RLHF의 컨셉
ChatGPT vs GPT-3
- ChatGPT는 개방형 도메인 대화를 위해 특별히 설계된 GPT-3.5(InstructGPT)에 기반해 만들어진 모델
- OpenAI는 ChatGPT를 생성하기 위해 2022년 초반 학습된 GPT-3.5를 finetuning하였고, InstructGPT와 동일한 방법을 사용했으나 데이터 수집 설정이 조금 달랐다고 함
- ChatGPT는 GPT-3와 크게 두 가지 차이가 있음
- 대화형 AI
- 사람과 대화를 주고 받기 위해 챗봇 형태로 튜닝된 모델
- LLM alignment 문제 완화
- 엄청난 양의 데이터를 학습한 LLM은 인간과 유사한 텍스트를 생성할 수 있게 되었으나, (1) 유용성 부족(지시 불이행), (2) hallucination, (3) un-explainable, (4) biased or toxic 텍스트 생성과 같은 문제가 있었음
- 이를 해결하기 위해 SFT와 RL을 모두 활용한 튜닝을 했으며, 이 때 사용된 RL 기술이 바로 RLHF
- 대화형 AI
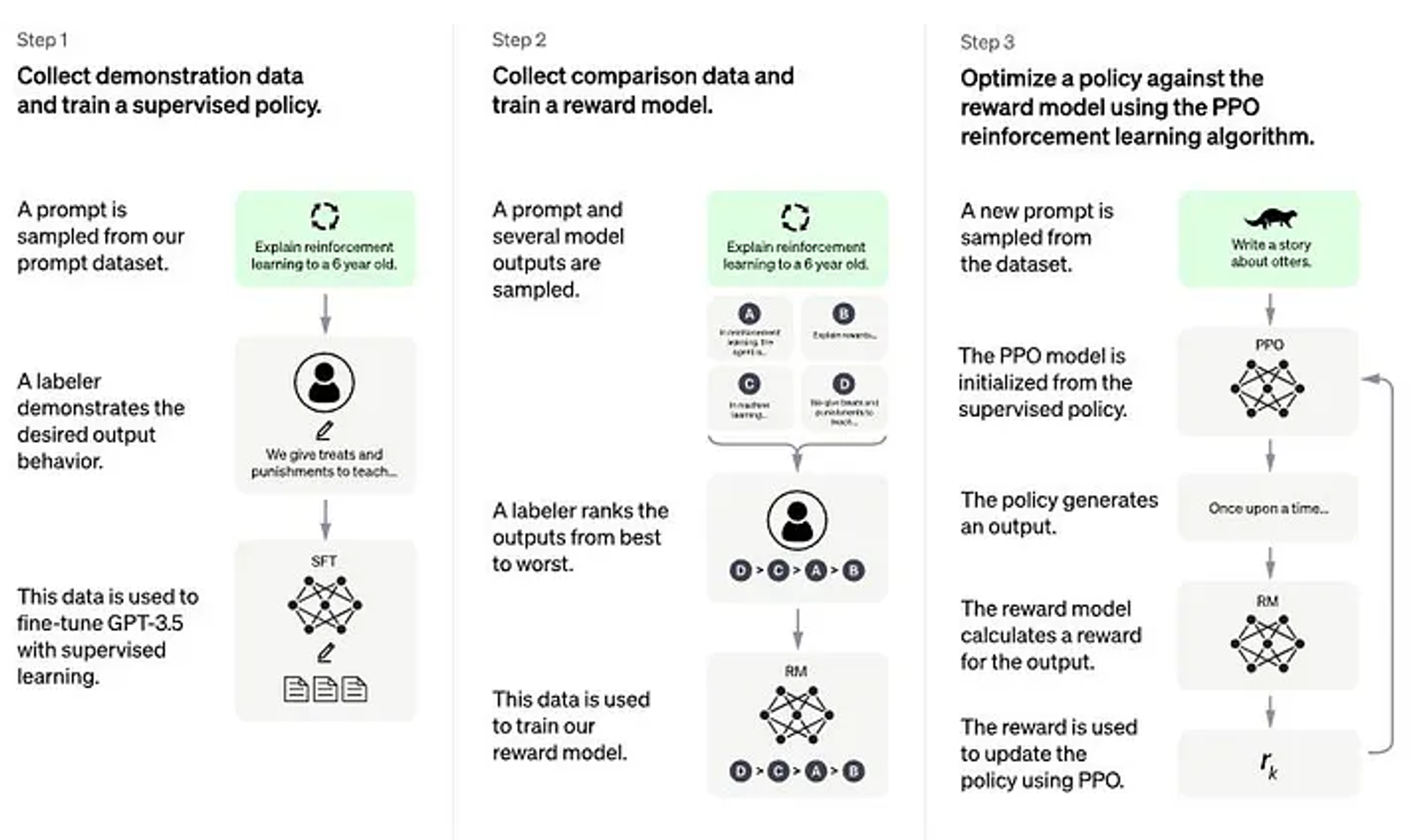
InstructGPT의 RLHF
-
Supervised Fine-Tuning (SFT)
- 인간이 의도하는 policy를 학습시키기 위해 인간 labeler가 선별한 적은 양의 샘플 데이터셋을 통해 PLM을 finetuning
-
Reward Model (Mimic Human Preferences)
- 인간 labeler는 1에서 학습된 SFT 모델이 생성한 여러 답변 후보들 중 인간 labeler들이 무엇이 더 좋은 답변인지 랭킹을 매겨 점수화한 데이터셋을 수집
- 이 데이터셋을 사용해 새로운 reward model을 학습
- 인간 labeler는 1에서 학습된 SFT 모델이 생성한 여러 답변 후보들 중 인간 labeler들이 무엇이 더 좋은 답변인지 랭킹을 매겨 점수화한 데이터셋을 수집
-
Proximal Policy Optimization (PPO)를 이용한 SFT 강화학습
- SFT 모델에 여러 사용자들의 입력을 주고, reward model과 함께 상호작용하며 강화 학습
Supervised Fine-Tuning
- 데모 데이터셋 수집
- 인간 labeler들은 선택된 프롬프트에 대한 GPT의 답변을 기록
- 프롬프트는 (1) Labeler나 개발자가 직접 준비하거나, (2) 사용자들의 OpenAI API로 문의한 프롬프트에 대해 샘플링
- 상당한 비용이 소요되는 프로세스이나, 작지만(약 12k~15k) 매우 고품질의 선별 데이터셋 구축
- PLM finetuning
- GPT-3를 finetuning하는 대신, GPT-3.5를 베이스 모델로 선택함
- 허나 데이터셋 크기가 제한돼있기 때문에 여전히 alignment 오류가 있는 텍스트 출력의 가능성이 있음
- 또한, 인간 labeler를 통해 구축한 데이터셋이기 때문에 확장성 확보에 높은 비용이 소요될 것으로 예상되었음
- 이를 해결하기 위해 제시된 것이 reward model
Reward Model
- RM의 목표는 SFT 모델 출력에 점수를 매긴 데이터셋을 활용해 인간의 선호도를 모방하는 reward model을 학습하는 것
- 모델 구축 프로세스는 다음과 같음
- SFT 모델이 선택된 프롬프트에 대해 4~9개의 여러 출력을 생성하고, 인간 labeler는 SFT가 생성한 출력들에 대해 순위를 매김
- 이렇게 생성된 데이터셋의 크기는 SFT 데이터셋보다 약 10배 크며, 이 데이터셋을 가지고 RM을 학습
- 프롬프트 를 모델 input으로 가정하고, SFT 모델로 2개의 output , 를 생성한다고 가정
- 인간 labeler가 , 에 대한 선호도 점수를 매겨 reward reference를 만들고, reward 모델은 이를 학습하는 것
- Reward 모델은 latent reward 를 Bradley-Terry (BT) 방법에 기반해, 의 reward가 더 높을 확률 를 다음과 같이 계산
- 만약 인간이 에 보다 더 높은 reward를 부여했다면, 가 보다 높길 바라기 때문에, NLLoss를 다음과 같이 정의할 수 있음(선호: / 비선호: )
- 만약 인간이 에 보다 더 높은 reward를 부여했다면, 가 보다 높길 바라기 때문에, NLLoss를 다음과 같이 정의할 수 있음(선호: / 비선호: )
- RM은 인간이 선호하는 텍스트를 학습하며, 인간 labeler가 처음부터 답변을 만드는 것보다 SFT 모델이 생성한 출력에 순위를 매기는 것이 훨씬 쉽고 효율적
Proximal Policy Optimization
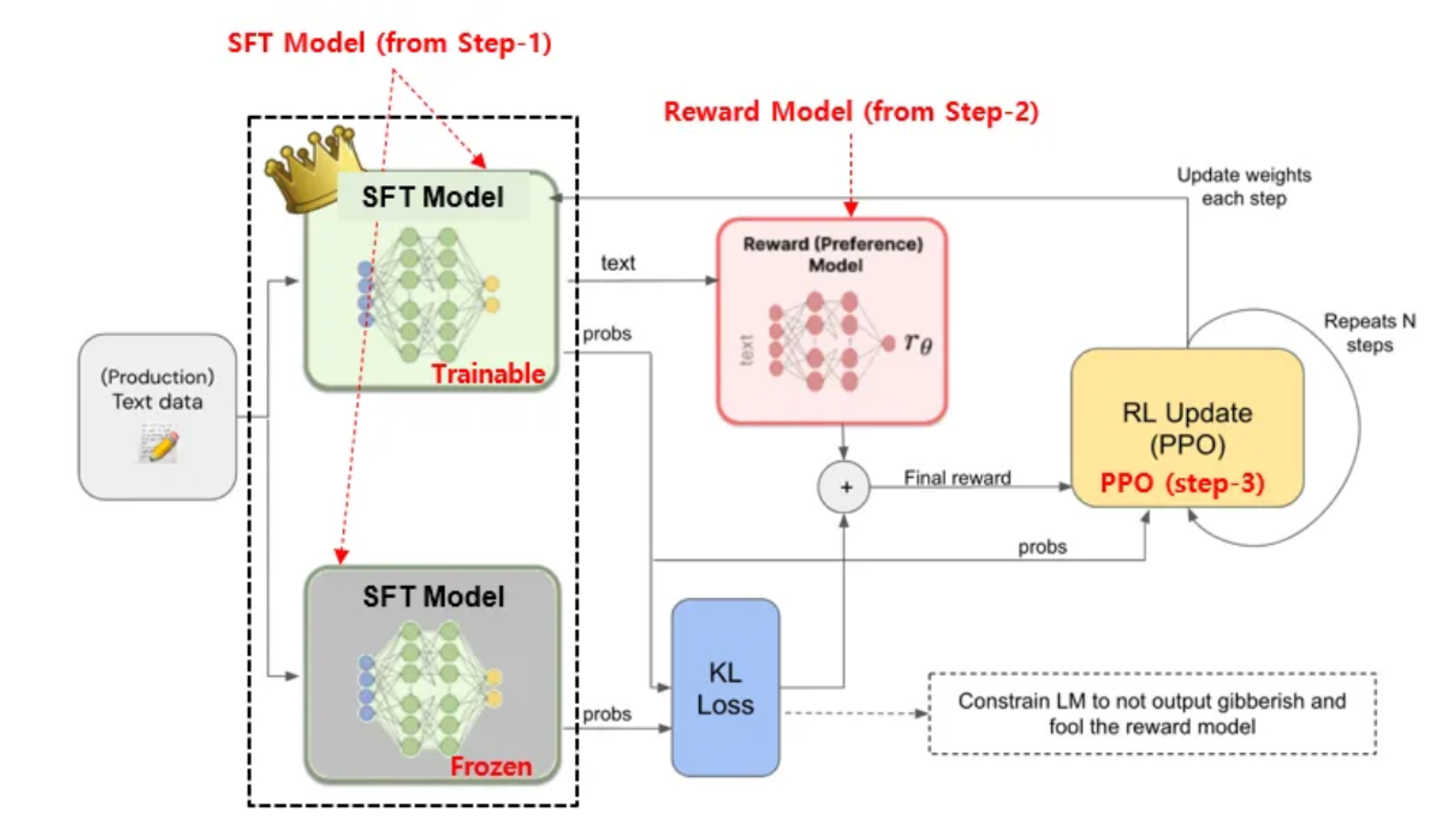
- RM이 제공하는 reward를 이용해 SFT를 finetuning시키는 단계
- SFT 모델의 카피본을 weight-freeze시켜, PPO 알고리즘 내에서 reference 모델로 활용해 RL로 인해 원래 모델의 weight에서 너무 멀어지는 것을 방지함 (+ RM을 tricking하는 상황도 예방)
- KL divergence는 두 확률이 유사할수록 0에 수렴하는 특징이 있고, 이를 학습의 constraint로 이용해 LM이 reward에 너무 빨려들어가지 않게 조절한 것
- PPO 내에서 non-frozen 모델과 frozen 모델 간의 KL divergence를 계산해 RM이 출력한 reward와 더해져 최종적인 reward를 구성함
- 기존에 input이 SFT 출력의 log probability에 대한 디코딩 텍스트였던 RM이었기 때문에 reward loss의 미분이 불가능했는데, 이것이 가능해지면서 PPO를 적용할 수 있게됨
- PPO는 다음과 같은 과정을 통해 loss를 계산해 SFT 모델을 finetuning 시킴
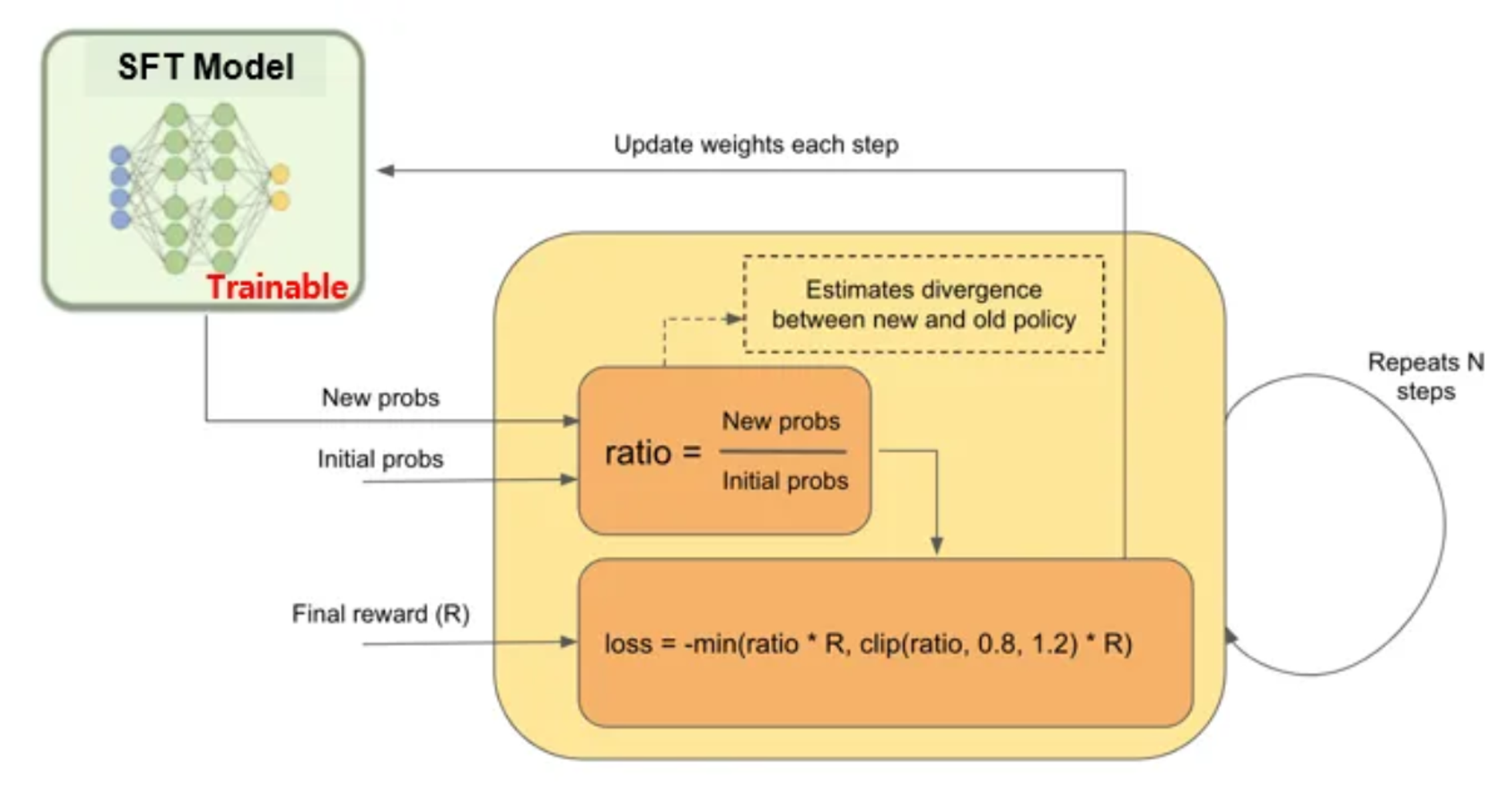
- Initialization을 위해 initial output text probabilities를 new output text probabilities와 동기화
- New probs와 initial probs 간의 ratio를 계산
- loss 계산
- 또는 (과 같은 가중 평균도 가능)
- Backpropagation을 통해 SFT 모델의 가중치 업데이트
- 업데이트 된 SFT 모델을 통해 new probs 계산
RLHF의 한계
데이터셋 확보 비용
- 인간 labeler의 데이터셋을 생성하기 위해서 드는 비용이 엄청남
주관 요인에 따른 품질 편차
- 데모 데이터셋을 생성하는 labeler의 선호도
- 연구와 labeling 프로세스를 설계하는 연구원의 선호도
- 개발자/사용자의 prompt 편차
- SFT와 RM 둘 모두의 학습에 영향을 미치는 labeler의 편향성

J의 틀에 몸을 녹여 맞추는 P