LLM Alignment
1.Proximal Policy Optimization (PPO) 간단 정리
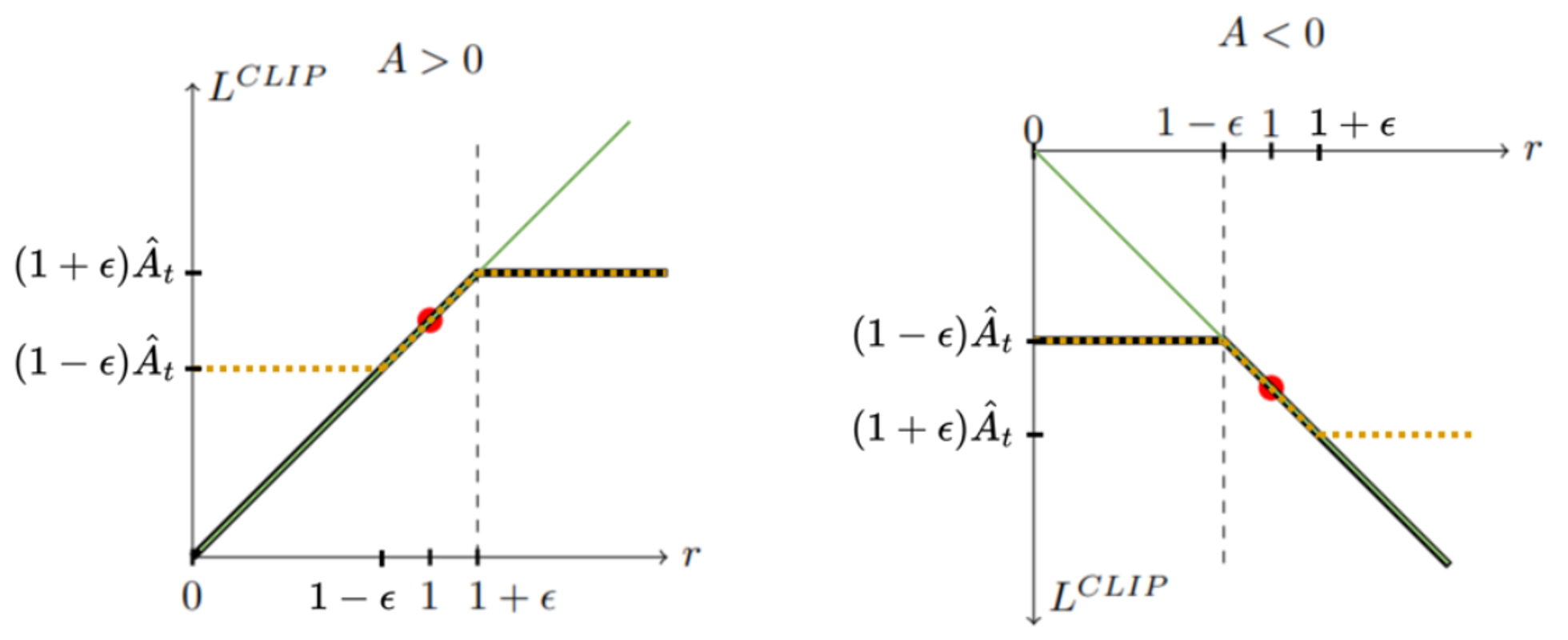
GPT-3.5, RLHF의 바로 그 강화 학습 알고리즘. PPO 살펴보기
2024년 8월 29일
2.RL by Human Feedback (RLHF) 간단 정리
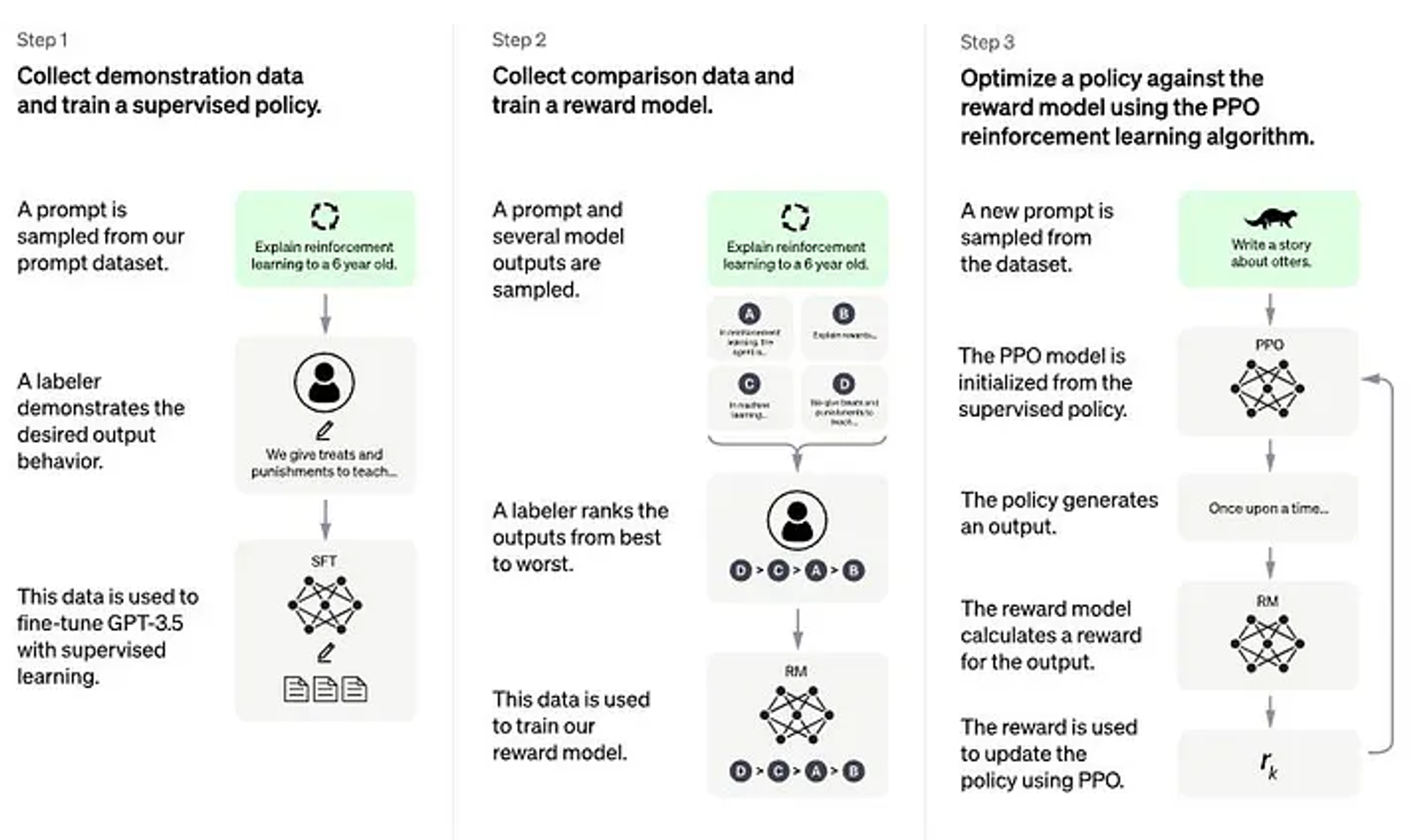
GPT를 ChatGPT로! 현대 LLM preference optimization의 시초, RLHF 살펴보기
2024년 8월 29일
3.Direct Preference Optimization (DPO) 간단 정리
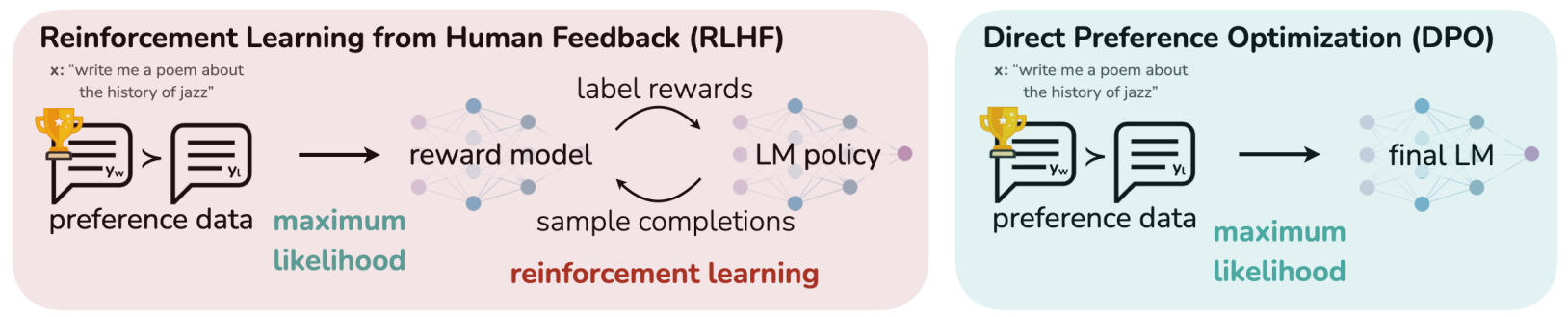
RL 모델 없는 preference optimization, DPO 살펴보기
2024년 8월 29일
4.Direct Alignment from Preference (DAP) 방법론 간단 비교
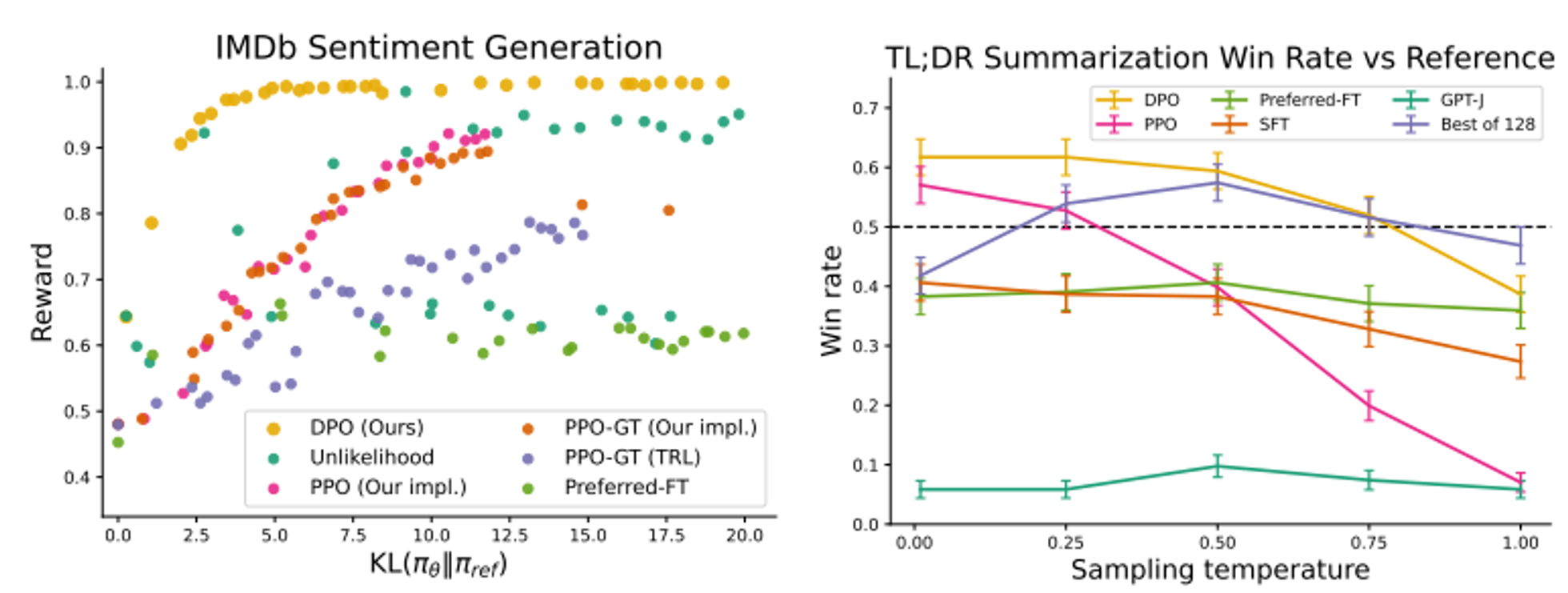
RL 없는 preference optimization, DAP 방법론들 비교하기: SLiC-HF, DPO, IPO, RRHF
2024년 8월 29일