5장 - 순환 신경망(RNN)
지금까지 살펴본 신경망은 피드포워드라는 유형의 신경망이다. 피드포워드란 흐름이 단방향인 신경망을 말한다. 입력 신호가 다음 층으로, 또 다음 층으로 흘러가는 식이다.
그러나 단순한 피드포워드 신경망에서는 시계열 데이터의 성질(패턴)을 충분히 학습할 수 없다. 그래서 순환 신경망이 등장하게 된다.
5.1 - 확률과 언어 모델
5.1.1 - word2vec을 확률 관점에서 바라보다
word2vec의 CBOW 모델을 잠깐 복습해 보자. CBOW 모델의 목적은 입력 쪽 가중치 행렬이자 단어의 분산 표현인 을 얻는 것이었다.
그런데 정작 CBOW의 '맥락으로부터 타깃을 추측하는 것'은 어디에 쓸까? 원래 CBOW 모델은 단어 분산 표현을 얻기 위해 고안되었으나 억지로라도 사용해 보자면 바로 '언어 모델'이다.
5.1.2 - 언어 모델
언어 모델은 단어 나열에 확률을 부여한다. 단어의 순서, 즉 문장이 얼마나 자연스러운지를 확률로 평가하는 것이다.
이 언어 모델을 수식으로 설명해 보자. 이라는 개 단어로 된 문장을 생각해 보자. 이때 단어가 이라는 순서로 출현할 확률을 으로 나타낸다. 이 확률은 여러 사건이 동시에 일어날 확률이므로 동시 확률이라고 한다.
이 동시 확률은 조건부 확률을 사용해 다음과 같이 분해하여 쓸 수 있다.
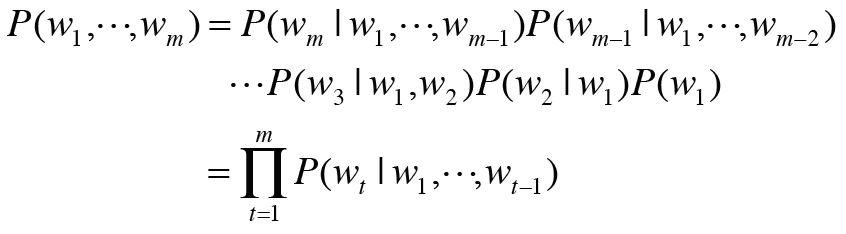
와 는 같은 표현이다. 증명은 다음과 같다.
위의 곱셈정리를 이용한다.
위의 과정을 반복하여 분해해 나가면 된다.
그런데 이 식에서 각각의 확률은 CBOW의 상황으로 치환이 가능하다. 예를 들어 보겠다.
위 확률을 예로 들어보자. 부터 까지 동시에 일어났을 때 가 일어날 확률이다. CBOW에서 생각하면, 부터 까지가 맥락으로 주어졌을 때 타깃이 일 확률이다.

다만 맥락이 모두 왼쪽에 존재한다는 점이 이전과는 달라졌다. 어쨌든 CBOW 모델임에는 다름이 없다.
이렇듯 CBOW의 '맥락으로부터 타깃을 추측하는 것'을 이용하면 언어 모델의 동시 확률을 구할 수 있음을 알 수 있다.
NOTE_ 을 나타내는 모델은 조건부 언어 모델이라고 한다.
5.1.3 - CBOW 모델을 언어 모델로?
word2vec의 CBOW 모델을 억지로 언어 모델에 적용하고자 한다면 맥락의 크기를 특정 값으로 한정하여 근사적으로 나타내면 된다.
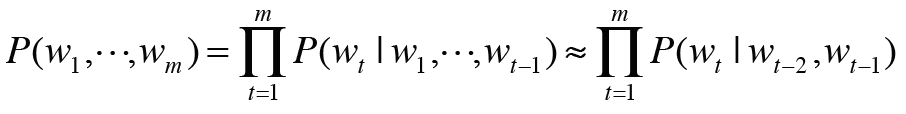
여기서는 맥락을 왼쪽 2개의 단어로 한정한다. 맥락의 크기는 임의로 결정하면 된다. 결정한 후에는 그 길이로 고정되게 된다.
NOTE_ 마르코프 연쇄란 미래의 상태가 현재 상태에만 의존해 결정되는 것을 말한다. 또한 이 사상의 확률이 그 직전 N개의 사건에만 의존할 때 이를 N층 마르코프 연쇄라 한다. 위의 예시는 2층 마르코프 연쇄를 나타낸다.
다만 다음과 같은 상황에서는 맥락의 크기를 고정한다는 점이 문제가 된다.

길이 제한에 걸려 가장 왼쪽의 맥락이 무시된다면 제대로 답할 수 없다.
그럼 맥락의 크기를 무한정 키우면 문제가 해결되지 않을까? 물론 맥락의 크기는 얼마든지 키울 수 있다. 그러나 CBOW 모델에서는 맥락 안의 단어 순서가 무시된다는 한계가 존재한다.
구체적인 예를 보자. 맥락으로 2개의 단어를 다루는 경우, CBOW 모델에서는 이 2개의 단어 벡터의 합이 은닉층으로 온다. 다음 그림의 왼쪽에 해당한다.
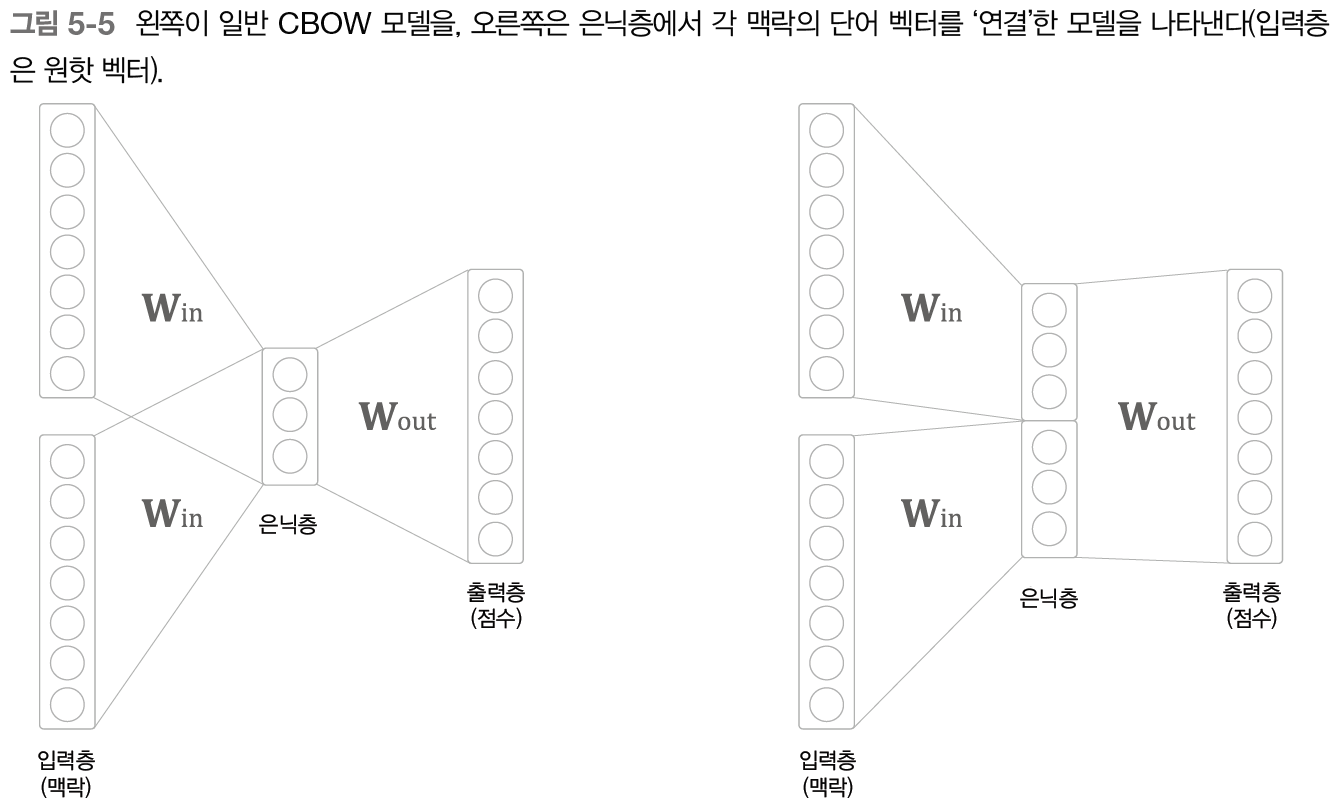
단어 벡터들이 더해지면서 순서가 무시된다. 이상적으로는 오른쪽 모델이 바람직할 것이다. 그러나 연결하는 방식을 취하면 맥락의 크기에 비례해 매개변수가 늘어나게 된다.
그렇다면 이런 긴 맥락이 필요한 경우 등의 문제는 어떻게 해결해야 할까? 여기서 등장하는 게 바로 RNN이다. RNN은 맥락이 아무리 길어도 그 맥락의 정보를 기억하는 메커니즘을 갖추고 있다.
5.2 - RNN이란
5.2.1 - 순환하는 신경망
RNN의 특징은 순환하는 경로(닫힌 경로)가 있단느 것이다. 데이터는 이 순환 경로를 따라 끊임없이 순환하고, 그렇기 때문에 과거의 정보를 기억하는 동시에 최신 데이터로 갱신될 수 있다.
RNN 계층은 다음과 같이 그릴 수 있다.
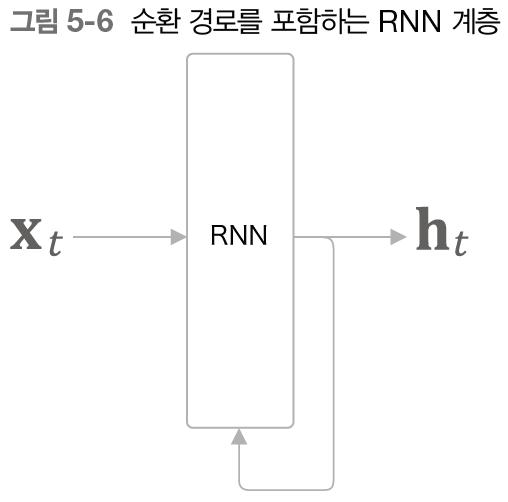
그림에서는 를 입력받는데, 는 시각을 뜻한다. 이는 시계열 데이터가 RNN 계층에 입력됨을 표현한 것이다. 그리고 그 입력에 대응하여 가 출력된다.
또한, 는 벡터라고 가정한다. 문장(단어 순서)를 다루는 경우를 예로 든다면 각 단어의 분산 표현(단어 벡터)이 가 되며, 이 분산 표현이 순서대로 하나씩 RNN계층에 입력되는 것이다.
NOTE_ 위 그림을 보면 출력이 2개로 분기함을 알 수 있다. 여기에서 말하는 '분기'란 같은 것이 복제되어 분기하는 것을 의미한다. 이렇게 분기된 출력 중 하나가 자기 자신에게 입력된다.
이어서 순환 구조를 보기 전에 RNN 계층의 그림을 조금 변경해 보자.
뒤이어 나올 챕터에서 공간을 너무 차지하기 때문에 아래에서 위로 흐르는 그림으로 변경되었다.
5.2.2 - 순환 구조 펼치기
이 순환 구조를 펼치면 친숙한 신경망 형태를 볼 수 있다.
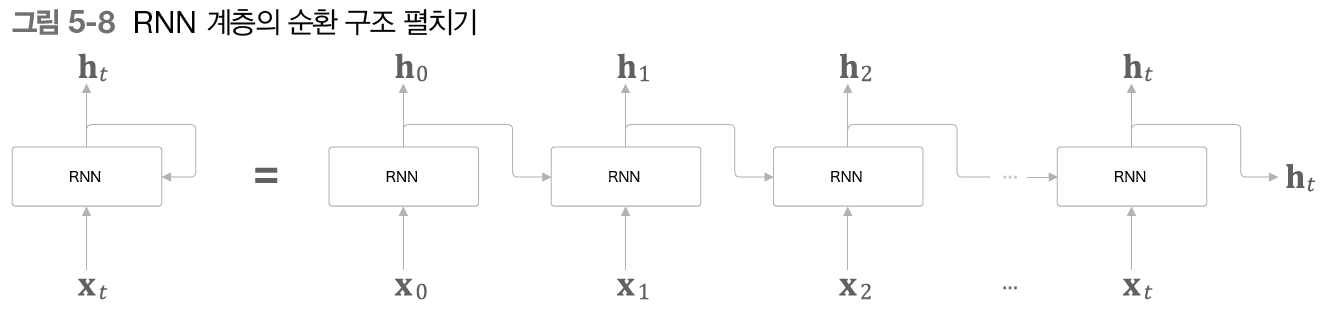
오른쪽으로 긴 신경망처럼 보이게 되었다. 지금까지 본 피드포워드 신경망과 같은 구조처럼 보이지만, 실제로는 저 많은 RNN 계층 모두가 같은 계층임을 잊지 말자.
NOTE_ 시계열 데이터는 시간 방향으로 데이터가 나열된다. 그래서 인덱스를 시각이라고 표현한다. 예를 들면 시각 의 입력 데이터 등.
위 그림에서 볼 수 있듯 각 RNN 계층은 그 계층으로의 입력과 한 단계 전의 RNN 계층으로부터의 출력을 받는다. 이때 수행하는 계산의 수식은 다음과 같다.
두 가지 입력에 각각의 (출력을 계산하기 위한) 가중치를 곱하고 편향을 더해준 후에 tanh함수를 이용해 변환하는 것이다. 참고로 과 는 행벡터이다.
- 는 단어의 분산 표현이라고 이전에 언급했다. 단어 하나하나의 분산 표현이 word2vec에서
의 한 행이었다는 것을 기억하자.
출력은 RNN 계층 밖의 다른 계층을 향해 출력되는 동시에 자기 자신을 향해 오른쪽으로도 출력된다.
그런데, 위 수식을 보면 현 시각의 출력은 한 시각 이전의 출력을 바탕으로 계산하는 것을 알 수 있다.
다른 관점으로 보면, RNN은 라는 '상태'를 가지고 있으며, 위 수식의 형태로 갱신된다고 해석할 수 있다. 그래서 RNN 계층을 '상태를 가지는 계층' 혹은 '메모리(기억력)가 있는 계층'이라고 한다.
NOTE_ RNN의 는 '상태'를 기억해 시각이 1스텝(1단위) 진행될 때마다 위 수식의 형태로 갱신된다.많은 문헌에서 RNN의 출력 을 은닉 상태 혹은 은닉 상태 벡터라고 한다.
5.2.3 - BPTT
앞에서 봤듯 RNN 계층은 가로로 펼친 신경망으로 간주할 수 있다.
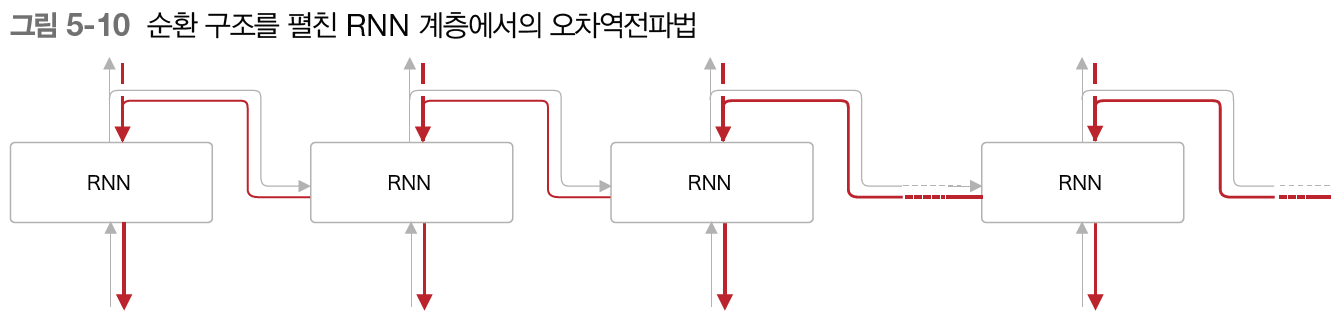
위 그림에서 보듯, 순환 구조를 펼친 후의 RNN에는 일반적인 오차역전파법을 적용할 수 있다. 여기서의 오차역전파법은 '시간 방향으로 펼친 신경망의 오차역전파법'이란 뜻으로 BPTT라고 한다.
BPTT를 사용하면 RNN을 학습할 수 있을 것 같다. 하지만 문제가 있다. 바로 긴 시계열 데이터를 학습할 때의 문제이다. 시계열 데이터의 시간 크기와 BPTT가 소모하는 컴퓨팅 자원이 비례하기 때문이다.
- 시계열 데이터에서는 시간이 곧 인덱스이므로 시간 크기와 데이터 크기는 같은 의미이다.
또한, 시간 크기가 커지면 역전파 시의 기울기가 불안정해지는 것도 문제이다. 신경망을 하나 통과할 때마다 기울기 값이 조금씩 작아지다 소멸할 수도 있다.
5.2.4 - Truncated BPTT
큰 시계열 데이터를 취급할 때는 흔히 신경망 연결을 적당한 길이로 끊는다. 신경망을 적당한 지점에서 잘라 작은 신경망 여러 개로 만들고, 이 작은 신경망에서 오차역전파법을 수행한다. 이게 바로 Truncated BPTT라는 기법이다.
Truncated BPTT가 신경망의 연결을 끊기는 하지만, 제대로 구현하려면 '역전파'의 연결만 끊어야 한다. 순전파의 연결은 반드시 그대로 유지해야 한다.
- 여러 문장을 연결한 것을 하나의 시계열 데이터로 취급할 수도 있다.
그림을 통해 예시를 한번 보자.
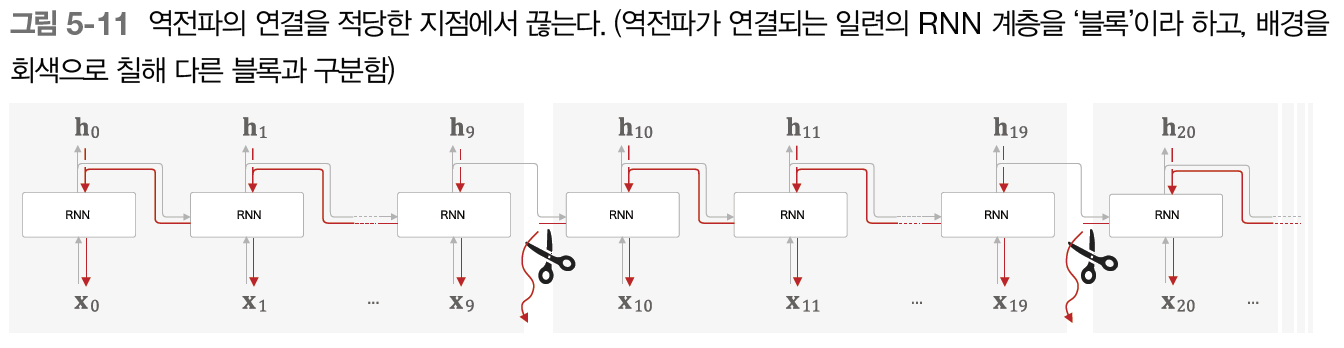
RNN 계층을 10개 단위로 학습할 수 있도록 자른 예시이다. 이처럼 역전파의 연결을 잘라버리면 각각의 블록 단위로, 미래의 블록과는 독립적으로 오차역전파법을 완결시킬 수 있다.
여기서 주의해야 하는 점은 역전파의 연결은 끊겼지만 순전파의 연결은 그대로라는 것이다. RNN을 학습시킬 때는 순전파가 연결된다는 점을 고려해야 한다. 데이터를 '순서대로' 입력해야 한다는 뜻이다.
WARNING_ 지금까지는 미니배치 학습을 수행할 때 데이터를 무작위로 선택해 입력했다. 그러나 RNN에서 Truncated BPTT를 수행할 때는 데이터를 '순서대로' 입력해야 한다.
이제 Truncated BPTT 방식으로 RNN을 학습시켜 보자. 가장 먼저 첫 번째 블록의 입력 데이터를 RNN 계층에 제공한다.
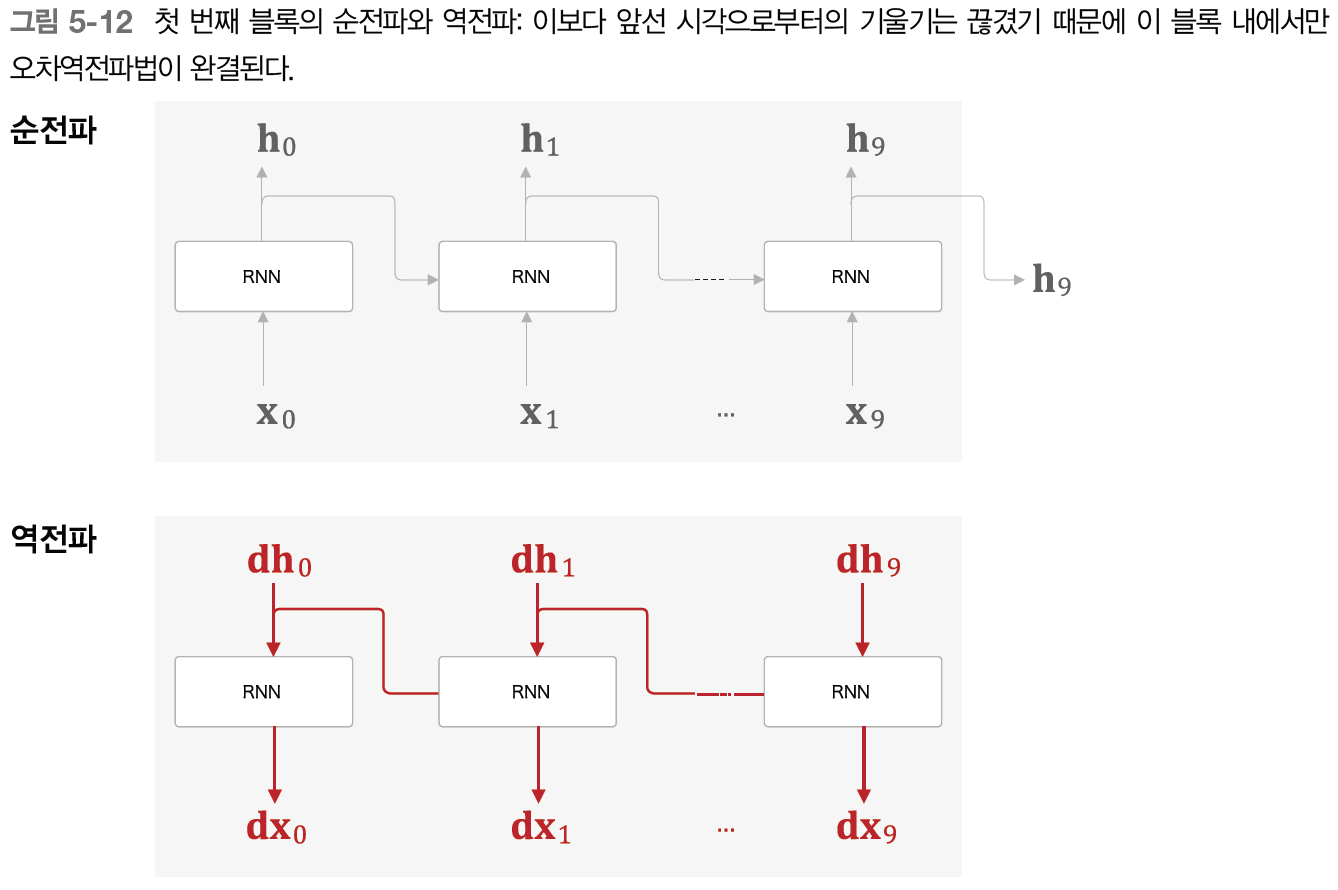
이어서 다음 블록의 입력 데이터에서 를 입력해 오차역전파법을 수행한다.
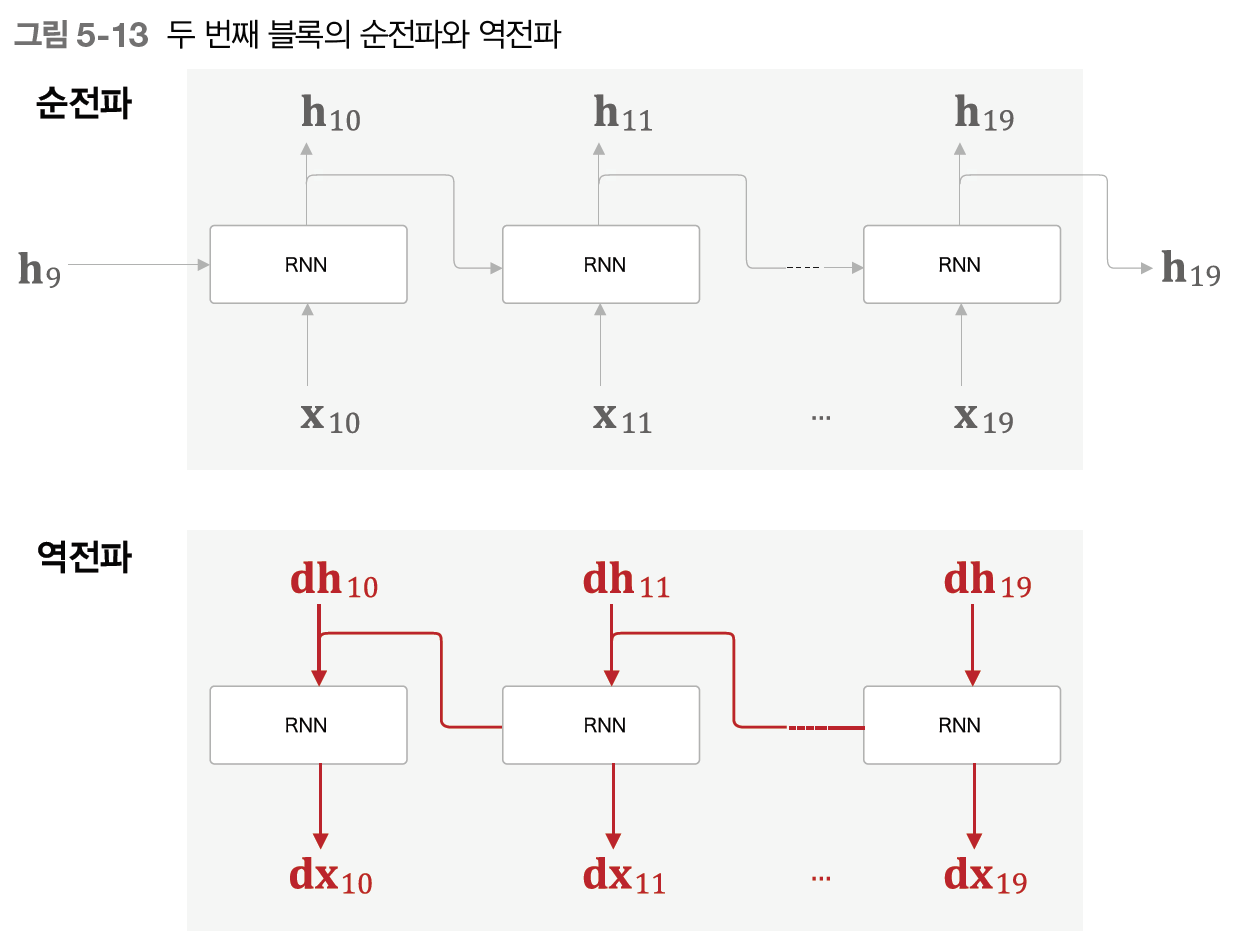
역전파는 각 블록에서 완결되고, 순전파는 앞 블록의 은닉 상태 를 받는 것을 볼 수 있다. 이렇게 순전파는 계속 연결되는 것이다.
이처럼 RNN 학습에서는 데이터를 순서대로 입력하며, 은닉 상태를 계승하면서 학습을 수행한다. RNN 학습의 흐름을 한 번에 보면 다음과 같다.
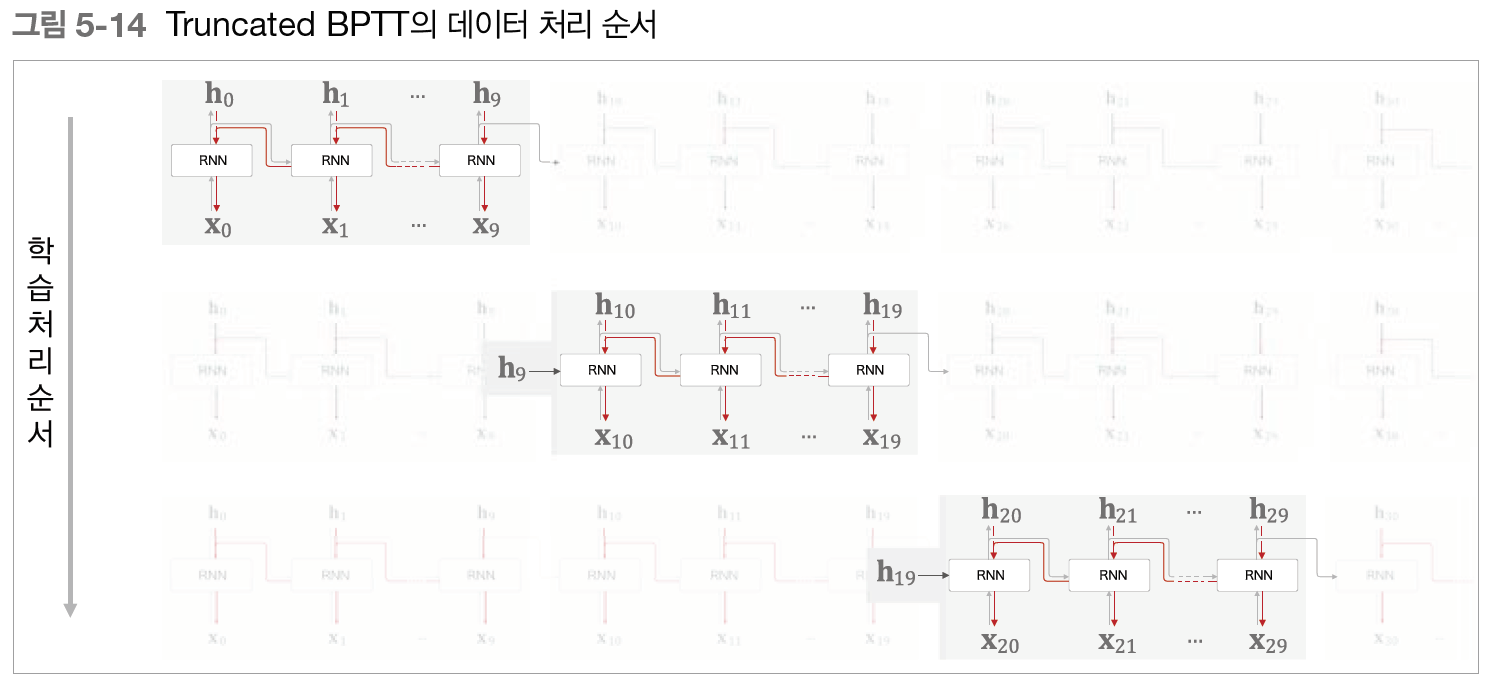
순전파가 계승을 이어가며 순서대로 진행되기 때문에 데이터를 순서대로 입력하는 것이 중요하다.
5.2.5 - Truncated BPTT의 미니배치 학습
지금까지의 이야기는 미니배치 수가 1일 때에 해당한다. RNN에서 미니배치 학습은, 데이터를 입력하는 시작 위치를 각 미니배치의 시작 위치로 '옮겨줘야' 한다.
만약 길이가 1,000인 시계열 데이터에서 시각의 길이를 10개 단위로 잘라 Truncated BPTT로 학습하는 경우를 예로 들어보자.
이때 미니배치 수를 2개로 구성해 학습하려면 어떻게 해야 할까?
이 경우 첫 번째 미니배치는 처음부터 순서대로 데이터를 제공하면 된다.
다만, 두 번째 미니배치 때는 500번째의 데이터를 시작 위치로 정하고, 그 위치부터 순서대로 데이터를 제공하는 것이다. 즉 시작 위치를 500만큼 '옮겨'주는 것이다.
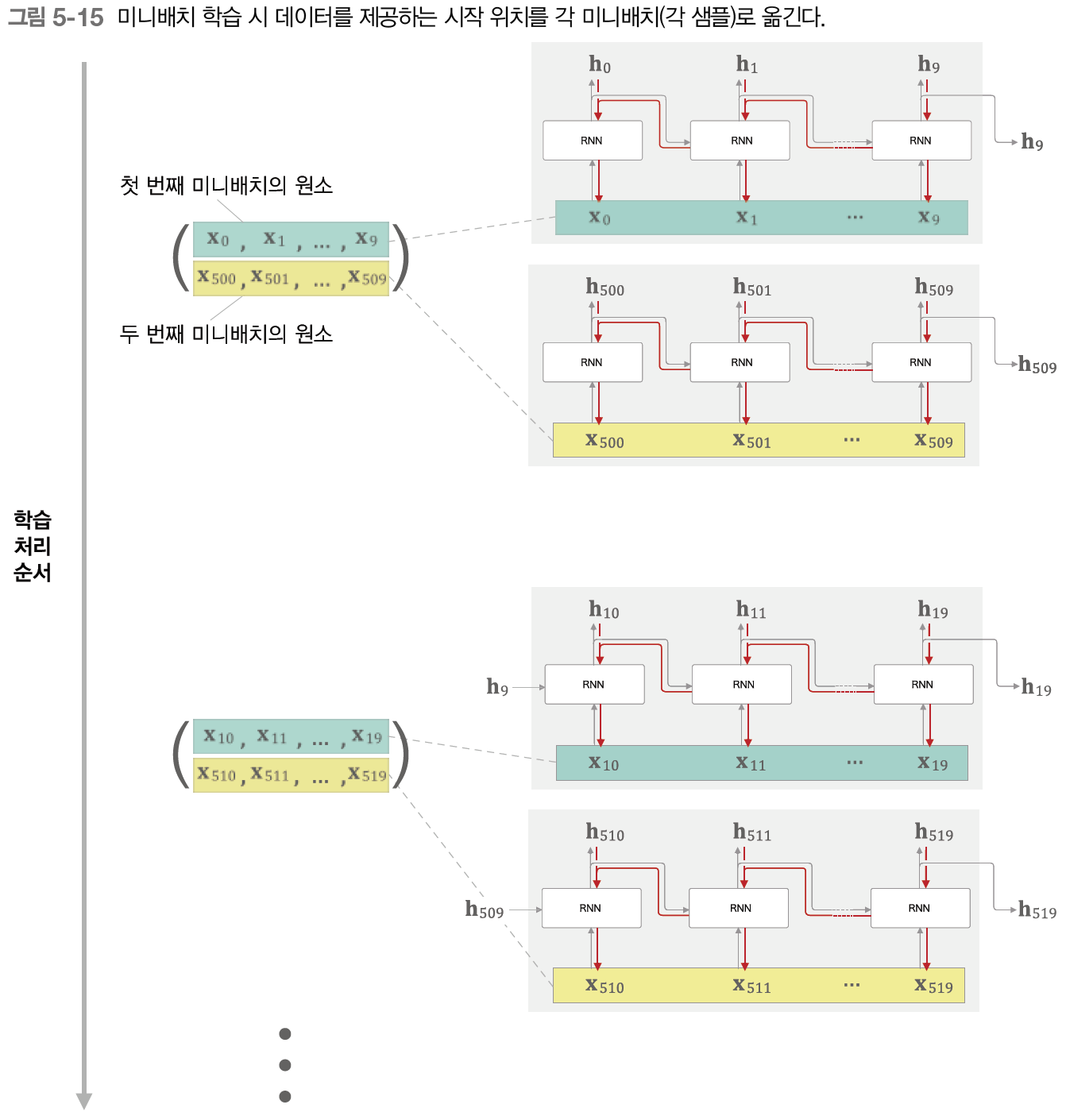
이처럼 미니배치 학습을 수행할 때는 각 미니배치의 시작 위치를 오프셋으로 옮겨준 후 순서대로 제공하면 된다.
또한 데이터를 순서대로 입력하다가 끝에 도달하면 다시 처음부터 입력하도록 한다.
5.3 - RNN 구현
Truncated BPTT 방식의 학습을 따른다면, 가로 크기가 일정한(무한이 아닌) 일련의 신경망을 만들면 된다.
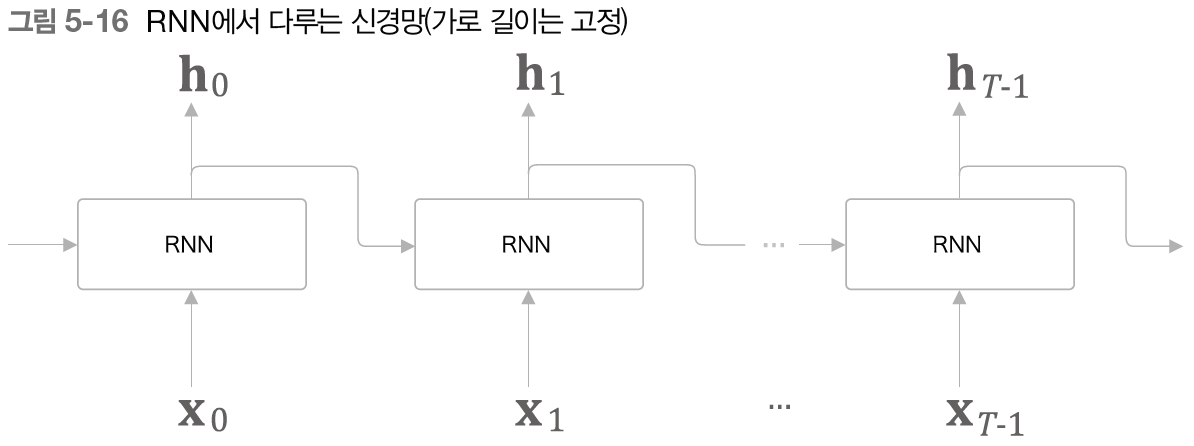
위 그림에서 보듯, 길이가 인 시계열 데이터를 받는다. 여기서 는 임의의 값이다. 그리고 각 시각의 은닉 상태를 개 출력한다.
앞으로 모듈화를 생각하여 이 신경망을 하나의 계층으로 구현하고자 한다. 그림으로 보면 다음과 같다.
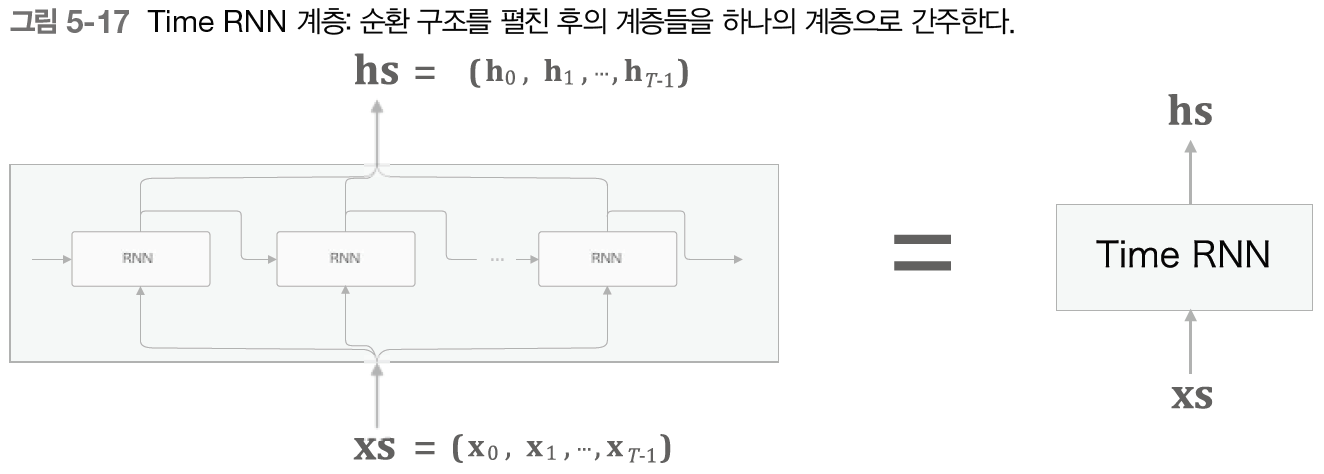
상하 방향의 입력과 출력을 각각 하나로 묶었다. 입력들을 묶은 를 입력하면 출력들을 묶은 가 출력된다.
이때, Time RNN 계층 내에서 한 단계의 작업을 수행하는 계층을 RNN 계층이라 하고, 개 단계분의 작업을 한꺼번에 처리하는 계층을 Time RNN 계층이라 하자.
NOTE_ Time RNN 같이 시계열 데이터를 한꺼번에 처리하는 계층에는 앞에 Time을 붙이자. 이건 이 책에서 사용하는 독자적인 명명규칙이다. 나중에 Time Affine 계층과 Time Embedding 계층도 시계열 데이터를 한꺼번에 처리한다.
5.3.1 - RNN 계층 구현
RNN의 순전파는 다음 수식으로 이루어진다.
다만 이제 미니배치 처리를 생각해야 하므로 행렬의 형상을 고려해야 한다.
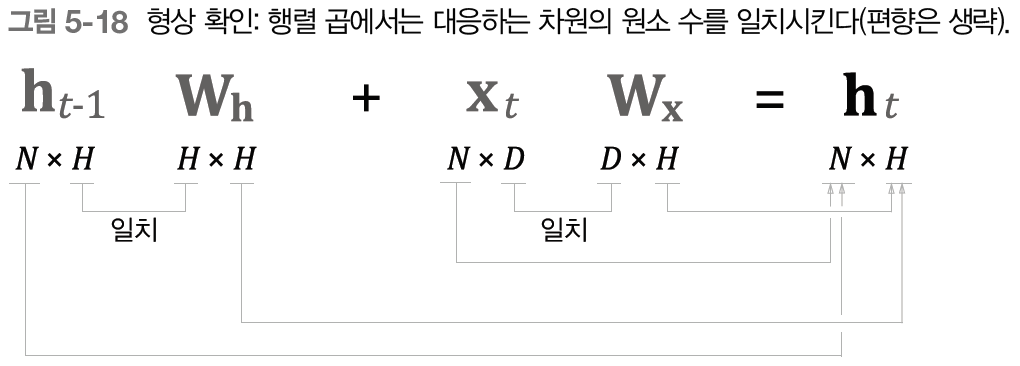
- 미니배치 크기가
- 입력 벡터(단어 벡터)의 차원 수가
- 은닉 상태 벡터의 차원 수가
은닉 상태 벡터인 과 는 미니배치의 크기만큼 존재하므로 의 형상이 된다.
그리고 는 이전 단계의 출력을 바탕으로 출력을 계산하기 위한 가중치이다. 즉, 의 형상에 행렬곱을 하여 의 형상이 나와야 한다. 그렇기 때문에 의 형상은 가 된다.
도 현재 시각에 입력된 단어 벡터와 행렬곱을 하여 출력을 계산해야 한다. 단어 벡터의 형상도 미니배치의 크기만큼 존재하므로 가 되고, 자연스럽게 의 형상은 가 된다.
이를 계산 그래프로 나타내면 다음과 같다.
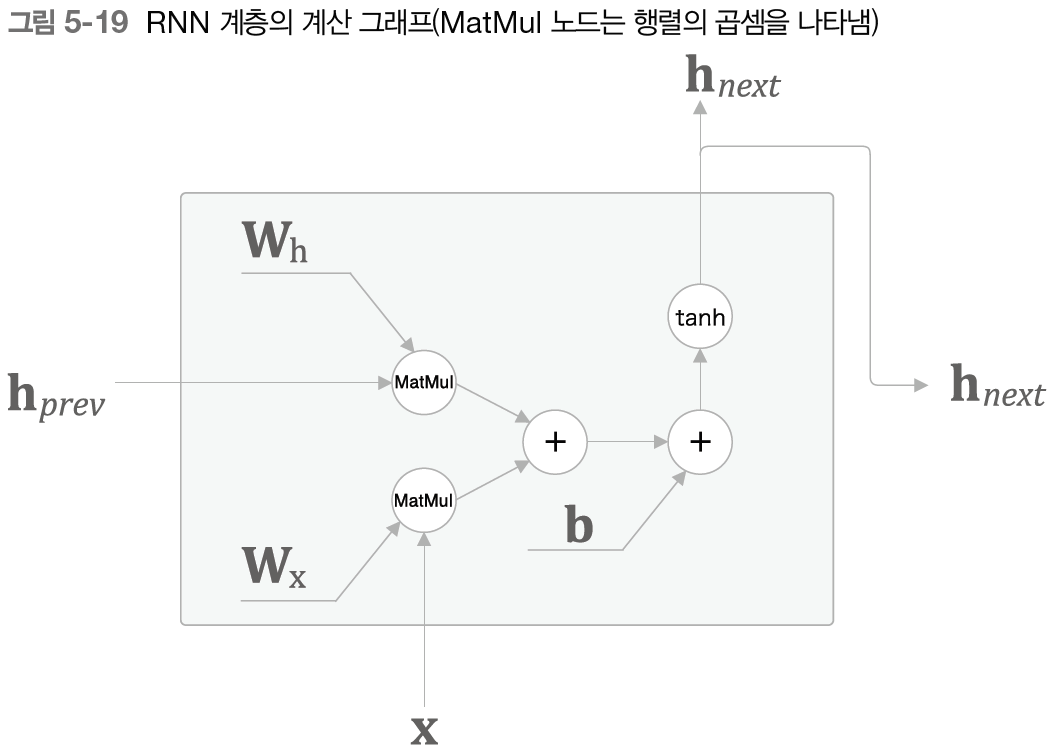
이전 시각의 은닉 상태 벡터에 그에 맞는 가중치가 곱해지고, 현재 시각의 입력인 단어 벡터에 그에 맞는 가중치가 곱해진다. 그 후 둘과 편향까지 더해준 값에 로 변환을 해주어 새로운 은닉 상태 벡터를 출력한다.
여기서 참고로 편향 를 더할 때는 브로드캐스트가 일어나므로 주의해야 한다.
역전파는 지금까지 배운 로직으로 구현이 가능하므로 넘어간다.
5.4 - 시계열 데이터 처리 계층 구현
RNN을 사용한 언어 모델은 RNN Language Model이므로 RNNLM이라 칭한다.
5.4.1 - RNNLM의 전체 그림
다음 그림은 RNNLM의 가장 단순한 신경망을 그려본 것이다.
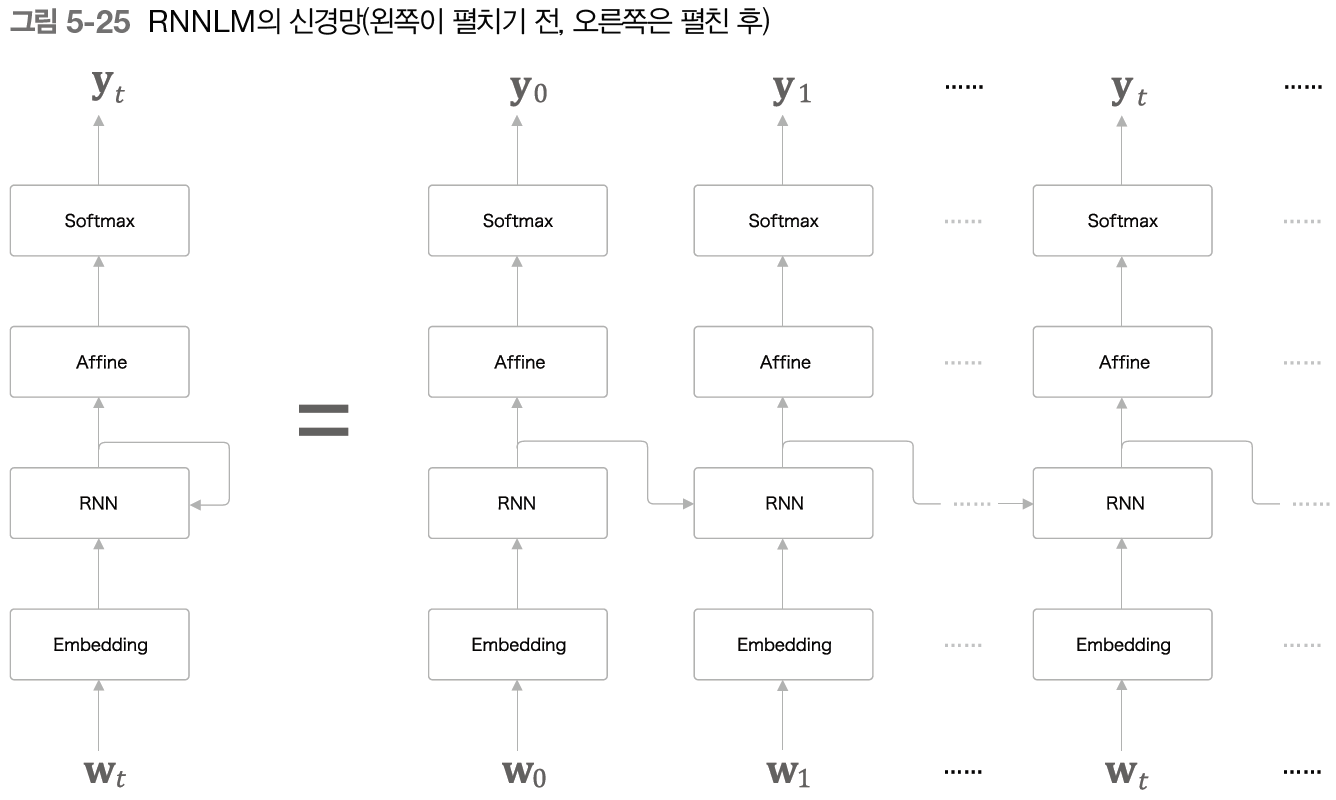
첫 번째 계층은 Embedding 계층으로, word2vec 개선에서 나온 것과는 다른 의미이다. 이 계층은 단어 ID를 단어 벡터로 변환하는 역할을 한다.

입력 데이터는 단어 ID이다.
여기서 주목할 것은 RNN 계층이 "you say"라는 맥락을 '기억'하고 있다는 사실이다. 더 정확하게 말하면, RNN은 "you say"라는 과거의 정보를 응집된 은닉 상태 벡터로 저장해두고 있다.
5.4.2 - Time 계층 구현
시계열 데이터를 한꺼번에 처리하는 계층을 Time을 붙여 구현하고자 한다.
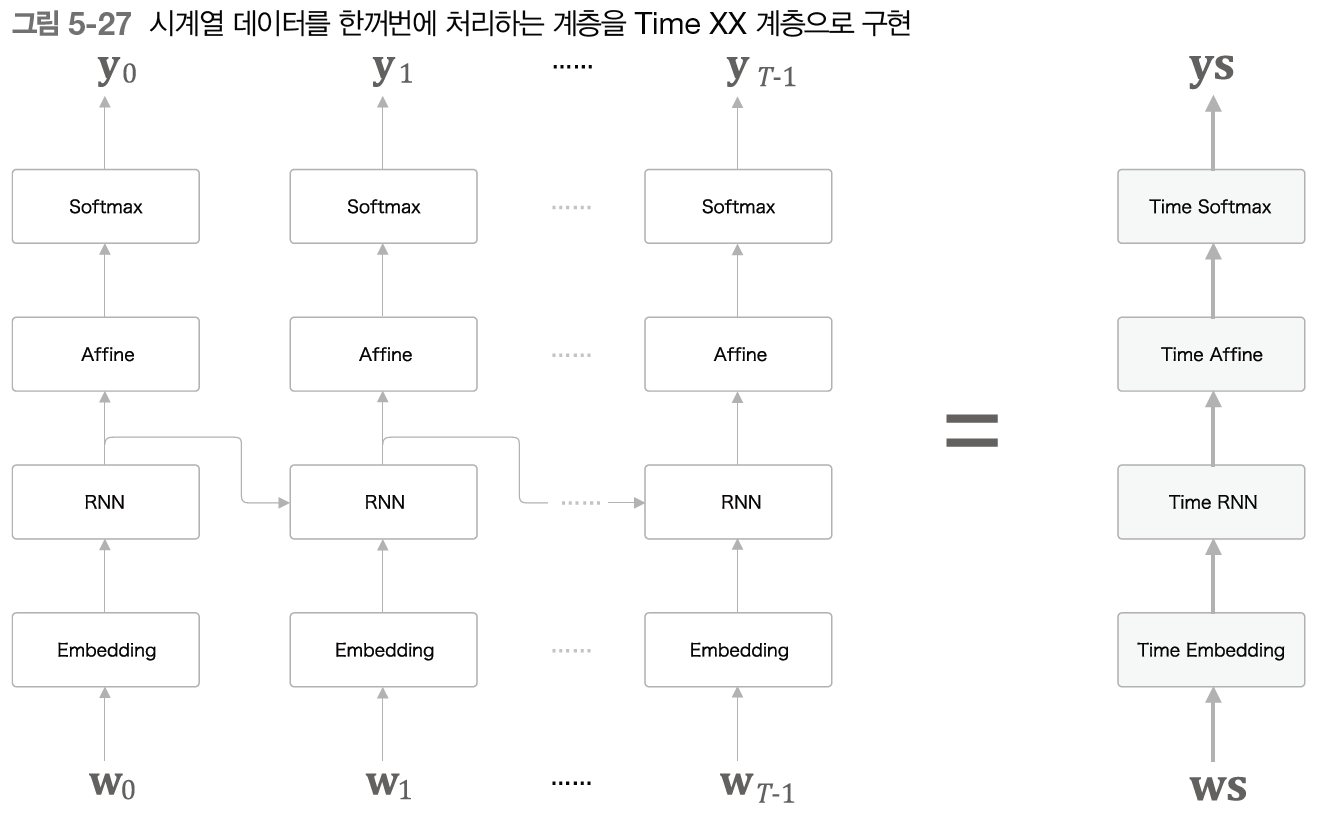
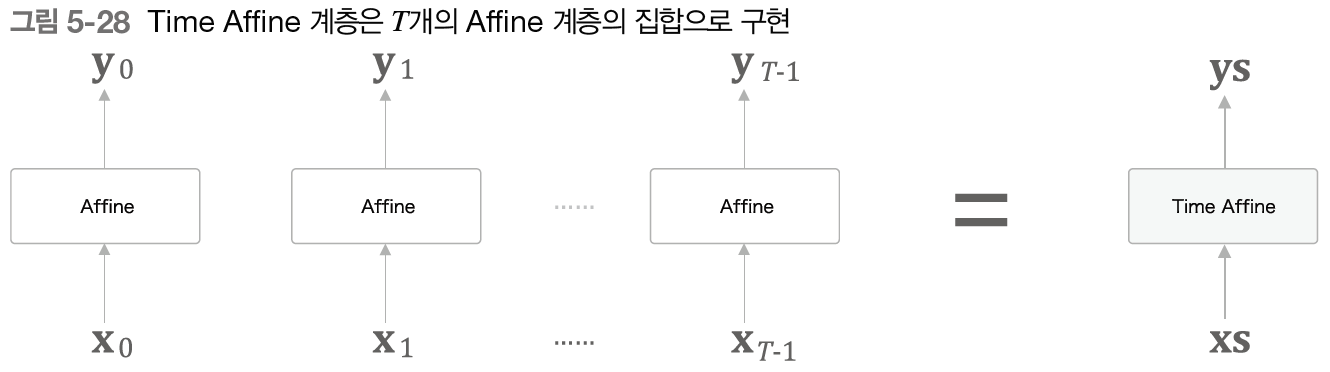
우선은 Affine 계층이다. 특별할 것이 없으므로 빠르게 넘어가자.
Embedding 계층도 특별할 것이 없으므로 넘어가겠다. 다음으로 Softmax with Loss 계층이다.
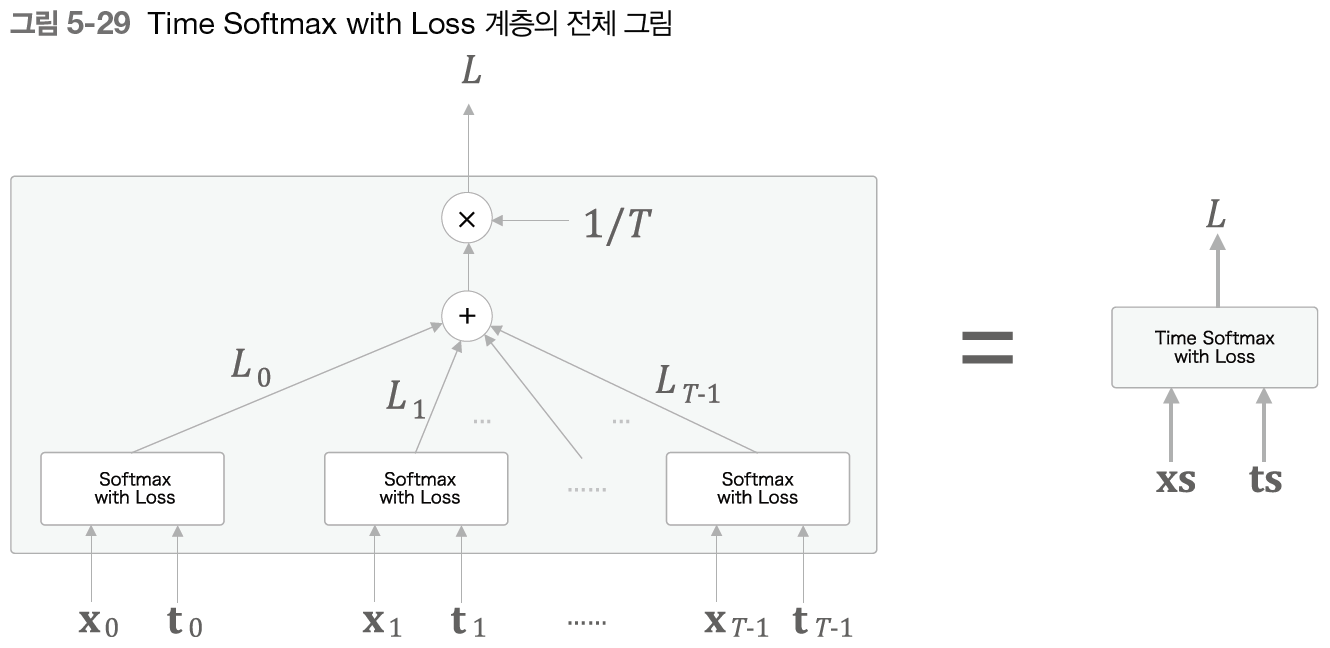
Cross Entropy Error 계층이 포함된 형태이기 때문에 입력이 두 종류인 것을 볼 수 있다.
손실들을 합산해 평균한 값이 최종 손실이 된다.
5.5 - RNNLM 학습과 평가
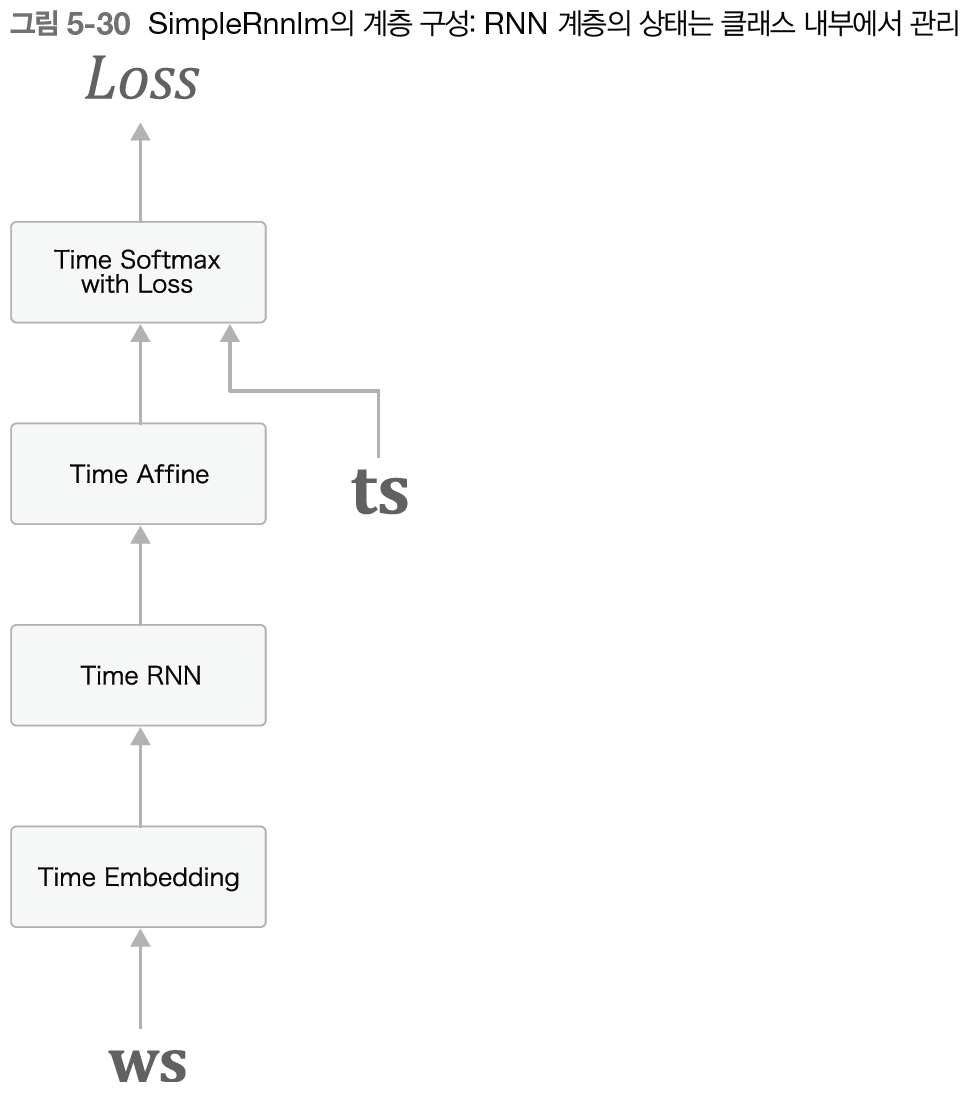
5.5.1 - RNNLM 구현
RNNLM의 계층 구성은 다음과 같다.
5.5.2 - 언어 모델의 평가(퍼플렉서티)
언어 모델의 예측 성능을 평가하는 척도로 퍼플렉서티(혼란도)를 자주 이용한다.
퍼플렉서티는 간단히 말하면 확률의 역수이다. 예를 들어 확률이 0.8이면 퍼플렉서티는 가 된다. 확률이 작을수록 퍼플렉서티(혼란도)가 커지는 식이다.
다만, 이게 단어별로 비교하는 게 아니라 같은 단어를 모델별로 비교하는 것이다.

모델 1은 퍼플렉서티가 작아서 잘 예측했다고 볼 수 있고, 모델 2는 퍼플렉서티가 크기 때문에 잘 예측하지 못했다고 할 수 있다.
퍼플렉서티를 직관적으로 해석하면 분기수로 해석할 수 있다. 분기수란 다음에 취할 수 있는 선택지의 수를 말한다. 여기서는 다음에 출현할 수 있는 단어의 후보 수가 되겠다.
좋은 모델이 예측한 분기수가 1.25라는 뜻은, 다음에 출현할 수 있는 단어의 후보를 1개 정도로 좁혔다는 뜻이 된다.
입력 데이터가 여러 개일 때 퍼플렉서티는 어떻게 될까? 그럴 때는 다음 공식에 따라 계산한다.
은 신경망의 손실을 뜻하며, 사실 교차 엔트로피 오차를 뜻하는 식과 완전히 같은 식이다.
은 입력 데이터의 개수이다. 은 입력 데이터의 인덱스이고, 는 하나의 입력 데이터(벡터) 안의 인덱스이다. 는 정답 레이블이고, 는 확률분포(신경망에서는 Softmax의 출력)를 나타낸다.
