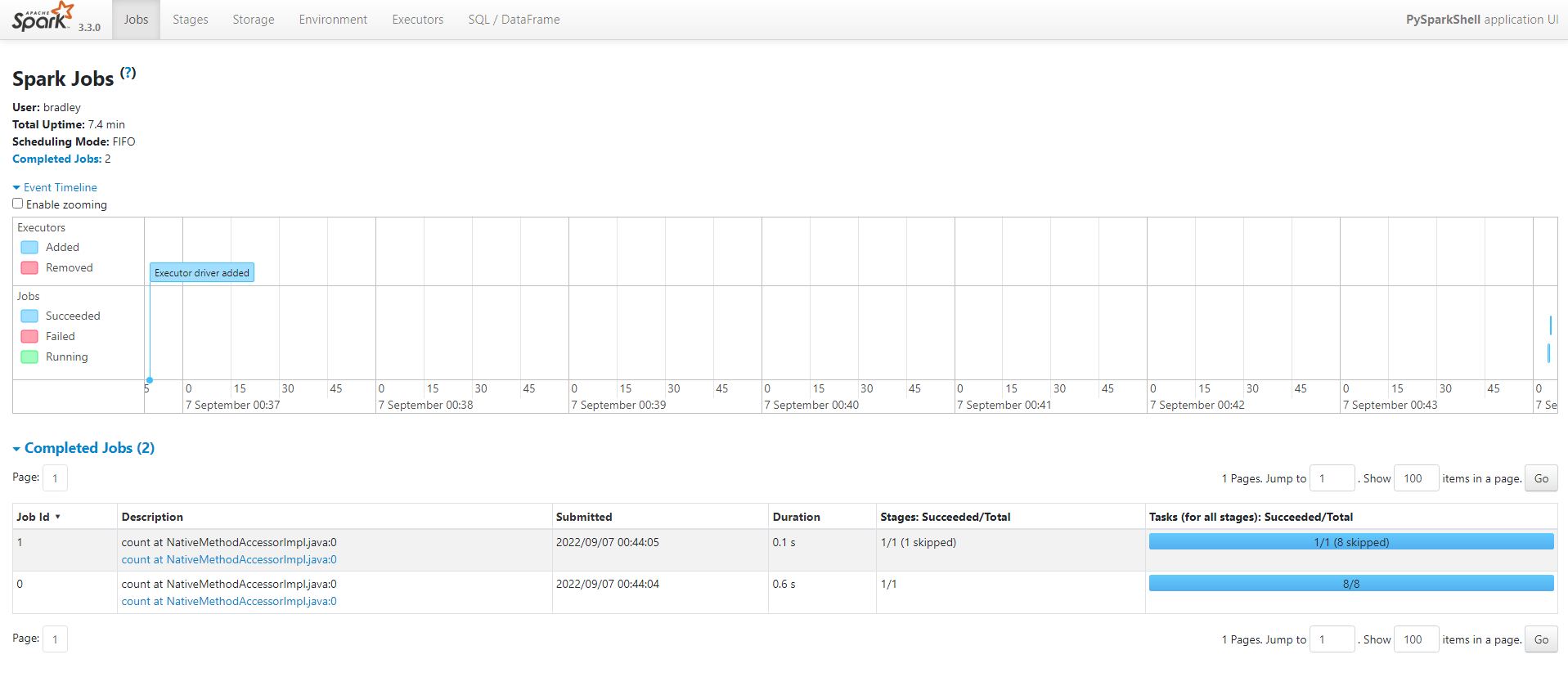
Java 설치하기
sudo apt install default-jdk
java -version
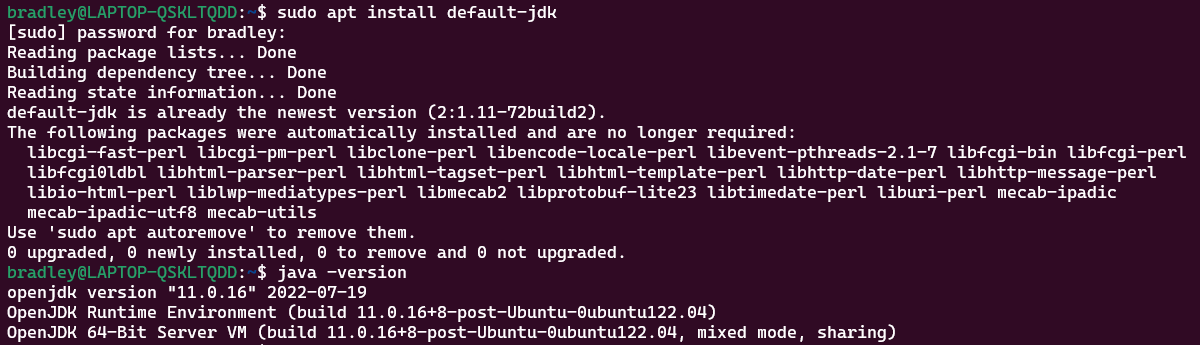
Spark 설치하기
wget https://dlcdn.apache.org/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz
tar -xvf spark-3.3.0-bin-hadoop3.tgz
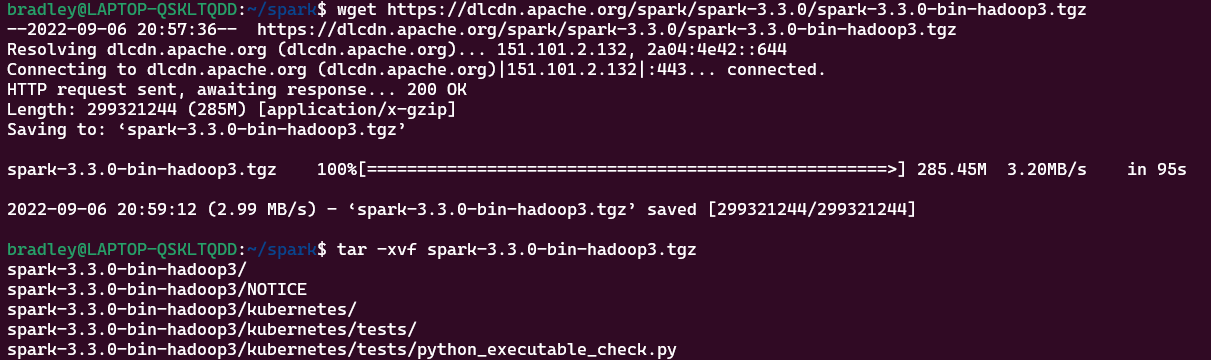
mv spark-3.3.0-bin-hadoop3.tgz spark
환경변수 등록
1) vim ~/.bashrc
2) ./bashrc에 아래 환경변수 추가
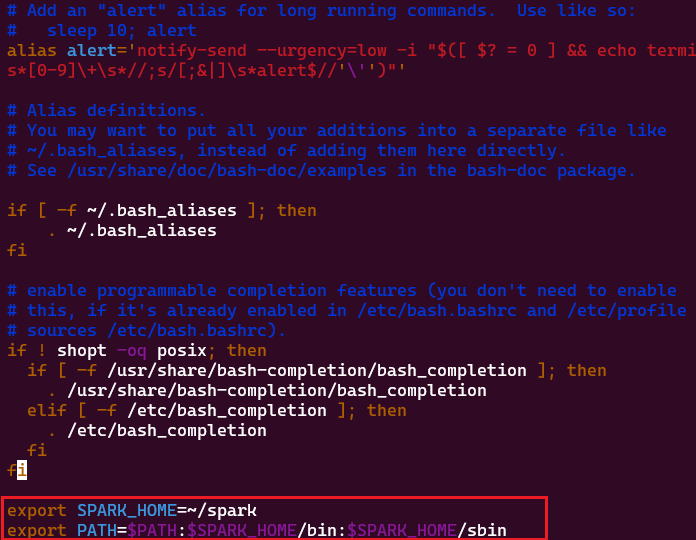
export SPARK_HOME=~/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
3) source ~/.bashrc
Local 모드로 실행하기
간단하게 Spark를 실행해보기 위해 Local Mode로 Spark를 실행한다.
Spark 실행 모드(배포 모드)
Spark는 3가지 실행 모드를 가진다.
- Cluster Mode
- Client Mode
- Local Mode
Spark 배포 및 실행 방법에 대한 이해
https://velog.io/@jskim/Spark-%EB%B0%B0%ED%8F%AC-%EB%B0%8F-%EC%8B%A4%ED%96%89-%EB%B0%A9%EB%B2%95%EC%97%90-%EB%8C%80%ED%95%9C-%EC%9D%B4%ED%95%B4
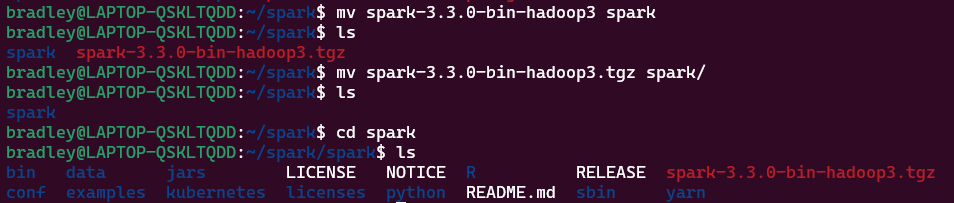
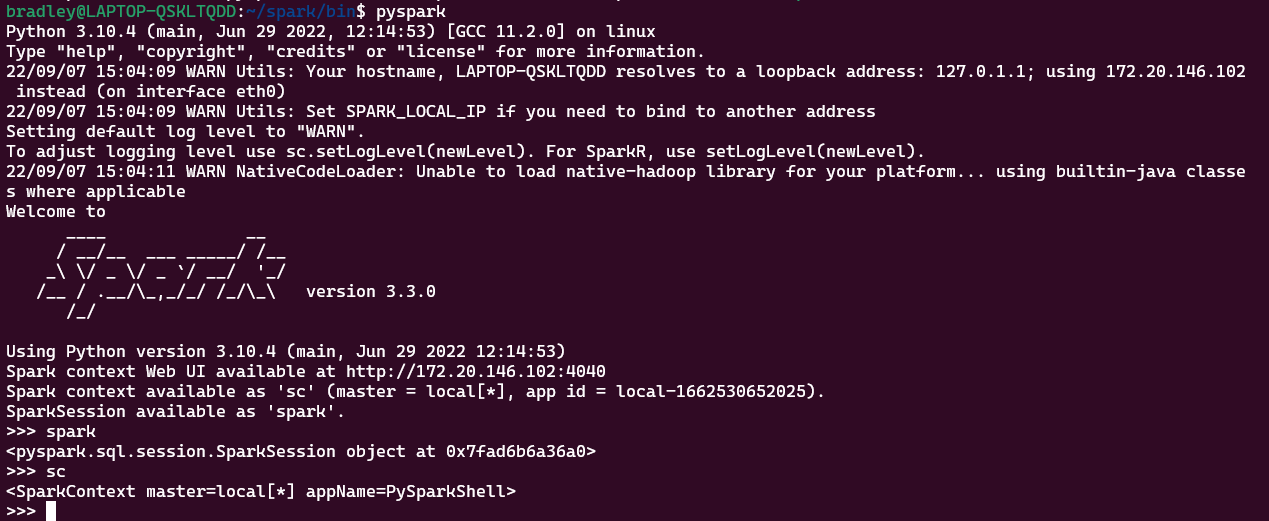
PySparkShell을 이용해 간단한 예제 실행
pyspark를 실행하여 PySparkShell을 실행한다.
PySparkShell을 실행하면 SparkSession과 SparkContext가 각각 spark, sc라는 객체로 자동 실행된다.
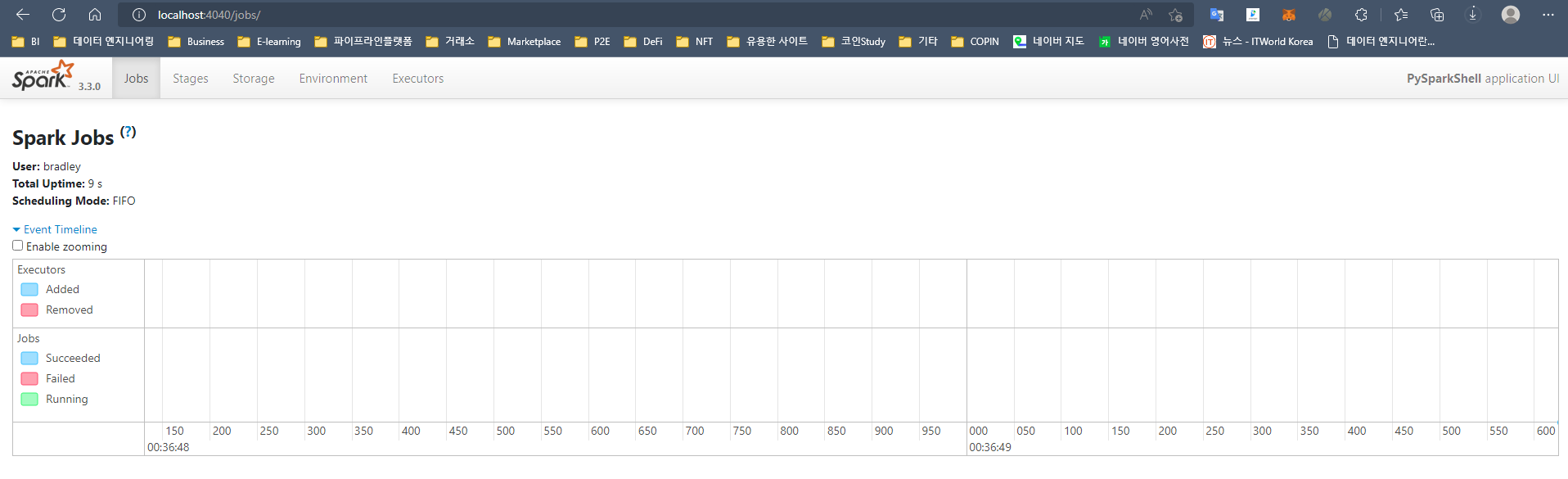
그리고 SparkContext가 실행되면 http://localhost:4040 을 통해 Spark Web UI에 접속할 수 있다. pyspark로 Shell을 실행시켰기 때문에 PySparkShell application UI가 뜨는 것을 볼 수 있다.
이제 간단한 Code를 실행시켜보자.
myRange = spark.range(1000).toDF("number")
divisBy2 = myRange.where("number % 2 = 0")
divisBy2.count()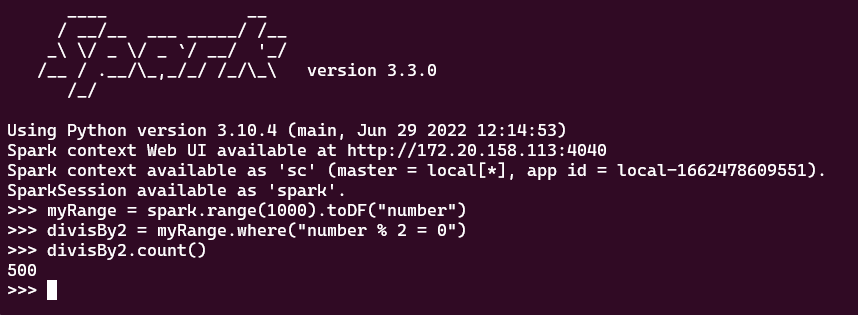
count() Action을 실행하면 http://localhost:4040 에 Job이 실행된 것을 확인할 수 있다.