Spark
1.Apache Spark란?

Apache Spark Spark란 Single-node 또는 Cluster 위에서 Data Engineering, Data Science, Machine Learning을 수행할 수 있도록 도와주는 빅데이터 처리 및 분석을 위한 In-memory 기반의 통합 컴퓨
2.Spark 설치 및 실행하기 - Local Mode
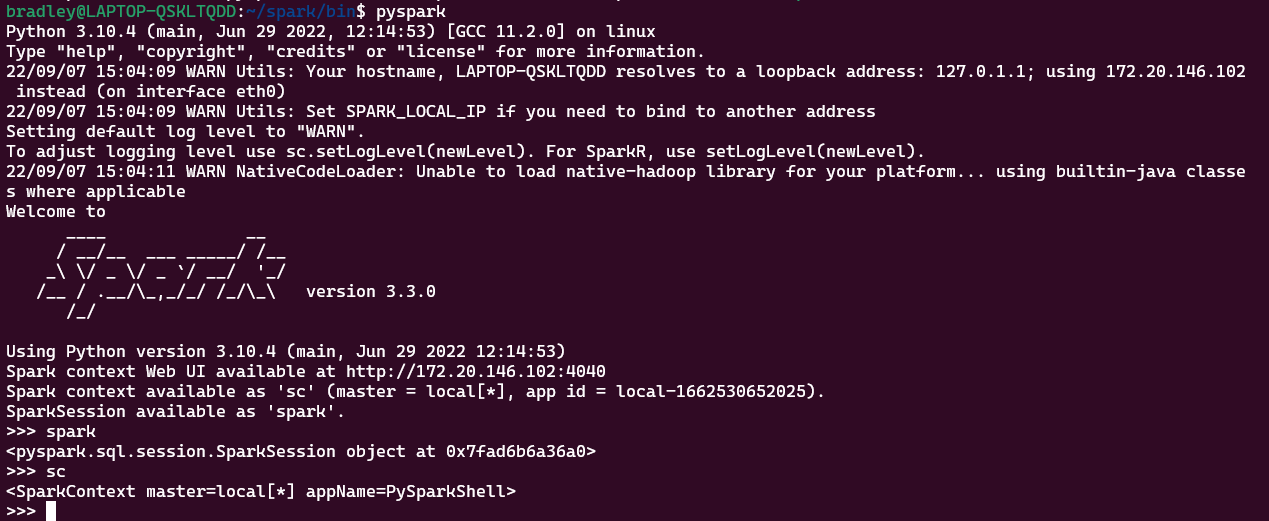
Java 설치하기 sudo apt install default-jdk java -version Spark 설치하기 wget https://dlcdn.apache.org/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz tar -xv
3.Spark 배포 및 실행 방법에 대한 이해
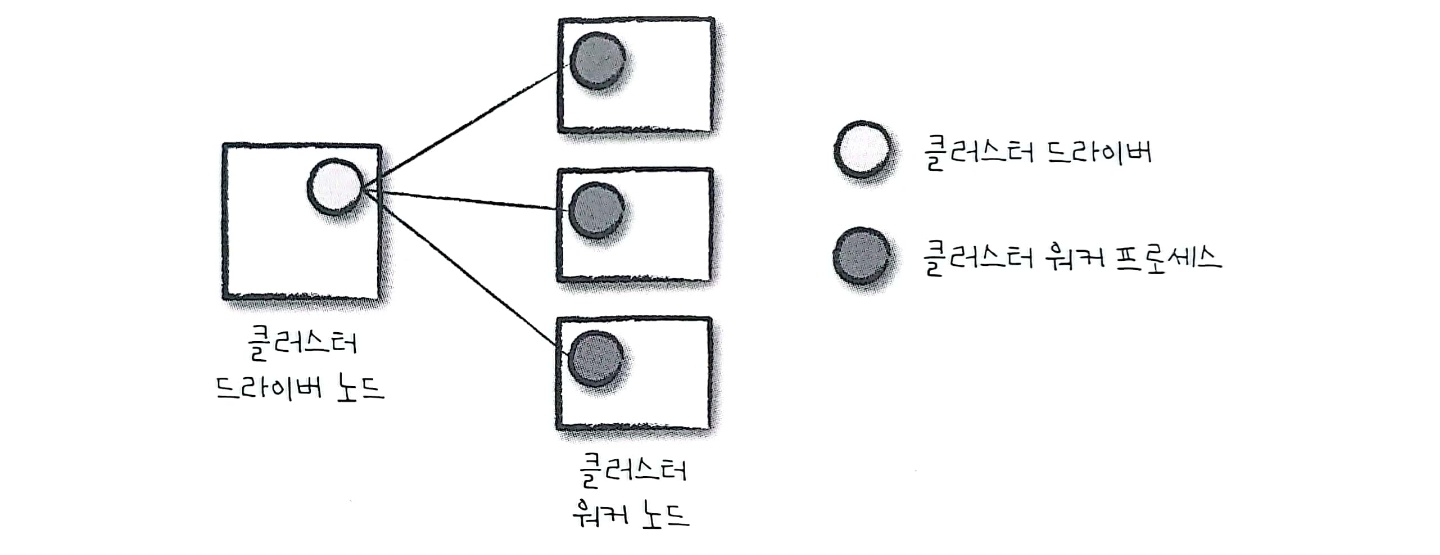
우선 Spark를 논외로 하고, Cluster Manager를 살펴보자.실행 중인 Spark Application이 없는 Cluster Driver와 Worker위 구조는 Cluster Manager의 구조를 보여준다. 이 Cluster Manager는 Spark Ap
4.간단한 Spark Application 만들어 보기

아래 포스팅에서 spark-submit 명령을 통해 Spark Application을 제출하고 실행한다는 것을 알았다.Spark 배포 및 실행 방법에 대한 이해https://velog.io/@jskim/Spark-%EB%B0%B0%ED%8F%AC-%EB%B0%
5.Spark 실행하기 - Spark Standalone Cluster Manager

아래 포스팅을 참조해 Spark를 설치한다.Spark 설치 및 실행하기 - Local Modehttps://velog.io/@jskim/Spark-%EC%84%A4%EC%B9%98-%EB%B0%8F-%EC%8B%A4%ED%96%89%ED%95%98%EA%B8%
6.Zeppelin - Spark 연동하기
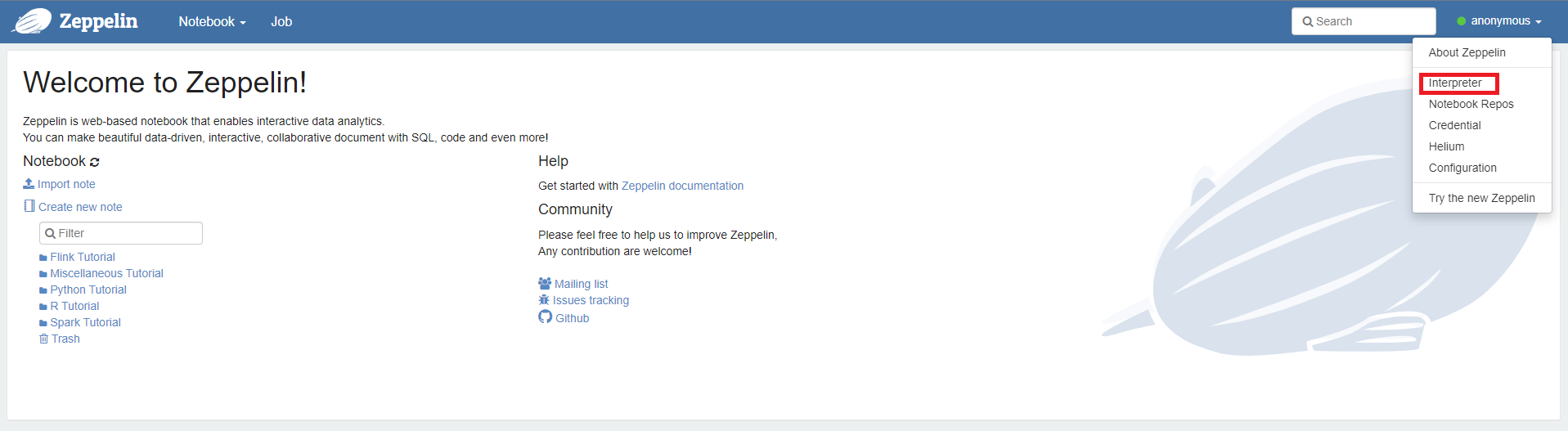
우측 상단의 anonymous 옆 드롭다운을 눌러 Interpreter로 이동한다.spark를 검색하면 Spark Interpreter 설정을 할 수 있다.spark.master가 현재 Local Mode로 되어 있는데 이 값을 변경하여 Cluster Manager를
7.Spark로 TLC Taxi Record 데이터 분석하기
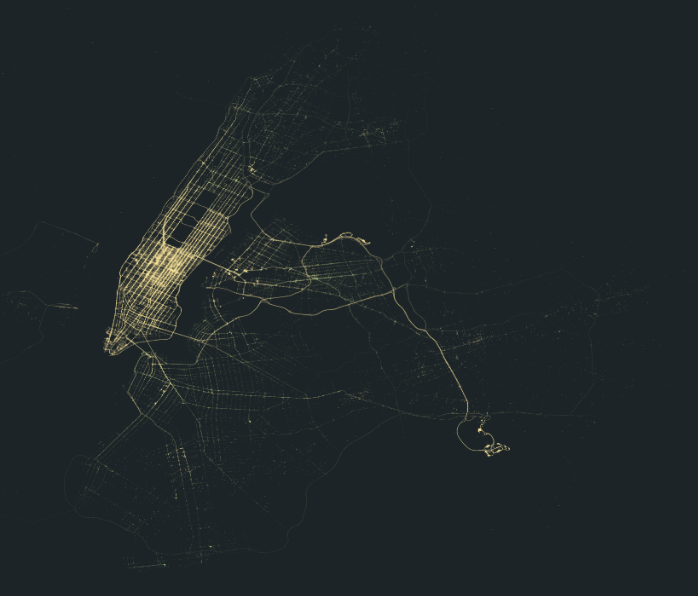
데이터셋 소개 TLC(The New York City Taxi and Limousine Commission)는 New York City's medallion (Yellow) Taxis, Street hail livery (Green) Taxis, FHVs(For-Hi