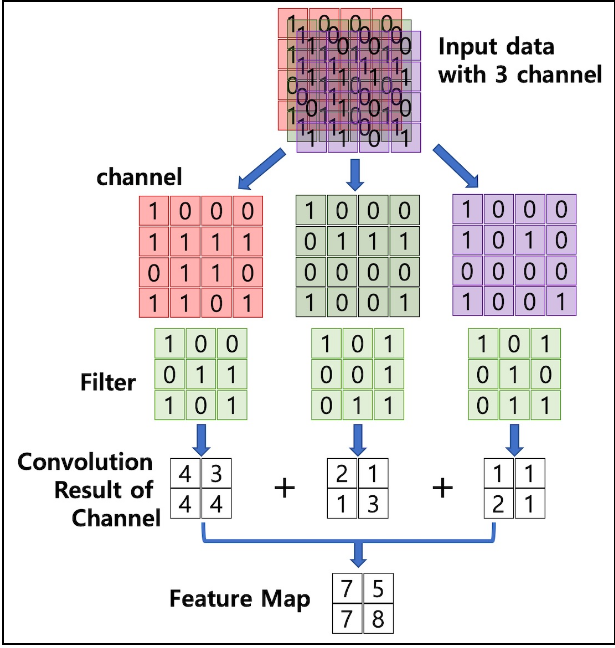
CNN 다수 채널의 합성곱
CNN의 합성곱을 설명하는 블로그에 가보면 1채널 이미지, 3채널 이미지에 대해서 convolution 연산을 설명하고 있다. 초기 입력 convolution에 대한 이해는 가지만 다양한 모델을 보게되면 여러층을 쌓아서 convolution을 하기 때문에 중간 단계의
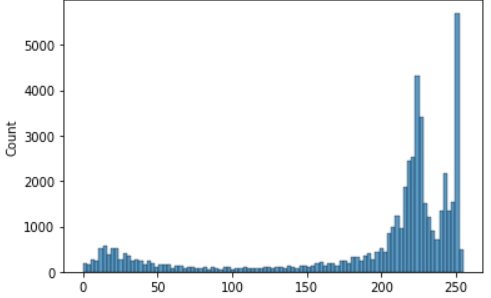
opencv_pixel_2
히스토그램은 어떤 데이터가 얼마나 많은지를 나타내는 도수 분포표를 그래프로 나타낸 것히스토그램을 사용하면 데이터의 분포 상태를 한눈에 쉽게 알아볼 수 있다. 화소의 분포를 나타내는 지표이기 때문에 이 분포를 이해하면 이미지, 영상의 특성을 판단할 수 있는 유용한 도구가

opencv_pixel_1
이해하기 쉽게 흑백 이미지를 예로 들어서 이미지의 밝기 처리를 해본다.opencv GRAYSCALE 흑백이미지 한 픽셀의 데이터 사이즈를 보통 uint8로 정의하는데 0 ~ 255 범위를 갖게된다. 다음은 화소값의 변화에 따른 이미지의 밝기 변화이다.관심영역의 이미지
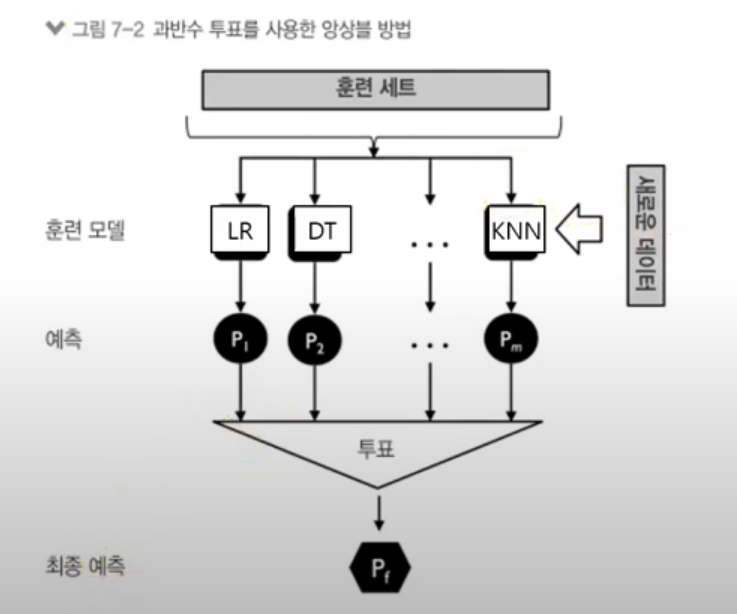
앙상블
앙상블 학습이란과반수 투표 분석배깅 분석랜덤 포레스트 분석부스팅 분석여러 분류기( 모델 )를 하나의 메타 분류기로 연결( 통합한다는 의미가 강하다) 하여 개별 분류기보다 더 좋은 일반화 성능을 달성여러 분류 알고리즘 사용 : 다수결 투표하나의 분류 알고리즘 이용 : 배
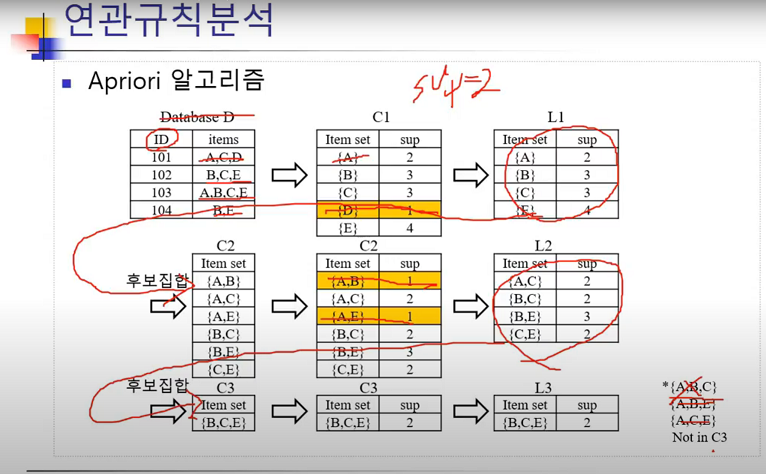
연관규칙
마케팅 전략상 유용한 결과가 나온 경우ex) 주말을 위해, 목요일 소매점에 기저귀를 사러 온 아빠들은 맥주도 함께 구매 -> 주말에 football을 보면서 마심기존의 마케팅 전략에 의해 연관성이 높게 나온 경우ex) 정비 계약을 맺은 소비자들은 많은 설비를 구매 ->
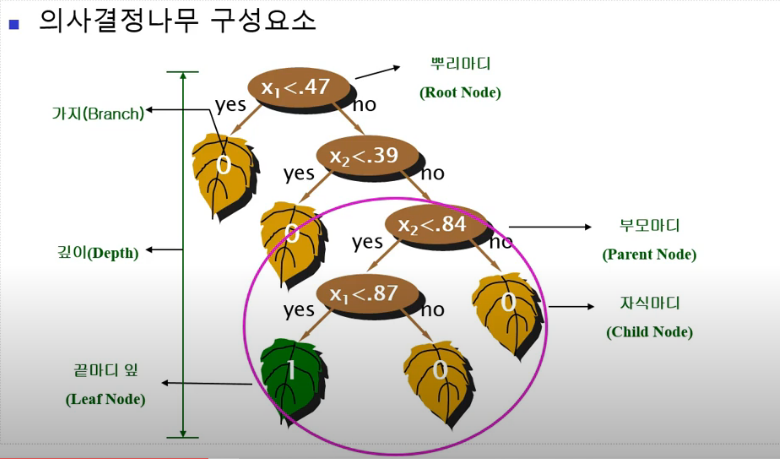
의사결정나무
의사결정규칙(decision rule)을 나무 구조로 도표화하여 분류(classification)와 예측(prediction)을 수행하는 분석 방법Tree and rule 구조규칙(rule)은 나무 무델로 표현결과는 규칙으로 표현재귀적 분할 나무 만드는 과정 -> 계속
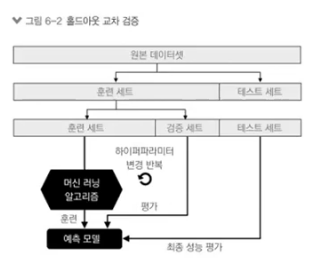
모델 최적화
모델의 성능을 검증하기 위한 방법홀드아웃 검정K-fold 검정홀드아웃 검정훈련 데이터 / 테스트 데이터를 나눈다.훈련 데이터로 모델을 만든다.테스트 데이터로 성능 평가문제점 모델을 변경하는 방법론최적화 파라미터를 찾기 어렵다. ( max_depth...) 일일이 대입해
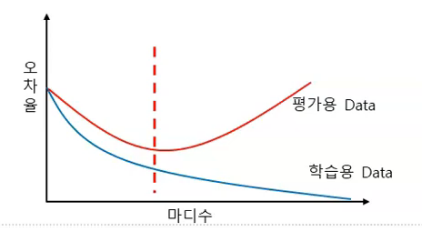
과대,과소적합
학습용 데이터에 완전히 적합학습용 집합에서 잡음(noise)도 모형화하기 때문에 평가용 집합에서 전체 오차는 일반적으로 증가학습용 Data에서는 높은 성과 => 평가용 Data에서는 낮은 성과 ( x )현재 데이터의 설명 => 미래 데이터 예측 ( O )훈련, 검증 정
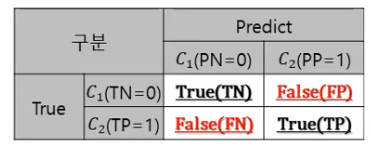
confusion matrix
대칭적 상대적인 표현들정확도(Accuracy) vs 오류율(Error Rate) TPR (True Positive Rate) vs FPR ( False Positive Rate)민감도 vs 특이도재현율 vs 정밀도정확도 : 클래스 0과 1 모두를 정확하게 분류오류율