
Apache Spark
Spark란 Single-node 또는 Cluster 위에서 Data Engineering, Data Science, Machine Learning을 수행할 수 있도록 도와주는 빅데이터 처리 및 분석을 위한 In-memory 기반의 통합 컴퓨팅 엔진이며, 데이터를 병렬로 처리하는 라이브러리 집합이다.
Spark의 주요 기능은 다음과 같다.

Batch/streaming data
데이터를 배치 처리 또는 실시간 처리할 수 있다. 이러한 처리는 SQL, Python, Scala, Java, R과 같은 Spark에서 지원하는 언어를 활용할 수 있다. 실시간의 경우 고수준의 Stream 처리 기능을 제공하는 구조적 스트리밍(Structured Streaming) 라이브러리를 제공하고 있다.
SQL analytics
빠른 분산 SQL Query를 지원한다. Spark SQL을 사용하면 기존에 DB 서비스에 SQL Query를 실행시키는 방식과 비슷한 SQL 문법으로 Query를 실행시킬 수 있다.
Data science at scale
petabyte 같은 큰 데이터에 대해서도 EDA(탐색적 데이터 분석)를 수행할 수 있다. EDA란 쉽게 말해 데이터를 조회하면서 패턴, 특이성과 같은 인사이트를 지속적으로 탐색하는 과정을 말한다.
Machine learning
다양한 머신러닝(ML) 알고리즘 라이브러리를 지원하며, 많은 연산을 필요로 하는 Training을 Cluster의 여러 Machine을 활용하여 수행할 수 있다.
Spark Ecosystem
Spark Ecosystem을 살펴보자.
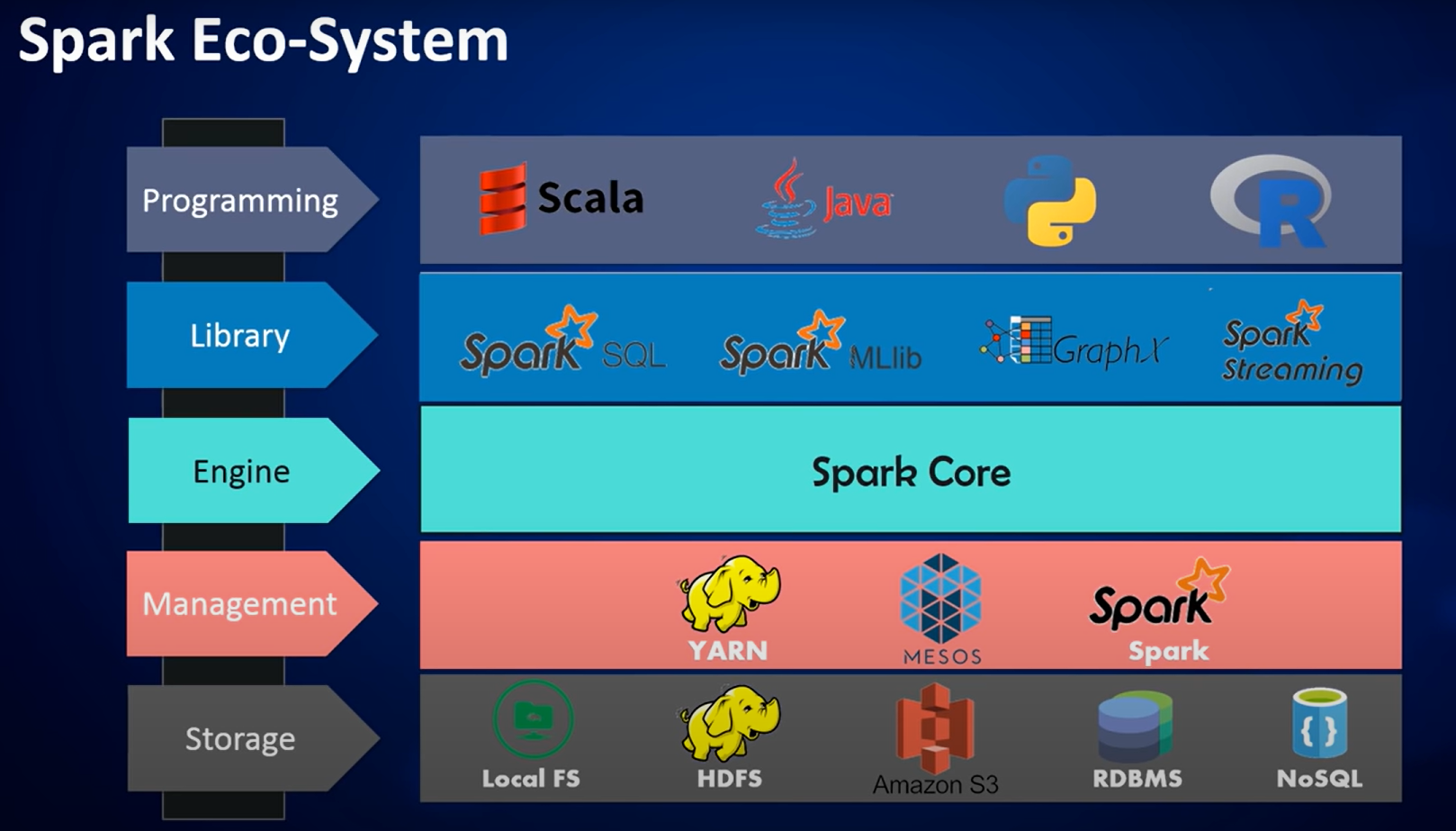
라이브러리
Spark는 Python, Scala, Java, R과 같은 다중 언어를 지원한다. 이 언어들을 통해 Spark SQL, Spark MLlib, GraphX, Spark Streaming 같은 기능의 라이브러리들을 사용할 수 있다.
자원 관리 (Cluster 관리)
자원관리는 Spark 자체 관리 기능(Spark Standalone Cluster Manager)을 사용하거나 Hadoop YARN 또는 Apache Mesos로 대체할 수도 있다.
현재 Kubernetes도 지원된다.
데이터 저장
Spark는 통합 컴퓨팅 엔진으로 기능 범위가 제한되어 있다. 따라서 연산 역할만 수행하지 저장소 역할을 수행하지는 않는다. 대신 Local FS(File System), HDFS(Hadoop Distributed File System), AWS S3 등과 같은 저장소 서비스 연결을 지원한다.
Architecture
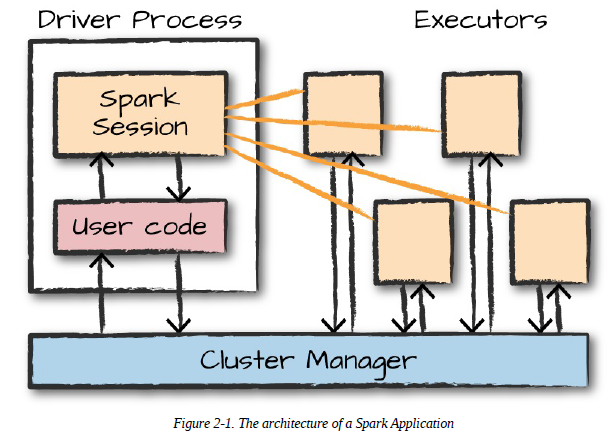
Spark Application은 Driver Process와 다수의 Executor Process로 구성된다.
Driver Process
Driver Process는 Node 중 하나에서 실행되며, main() 함수를 실행한다.
이는 Spark Application 정보의 유지 관리, 사용자 프로그램이나 입력에 대한 응답, 전반적인 Executor Process의 작업과 관련된 분석, 배포, Scheduling 역할을 수행한다.
Executor Process
Executor Process는 Driver Process가 할당한 작업을 수행한다. Driver가 할당한 Code를 실행하고, 진행 상황을 Driver Node에 보고한다.
Cluster Manager
Cluster Manager는 물리적인 Machine을 관리하고, Spark Application에 자원을 할당한다. Cluster Manager로 Spark Standalone Cluster Manager, Hadoop YARN, Apache Mesos, Kubernetes 중 하나를 선택할 수 있으며, 하나의 Cluster에서 여러 개의 Spark Application을 실행할 수 있다.
다양한 언어 API
<SparkSession과 Spark 언어 API 간의 관계>
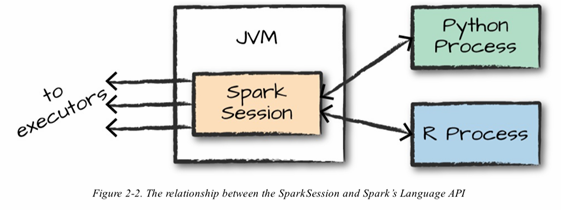
- Spark는 Scala로 개발되었으며, Java 가상머신(JVM) 기반으로 동작한다. 따라서 Spark를 실행하려면 Java가 필요하다.
- Spark는 Scala, Java, Python, R, SQL같은 다양한 언어를 지원한다. 이 언어로 작성한 Code는 Cluster Machine에서 실행되는 Spark Code로 변환되어 처리된다.
- 사용자가 Spark Code를 실행하기 위해
SparkSession객체를 진입점으로 사용할 수 있다. Spark Application은SparkSession이라 불리는 Driver Process로 제어하기 때문인데,SparkSession인스턴스는 사용자가 정의한 처리 명령을 Cluster에서 실행한다. - 하나의
SparkSession은 하나의 Spark Application에 대응한다. - Python이나 R로 Spark를 사용할 때는 JVM Code를 명시적으로 작성하지 않는다. Spark는 Python이나 R로 작성한 Code를 Executor의 JVM에서 실행할 수 있는 Code로 알아서 변환한다.
Spark API
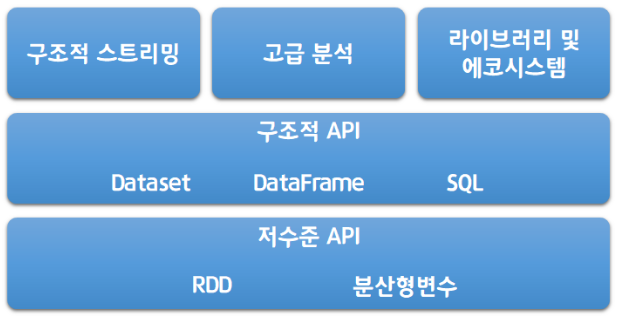
Spark를 다양한 언어로 사용할 수 있는 이유는 기본적으로 두 가지 API를 제공하기 때문이다. 하나는 저수준의 비구조적(unstructured) API, 다른 하나는 고수준의 구조적(structured) API이다. 그 외에에도 추가 기능을 제공하는 일련의 표준 라이브러리로 구성되어 있다.
DataFrame
DataFrame은 가장 대표적인 구조적(structured) API이다. 단순히 말해 테이블 형태를 말하며, Spreadsheet와 비슷하다. Spreadsheet는 한 대의 컴퓨터에 있지만, Spark의 DataFrame은 여러 대의 컴퓨터에 분산된다는 차이가 있다.
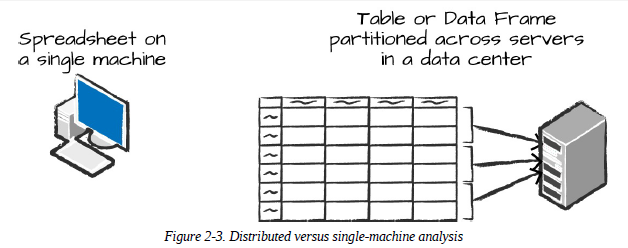
Partition
Spark는 모든 Executor가 병렬로 작업을 수행할 수 있도록 Partition이라 불리는 Chunk 단위로 데이터를 분할한다. Partition은 Cluster의 물리적 Machine에 존재하는 Row의 집합을 말한다.
만약 Partition 한 개, Executor 다수 또는 Partition 다수, Executor 한 개로 구성된다면 병렬성은 1이 된다.
DataFrame을 사용하면 Spark가 Partition에 대해 실제 처리 방법을 결정하기 때문에 Partition을 수동 혹은 개별적으로 처리할 필요가 없다.
Transformation
DataFrame을 변경하는 명령을 Transformation이라 한다. Transformation은 Action(아래에 설명)을 호출하지 않으면 수행되지 않는다.
# python
myRange = spark.range(1000).toDF("number") # 0 ~ 999
divisBy2 = myRange.where("number % 2 = 0")위 Code는 실행해도 결과가 출력되지 않는다. 추상적인 Transformation만 지정한 상태이다. Action을 호출해야 실제 Transformation을 수행한다.
정확히 말해, 명령을 실행하면 응답값이 출력되지만 데이터를 처리한 결과는 아니다
Action
실제 연산을 수행하려면 Action 명령을 내려야 한다. Action은 사용자가 정의한 일련의 Transformation들로부터 결과를 계산하도록 지시하는 명령이다.
count()는 Action 중 가장 단순한 Action으로, DataFrame의 전체 Record 수를 반환한다.
divisBy2.count() # 500예시 Code 직관적 흐름
Transformation
위 Code와 같이0 ~ 999값이 할당된numberColumn을 가진myRangeDataFrame에서 짝수값 Record를 구하는 필터링을 수행한 뒤(divisBy2)Action
count()Action을 실행하여 count를 구하면500이 반환된다.
Spark의 Transformation & Action 처리 과정을 좀 더 Detail하게 살펴보기 위해 뒷단에서 일어나는 과정을 살펴보면 다음과 같다.
1) Action을 지정하면 Spark Job이 시작된다.
2) Job은 Filter(좁은 Transformation)를 수행한 후
3) Partition별로 Record 수를 Count(넓은 Transformation)한다.
4) 그리고 각 언어에 적합한 Native 객체에 결과를 모은다.
Action 유형
- Console에서 데이터를 보는 Action
- 각 언어로 된 Native 객체에 데이터를 모으는 Action
- 출력 데이터 소스에 저장하는 Action
Transformation 특징
Transformation 유형
- 좁은(Narrow) Transformation : 좁은 의존성(Dependency)을 가진 Transformation
- 넓은(Wide) Transformation : 넓은 의존성을 가진 Transformation
좁은 Transformation
각 입력 Partition이 하나의 출력 Partition에만 영향을 미치는 것
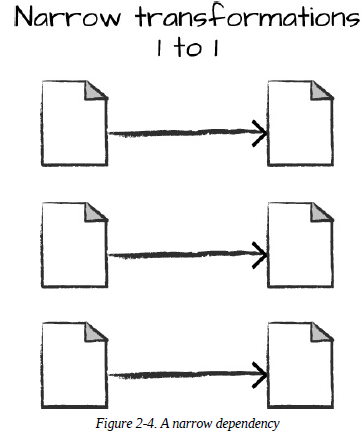
위 where() Code는 좁은 의존성을 가진다. 0~999 값이 5개의 Partition으로 나뉘었다고 가정하면, 각 Partition은 where() Transforamtion을 통해 각각 짝수값을 반환하는 5개의 출력 Partition을 생성한다고 볼 수 있다.
넓은 Transformation
하나의 입력 Partition이 여러 출력 Partition에 영향을 미치는 것
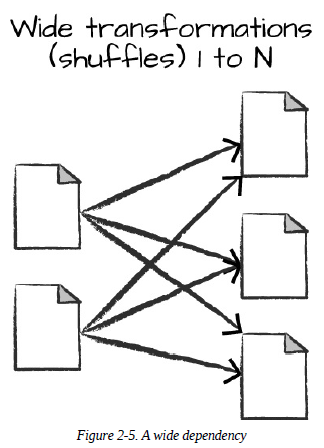
Spark가 Cluster에서 Partition을 교환하는 것을 셔플(Shuffle)이라고 한다.
좁은 Transformation을 사용하면 Spark에서 파이프라이닝(Pipelining)을 자동으로 수행한다. 즉, DataFrame에 여러 필터를 지정하는 경우 모든 작업이 Memory에서 일어난다.
하지만 Shuffle은 다른 방식으로 동작한다. Spark는 Shuffle의 결과를 Disk에 저장한다.
지연 연산
지연 연산(Lazy Evaluation)은 Spark가 연산 Graph를 처리하기 직전까지 기다리는 동작 방식을 말한다. Spark는 특정 연산 명령이 내려진 즉시 데이터를 수정하지 않고 원시 데이터에 적용할 Transformation의 실행 계획을 생성한다.
다시 말해 Code를 실행하는 마지막 순간까지 대기하다가 원형 DataFrame Transformation을 간결한 물리적 실행 계획으로 Compile한다. 이 과정을 거치면서 전체 데이터 흐름을 최적화한다.
예시
DataFrame의 조건절 푸시다운(predicate pushdown)을 예로 들 수 있다. 아주 복잡한 Spark Job이 원시 데이터에서 하나의 Row만 가져오는 Filter를 가지고 있다면 필요한 Record 하나만 읽는 것이 가장 효율적이다. Spark는 이 Filter를 데이터 소스로 위임하는 최적화 작업을 자동으로 수행한다.
위임
데이터 저장소가 DB라면WHERE절 처리를 DB에 위임한다. Spark는 하나의 Record만 받는다. 조건절 위임 기능을 사용하면 처리에 필요한 자원을 최소화 할 수 있다.
