인공 지능 기반 범용 압축 모델 Dzip
- Deepzip의 두번째 버전인 Dzip
첫번째 버전 출처 : https://github.com/mohit1997/DeepZip
두번째 버전 출처 : https://github.com/mohit1997/Dzip-torch
abstract
- 확률적 데이터 모델링을 따르는 예측 기반 인코딩(무손실 압축 모델)
- Dzip은 예측을 위한 신경망과 산술 코딩으로 모델링한 시퀀셜 데이터 압축기이다.
- Dzip은 하이브리드 아키텍처를 가지고 있는데 적응형과 세미-적응형(반적응형) 학습을 기반으로 한다.
- 기존의 신경망 기반의 압축기들과는 달리, Dzip은 추가적인 학습 데이터가 필요하지 않고 특정 데이터에 제한되지 않는다.
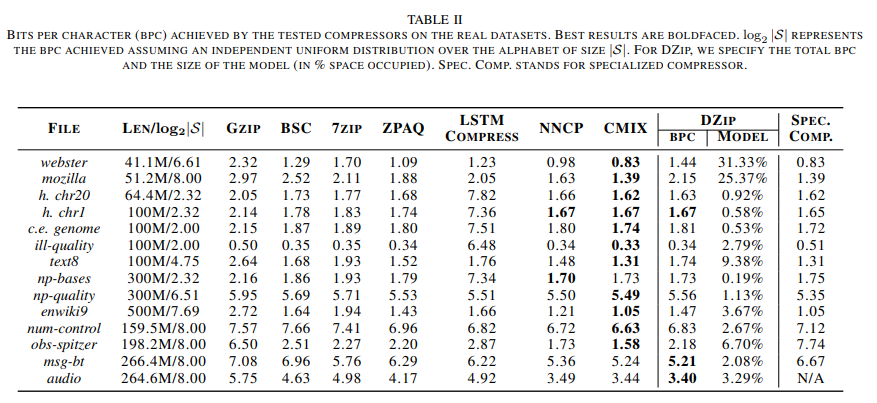
- Gzip(평균 29% 크기 감소), 7zip(평균 12% 크기 감소)와 같은 범용 압축기보다 뛰어났으며, 특수 압축기와 비슷한 성능을 보여준다.
- Dzip의 한계는 인코딩/디코딩 속도가 느리다는 것이다.
- 코드 출처 : https://github.com/mohit1997/Dzip-torch
Dzip 모델의 기여
- 입력 파일을 바이트 스프림으로 다루며 추가적인 학습 데이터 셋이 필요하지 않다.
- 기존 신경망 기반 압축기와 다르게 알파벳 크기에 관계없이 모든 데이터를 압축할 수 있는 독자적인 압축기이다.
- 하이브리드 학습(적응형 및 세미 적응형) 접근 방식 사용한다.
- 여러 도메인의 데이터를 압축해보았는데 Gzip보다 평균 29%, LSTM-Compress보다 33%, 7zip 보다 12%, BSC 보다 8% 개선됨을 확인하였다.
- state-of-art인 신경망 기반 압축기 CMIX와 NNCP 비교하면, Dzip이 CMIX보다 3~4배 빠르고 NNCP보다 4배 빠른 동시에 비슷한 성능을 보여준다.
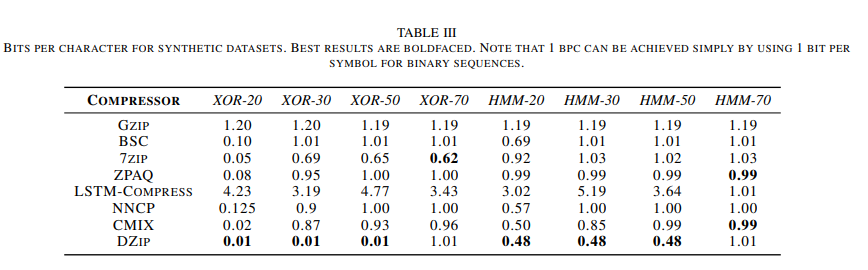
- 특정 합성 데이터셋(엔트로피)에서 다른 압축기들보다 뛰어난 성능을 보여준다.
배경
- 예측 모델 다음에 산술 코더로 구성된 통계적 코딩 접근법이다.
- 알파벳 S 로 데이터 스트림 S^N = {S1, S2, S3 ... SN} 을 무손실 압축한다.
- 확률 모델의 목적은 시퀀스 S^N에 대해, r 번째 Sr 부호의 조건부 확률 분포를 추정하는 것이다.
- Sr은 이전까지 관찰된 K 부호를 기반 P(Sr | Sr-1 ... Sr-K) 확률 추정이다.
- 이 확률 추정과 Sr은 산술 코더 블록으로 들어가며 반복적으로 상태가 업데이트된다.
- 이러한 접근법은 압축된 사이즈의 크기와 크로스 엔트로피 로스(cross entropy loss)가 같아지게 된다.
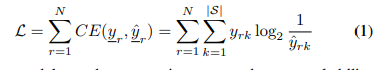
- 위 식에서 |S|는 알파벳 사이즈이며, y, y'는 원핫 인코딩된 정답값과 예측된 확률값이며 N은 시퀀스 길이이다.
- 확률을 추정하는 모델은 크로스 엔트로피 로스(cross entropy loss)를 최소화하기 위해 학습된다. 확률을 추정하는 모델을 학습시키는 3가지 방식이 있다.
확률 추정 모델 학습 방법
-
정적(static) : 외부 훈련 데이터를 가지고 훈련되어지고 압축과 압축 해제에 사용된다. 성능은 모델의 일반화 능력에 의존한다. 이 접근법은 비슷한 훈련 데이터가 가능한 경우에만 사용된다.
-
적응형(adaptive) : 압축과 압축 해제가 시퀀스에 적응하며 업데이트되는 랜덤으로 초기화된 모델이다. 이 접근법은 학습하는 데이터의 유효성을 요구하지 않으며 작은 모델에서는 잘 작동한다. 그러나 큰 모델에서는 변화하는 통계에 빠르게 적응하기 어렵다.
-
세미 적응형(반적응형:semi-adaptive) : 입력 시퀀스를 기반으로 학습되고 학습 절차에 멀티 패스가 포함한다. 학습된 모델의 파라미터들은 압축된 파일에 포함된다. 최소 설명 길이(Minimum description length)원칙에 따라 정확한 모델과 모델의 파라미터를 저장하는데 필요한 비트 사이의 트레이드 오프가 있다. 모델이 클수록 압축이 향상될 수 있지만, 소규모 데이터 세트의 경우 모델 자체의 크기가 커질 수 있어 압축이 저하될 수 있다.(압축 데이터에 압축 모델 파라미터 포함되어 있기 때문)
방법
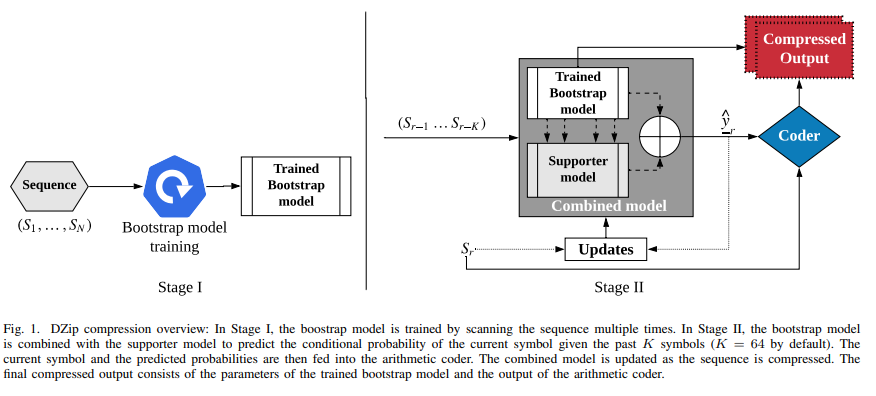
- 세미 적응형과 적응형 학습 방법을 사용하여 하이브리드 학습 방식이라고 할 수 있다.
- bootstrap 모델은 RNN 학습을 기반으로 하며 세미 적응형 방식을 사용한다.
- supporter 모델은 미리 정의된 의사 랜덤 매개변수로 초기화된 큰 신경망이다.
- bootstrap 모델의 압축 성능 향상을 위한 모델이다.
- bootstrap과 supporter 모델의 출력은 최종 예측을 위해 결합된다.
- combined 모델의 파라미터는 인코딩 도중 적응형으로 업데이트된다.
모델 아키텍처
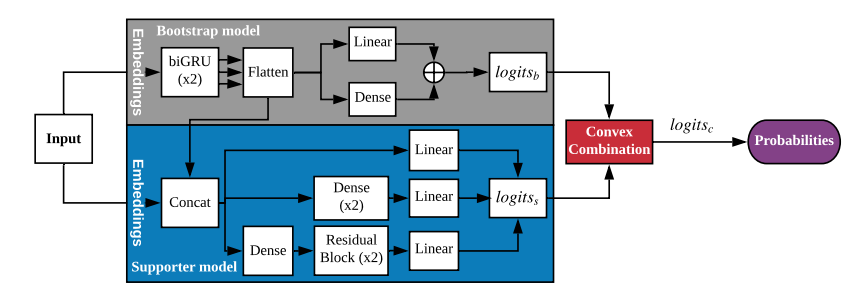
bootstrap 모델
- bootstrap 모델의 아키텍처는 모델 사이즈와 예측 능력 사이 트레이트 오프를 유지할 수 있도록 디자인되었다.
- 임베딩 레이어와 biGRU 레이어 다음에 선형 레이어와 밀집 레이어가 온다.
- 기본(default)으로 16(m)번째 타임 스텝 후 biGRU 레이어의 출력들은 하나의 벡터로 쌓이(stacked)고 평탄화(flattened)됨.
- 16(m)번째 출력은 다음 레이어의 파라미터를 줄이는 데 도움이되며 장기 의존성을 학습할 수 있도록한다.
- 작은 bottleneck dense 레이어는 아키텍처의 깊이를 증가시킨다.
- 레이어 출력은 스케일화 되지 않은 확률(log)이며 logits_b이다.
- dense layer가 장기 의존성을 학습하기 때문에 합성 데이터에서 좋은 성능을 보여준다.
- 입력 vocabulary 사이즈에 의해 자동으로 layer width가 결정된다.
- vocabulary 사이즈는 다양하며 임베딩 벡터 차원은 8 ~ 16, biGRU의 은닉 상태는 8 ~ 128 차원, dense layer의 width는 16 ~ 256 이다.
- 위 하이퍼 파라미터는 경험적으로 얻어진 결과이다.
supporter 모델
- supporter 모델의 아키텍처는 bootstrap 모델보다 데이터에 빠르게 적응하고 더 나은 확률 추정을 제공하기 위해 만들어졌다.
- 입력이 임베딩 레이어로 구성되며 3개의 sub-NNs 구성되어있다.
- 첫번째 sub-NN은 선형으로 빠르게 학습하며, 두번째는 2개의 dense layer, 세번째는 residual block을 사용하여 복잡한 패턴을 학습할 수 있다.
- ReLU를 모든 dense layer와 residual layer에 사용하였다.
- 각 sub-NNs 출력은 선형 layer를 통해 vocabulary 차원과 같아지며 모두 더해진 최종 출력은 logis_s이다.
- dense layer와 residual layer는 vocabulary 사이즈에 따라 자동적으로 1024 또는 2048 로 정해진다.(github 참고)
combined 모델
- combined 모델은 boostrap의 출력 logits_b와 supporter의 출력 logits_s를 공식에 의해 최종 logits_c로 만든다.
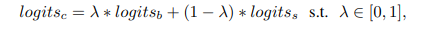
- 람다(ㅅ)는 학습 파라미터로 시그모이드 활성화 함수를 통해 0과 1사이 값을 갖는다.
- 학습을 통해 더 나은 모델에 가중치를 더 주며 학습되며 최종 출력 logits_c는 softmax 활성화 함수에 의해 확률이 출력된다.
모델 학습
- Dzip 모델의 첫번째로 입력 데이터의 vocabulary 사이즈를 선택한다.
- vocabulary 사이즈에 의해 boostrap과 supporter 모델의 하이퍼 파라미터가 자동을 지정된다.
- 모델은 8 에폭, 배치사이즈 2048, 그래디언트 클립핑, 아담 옵티마이저(learning rate 0.005)를 사용한다.
- 작은 데이터 셋에는 bootstrap 모델의 충분한 학습을 위해서 에폭을 증가시켜도 된다.
- 훈련 후, 모델은 무손실 압축기 BSC에 의해 압축된 파일의 일부로 저장되어진다.
combined 모델(Hybrid)
- 이 모델은 학습된 boostrap 모델과 랜덤으로 파라미터가 초기화된 supporter 모델을 사용한다.
- bootstrap 모델의 파라미터는 고정되며 인코딩, 디코딩 동안 supporter 모델은 최적화된다.
- 한 번에 하나의 부호를 인코딩하는 시간이 매우 느리기 때문에 시퀀스를 64개의 동일한 사이즈로 나누고 하나의 배치에서 각 부분에 대해 확률을 생성하는 공통 모델을 사용한다.
- 원핫 벡터로 y를 인코딩 후 아래 손실 함수를 통해서 모델을 최적화 한다.
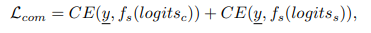
- f는 softmax이며 CE는 cross entropy이다.
- 가중치 업데이트는 (각 파트의)20개의 부호를 인코딩(또는 디코딩) 후 수행된다.
- learning rate 를 낮게(0.005)를 유지하여 발산을 방지한다.
- 모델을 업데이트하기 위해서 아담 옵티마이저(B1 = 0, B2 = 0.999)이다.
Only bootstrap 모델
- 시퀀스는 1024개의 부분으로 나눠지고 각 부분의 첫 K 부호는 균일한 확률을 사용하여 인코딩된다.
- 이 모드에서 사용된 배치 사이즈는 1024이며, 64인 combined 모델 접근 방식과 반대된다.
- bootstrap 모델로 부터 얻어진 확률 추정을 사용하여 각 부분에서 K + 1 번째 부호를 인코딩한다.( 각 부분에 대한 확률은 하나의 배치에서 끝난다 )
- 이 절차는 모든 부분들이 인코딩될때까지 반복된다.
- 시퀀스 길이는 인코딩된 파일의 일부로 저장되고 디코딩은 대칭적으로 수행된다.
결과
real 데이터셋 압축 결과
합성 데이터셋 압축 결과
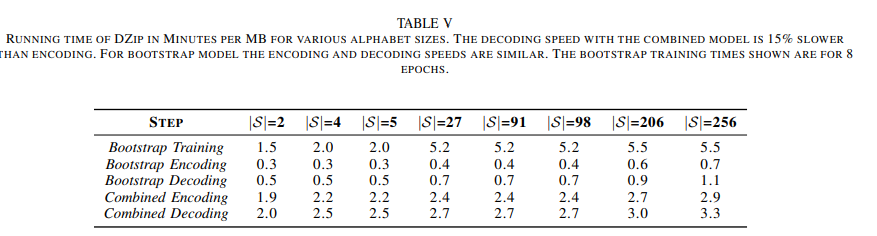
only bootstrap 모델과 combined model 사이의 트레이드 오프
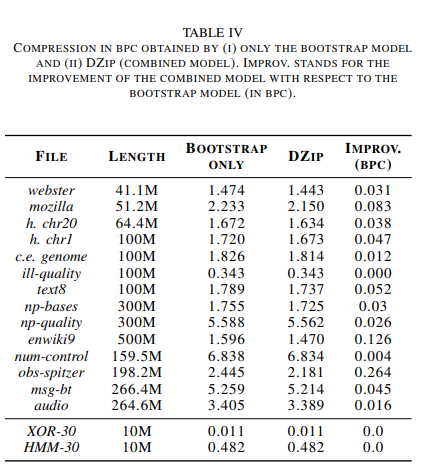
-
(real 데이터셋 기준)combined model이 only bootstrap 모델보다 평균 0.055 bpc 성능이 좋았음
-
only bootstrap 모델이 combined 모델보다 평균 1.5 ~ 4배 빨랐다.
-
또한 only bootstrap 모델이 Gzip, 7zip, BSC, LSTM-Compress 보다 성능이 좋다.
