밑바닥부터 시작하는 딥러닝2
1.밑바닥부터 시작하는 딥러닝2 - 2장

자연어 처리가 다루는 분야는 다양하지만, 그 본질적 문제는 컴퓨터가 우리의 말을 알아듣게(이해하게) 만드는 것이다. 이번 장은 컴퓨터에게 말을 이해시킨다는 게 무슨 뜻인지, 그리고 어떤 방법들이 존재하는지를 중심으로 살펴보고자 한다.한국어와 영어 등 우리가 평소에 쓰는
2.밑바닥부터 시작하는 딥러닝2 - 3장
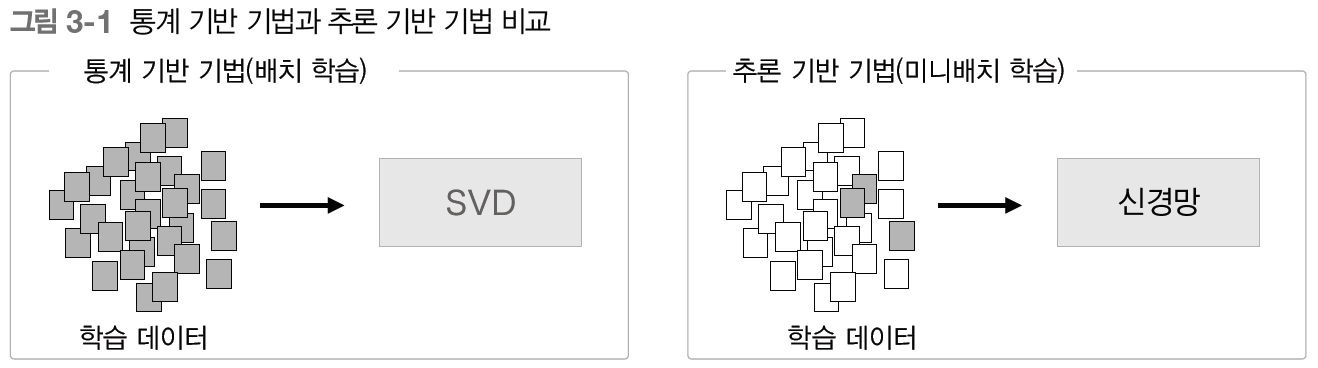
이번 장에서는 통계 기반 기법보다 강력한 '추론 기반 기법'을 살펴본다.단어를 벡터로 표현하는 방법을 크게 두 부류로 나누자면, '통계 기반 기법'과 '추론 기반 기법'이다. 단어의 의미를 얻는 방식은 서로 크게 다르지만, 그 배경에는 모두 분포 가설이 있다.통계 기반
3.밑바닥부터 시작하는 딥러닝2 - 4장
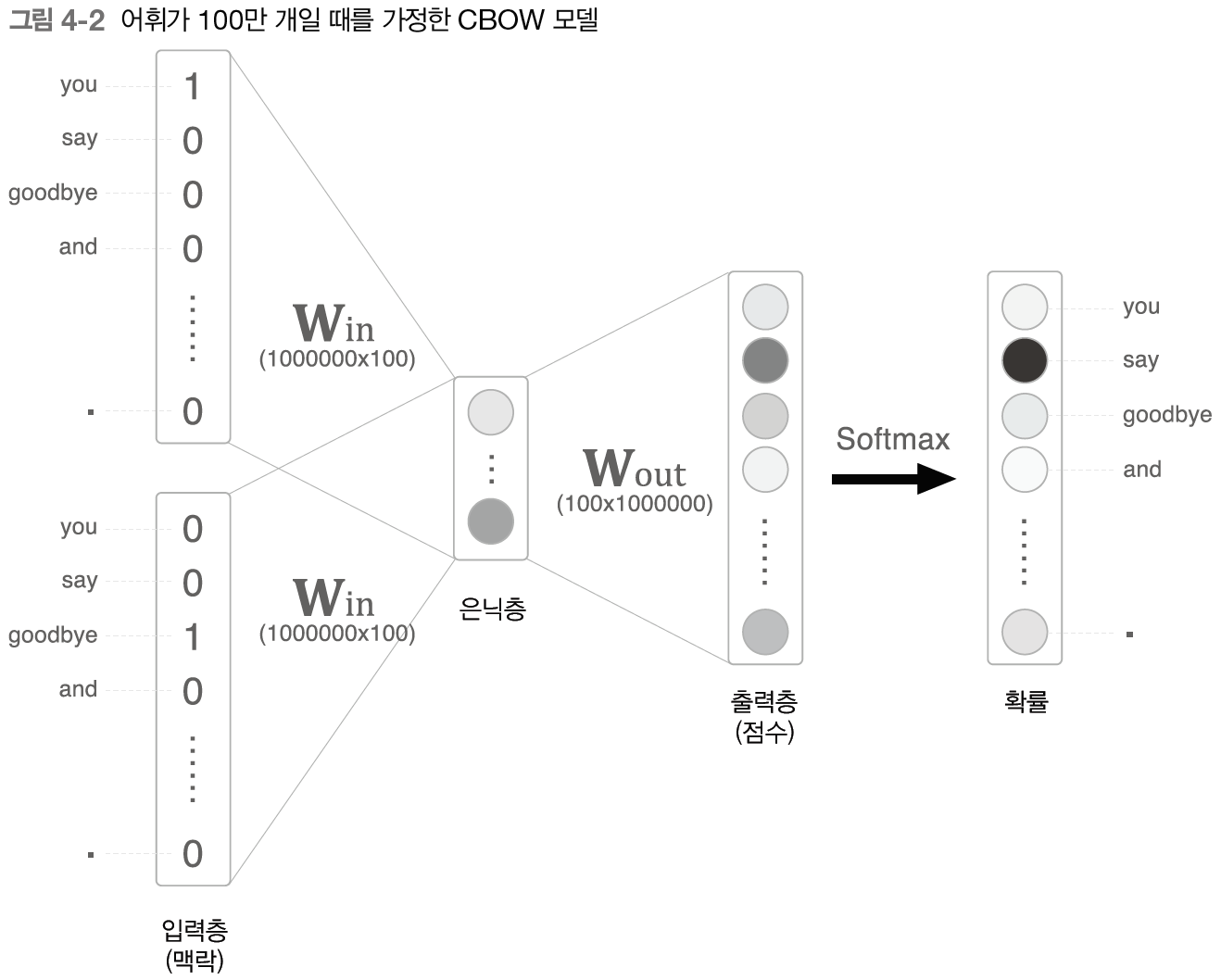
CBOW 모델은 corpus에 포함된 어휘 수가 많아지면 계산량이 커지기 때문에 계산 시간이 오래 걸린다. 이번 장에서는 word2vec의 속도를 개선하기 위해 다음의 두 가지를 살펴본다.Embedding 계층Negative Sampling 손실 함수CBOW 모델로 거
4.밑바닥부터 시작하는 딥러닝2 - 5장
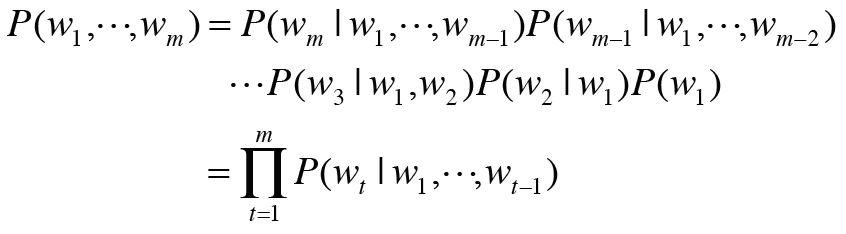
5장 - 순환 신경망(RNN)
5.밑바닥부터 시작하는 딥러닝2 - 6장

앞에서 본 RNN은 과거의 정보를 기억할 수 있었다. 구조가 단순해서 구현도 쉽지만, 안타깝게도 성능이 좋지 못하다. 그 원인은 대부분의 경우 시계열 데이터에서 시간적으로 멀리 떨어진, 장기(long term) 의존 관계를 잘 학습할 수 없다는 데 있다.요즘은 단순한
6.밑바닥부터 시작하는 딥러닝2 - 7장
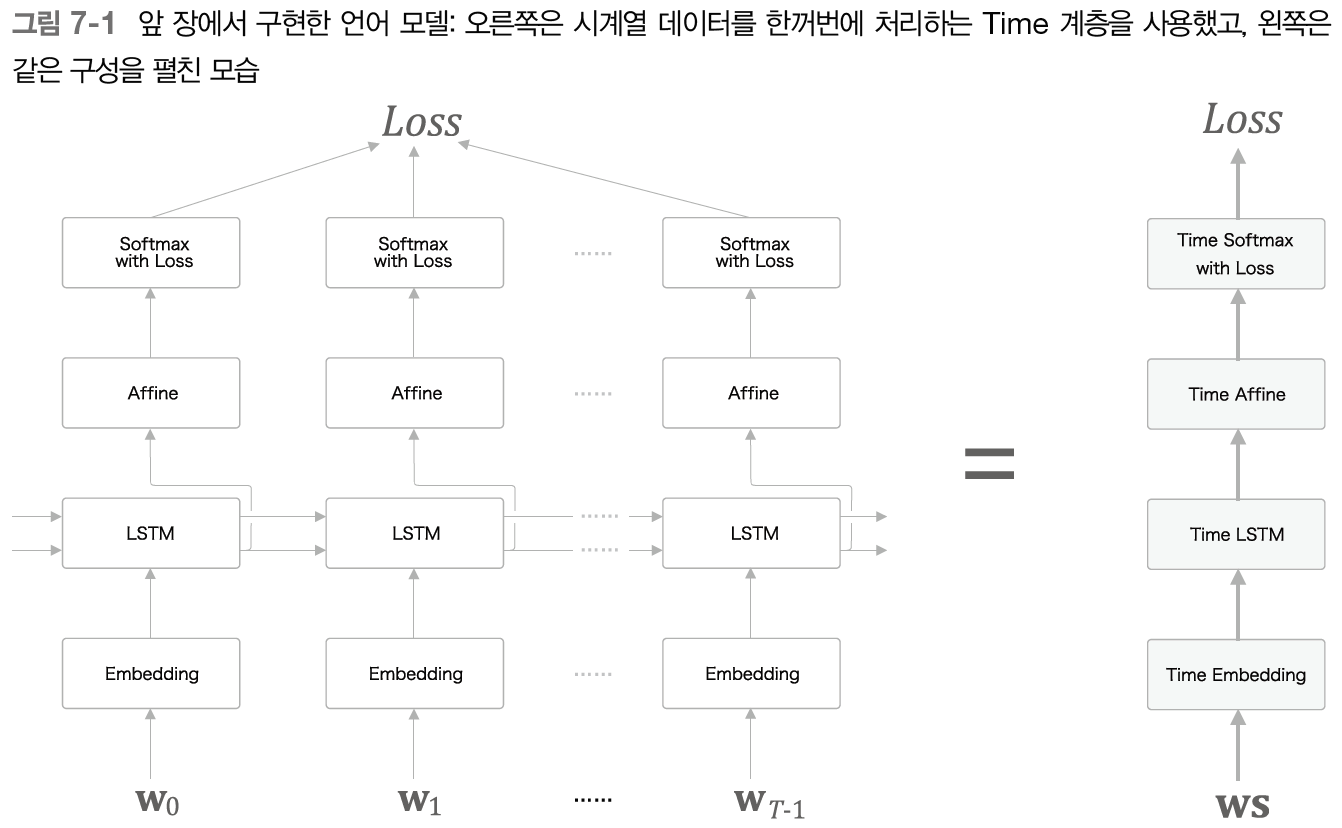
seq2seq란 (from) sequence to sequence(시계열에서 시계열로)를 뜻하는 말로, 한 시계열 데이터를 다른 시계열 데이터로 변환하는 것을 말한다.이번 절에서는 언어 모델로 문장을 생성해보려 한다.앞 장에서는 시계열 데이터를 $T$개분만큼 모아 처리
7.밑바닥부터 시작하는 딥러닝2 - 8장
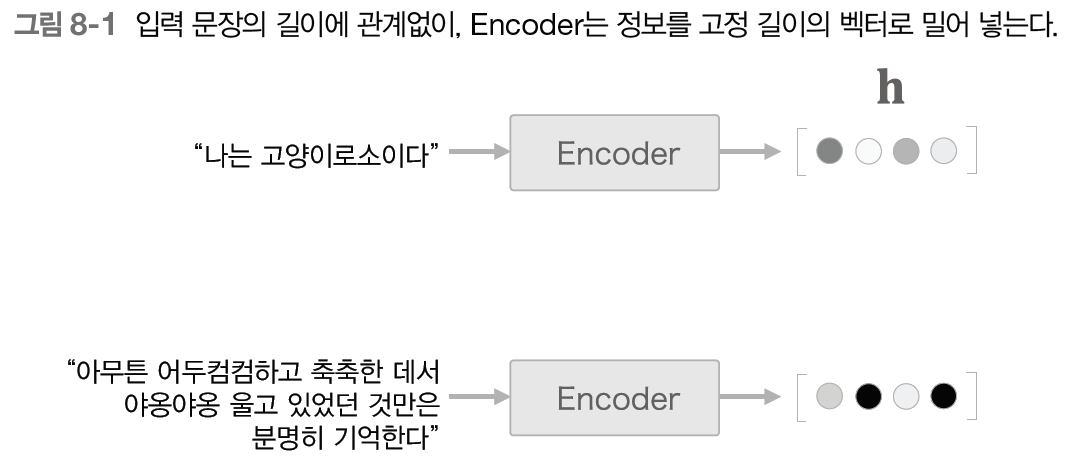
이번 장에서는 seq2seq를 한층 더 강력하게 하는 어텐션 메커니즘이라는 아이디어를 살펴본다.NOTE\_ 앞 장에서 살펴본 seq2seq 개선은 '작은 개선'이었다. 이와 달리, 어텐션 기술은 seq2seq가 안고 있던 근본적인 문제를 해결하는 '큰 개선'이다.seq