Cluster Manager의 Architecture
우선 Spark를 논외로 하고, Cluster Manager를 살펴보자.
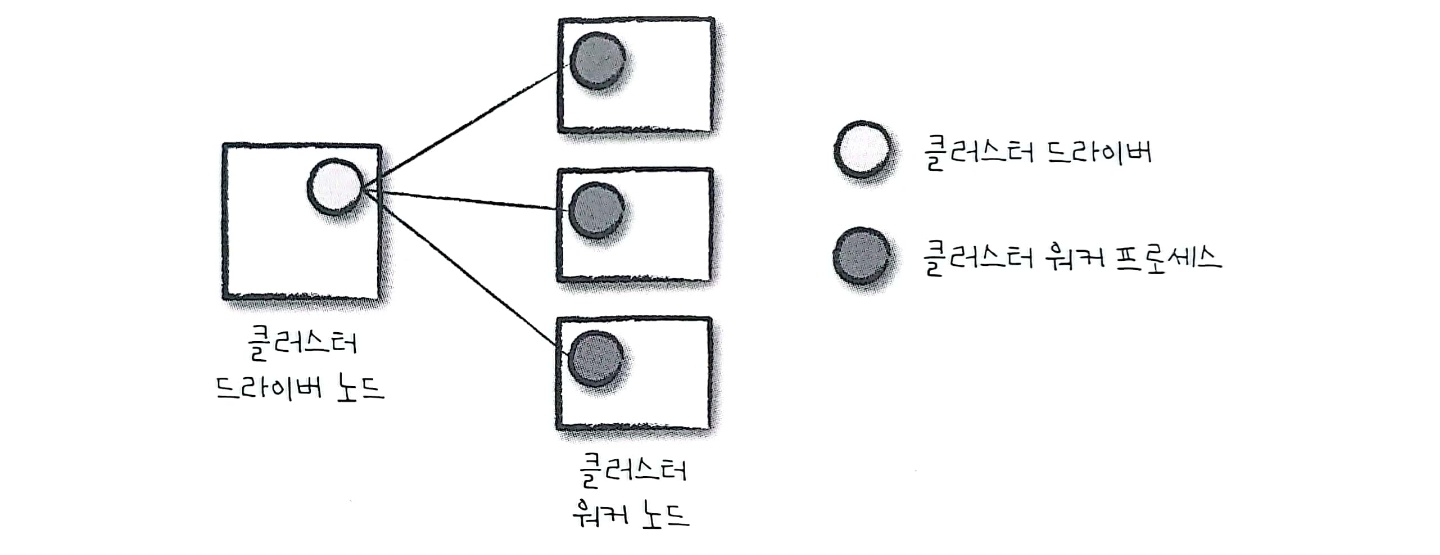
실행 중인 Spark Application이 없는 Cluster Driver와 Worker
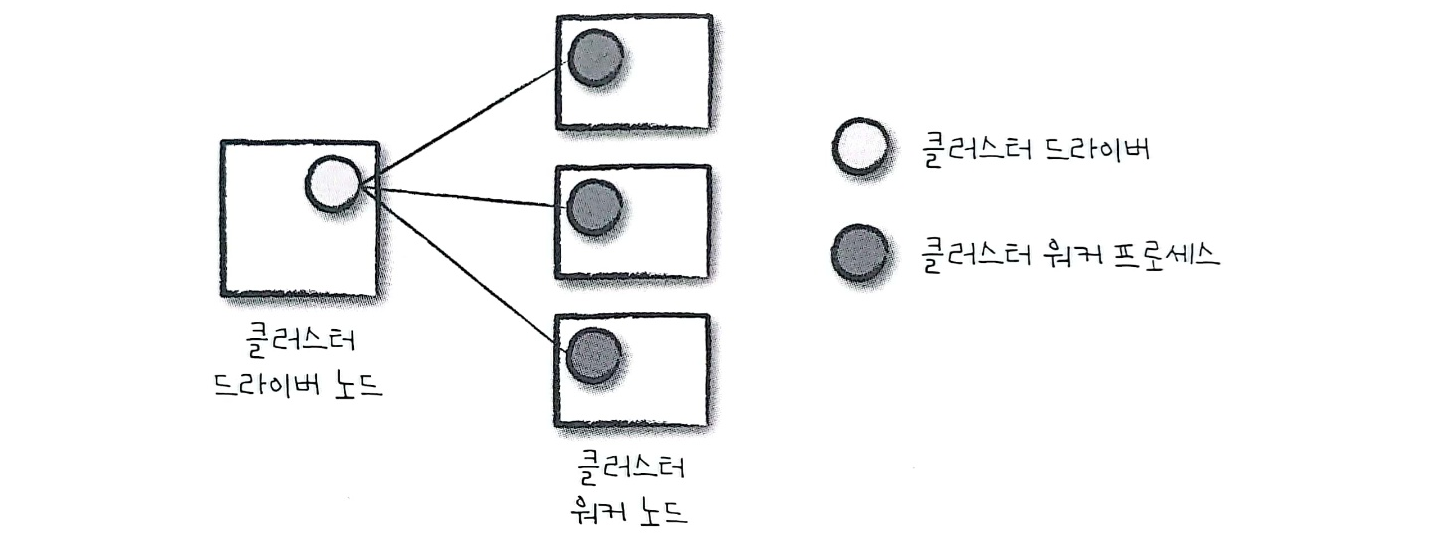
위 구조는 Cluster Manager의 구조를 보여준다. Cluster Manager는 Spark Application을 실행할 Machine을 유지한다.
Cluster Manager는 Driver와 Worker으로 구성된다.
Machine
왼쪽 Machine : Cluster Manager의 Driver Node
오른쪽 Machine : Cluster Manager의 Worker Node
원
왼쪽 원 : Cluster Manager의 Driver Process
오른쪽 원 : Cluster Manager의 Worker Process
Cluster Manager는 Driver와 Worker로 구성된다.
Spark는 Driver와 Executor로 구성된다.
Cluster Manager의 Driver와 Spark의 Driver는 다르다. Cluster Manager의 Component들은 물리적 Machine 개념이라고 생각하면 되고, Spark는 Process라고 생각하면 된다.
Spark Application을 실제로 실행할 때가 되면 우리는 Cluster Manager에 자원 할당을 요청한다. 사용자 Application의 설정에 따라 Spark Driver를 실행할 자원을 포함해 요청하거나 Spark Application 실행을 위한 Executor 자원을 요청할 수도 있다.
결론적으로 Spark Application의 실행 과정에서 Cluster Manager는 Application이 실행되는 Machine을 관리한다.
Spark가 지원하는 Cluster Manager는 다음과 같다.
- Standalone Cluster Manager
- Apache Mesos
- Hadoop YARN
- Kubernetes
실행 모드 (배포 모드)
실행 모드는 Spark Application을 실행할 때 요청한 자원의 물리적인 위치를 결정한다.
선택할 수 있는 실행 모드는 다음과 같다.
- Cluster Mode
- Client Mode
- Local Mode
이 중 Cluster Mode와 Client Mode는 Driver 실행에 차이가 있다.
| Deploy Mode | 비고 |
|---|---|
| Cluster | Spark Application을 실행하는 Node에서 Driver 실행 |
| Client | Cluster 내부의 Node에서 Driver 실행 |
Cluster Mode
하나의 Worker Node에 Spark Driver를 할당하고, 다른 Worker Node에 Executor를 할당한다.
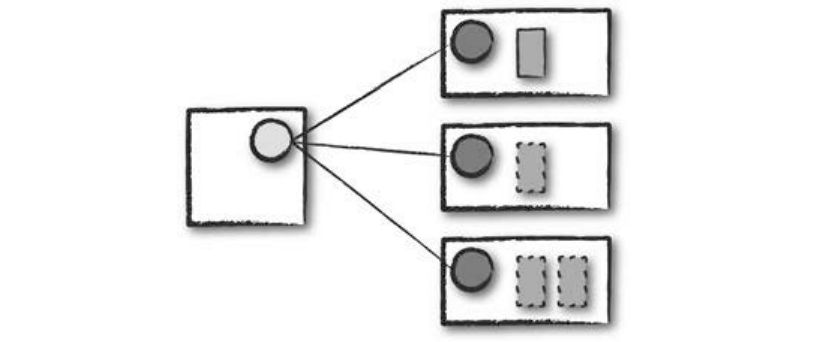
실선 네모박스 : Spark Driver Process
점선 네모박스 : Spark Executor Process
- 가장 흔하게 사용되는 Spark Application 실행 방식
- Cluster Mode를 사용하려면 Compiled 된 JAR 파일 / Python Script / R Script를 Cluster Manager에 전달해야 한다.
- Cluster Manager는 파일을 받은 다음 Worker Node에 Driver Process와 Spark Executor Process를 실행한다.
- 이 때 Cluster Manager는 모든 Spark Application과 관련된 Process를 유지하는 역할을 한다.
Client Mode
Spark Driver는 Cluster 외부의 Machine에서 실행되며, 나머지 Worker는 Cluster에 위치해 있다.
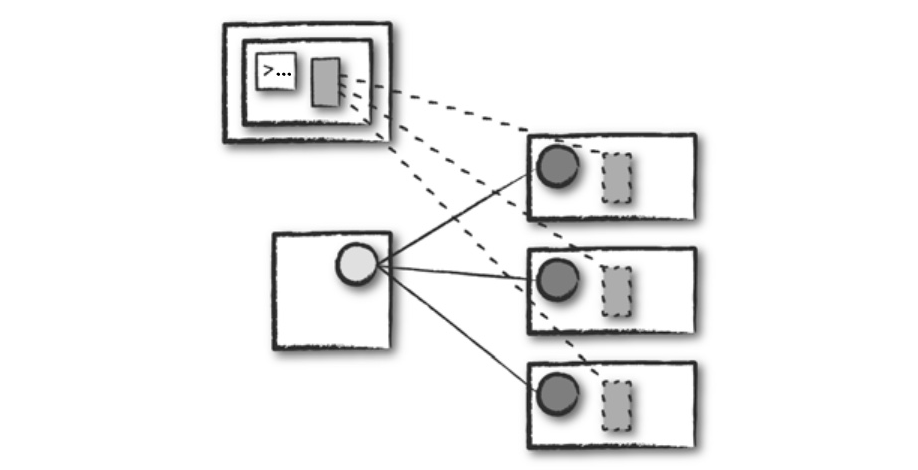
실선 네모박스 : Spark Driver Process
점선 네모박스 : Spark Executor Process
- Cluster Mode와 비슷하지만 다른 점은 Application을 제출한 Client Machine에 Spark Driver가 위치한다.
- 이 때 Cluster Manager는 Executor Process를 유지하고, Client Machine은 Spark Driver Process를 유지한다.
- 그림에서 보다시피 Spark Application이 Cluster와 무관한 Machine에서 동작하는데 보통 이런 Machine을 Gateway Machine 또는 Edge Node라고 부른다.
Local Mode
- 이 경우 모든 Spark Application은 단일 Machine에서 실행된다.
- Local Mode는 Application의 병렬 처리를 위해 단일 Machine의 스레드(Thread)를 활용한다.
- Spark 학습, Application Test, 개발 중인 Application 반복 실험 용도로 주로 사용된다.
- 운영용 Application을 실행할 때는 Local Mode가 권장되지 않는다.
Spark 실행 방법
Spark는 다음과 같은 방법으로 실행할 수 있다.
SparkSession을 자동으로 실행시켜주는 대화형 모드에서의 실행
- 언어별 실행 Script를 통해 Prompt로 실행
- Jupyter Notebook 또는 Zepplin 같은 대화형 Notebook을 통한 실행- Spark Application 제출을 통해 실행
언어별 실행 Script를 통한 실행
Spark Application은 Scala, Java, Python, R, SQL로 실행할 수 있다.
$SPARK_HOME/bin에 가면 언어별 실행 Script를 볼 수 있다.
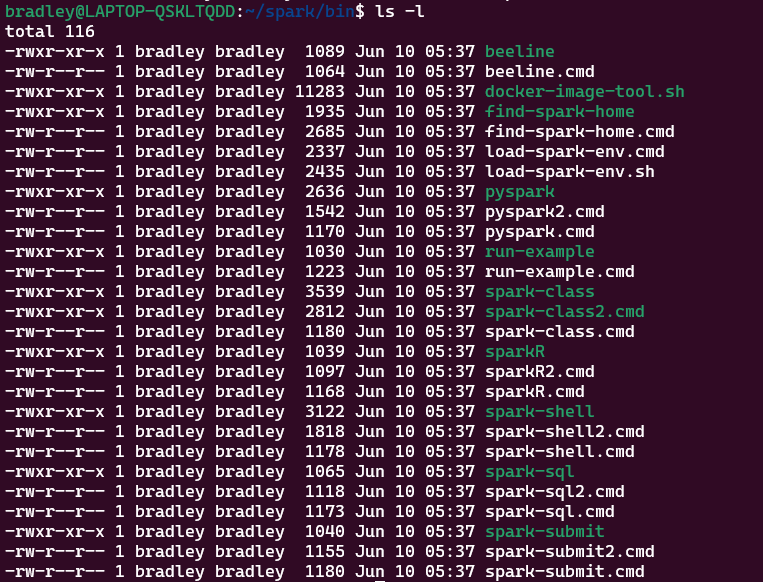
pyspark: Python용 Spark Prompt를 실행하는 ScriptsparkR: R용 Spark Prompt를 실행하는 Scriptspark-shell: Scala용 Spark Prompt를 실행하는 Scriptspark-sql: SparkSQL Prompt를 실행하는 Script
예시
대화형 Notebook을 이용한 실행
추후 포스팅
Spark Application 제출을 통한 실행
Spark Application을 제출함으로써 Spark를 실행시키기 위해서는 spark-submit 명령을 사용한다.
spark-submit은 Scala나 Java로 작성한 Spark Application을 JAR 파일로 실행하거나, Python Script 파일 또는 R Script 파일을 제출하여 Spark를 실행할 때 사용한다.
spark-submit은 다음과 같이 실행할 수 있다.
$ ./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<app jar | python file | R file> \
[application-arguments]옵션값
| 옵션 | 설명 |
|---|---|
--master | Cluster Manager 설정 |
--deploy-mode | Driver의 Deploy Mode 설정 |
--class | main() 함수가 들어있는 Class 지정 |
--name | Application의 이름 지정, Spark Web UI에 표시 |
--jars | Application 실행에 필요한 Library 목록, 콤마(,)로 구분 |
--files | Application 실행에 필요한 파일 목록 |
--queue | YARN의 실행 Queue 이름 설정 |
--executor-memory | Executor가 사용할 Memory byte 용량 |
--driver-memory | Driver가 사용할 Memory byte 용량 |
--num-executors | Excutor 갯수 설정 |
--executor-cores | Executor Core 갯수 설정 |
Master URL
| 옵션 | 설명 |
|---|---|
spark://HOST:PORT | Spark Standalone Cluster 사용 |
mesos://HOST:PORT | Apache Mesos 사용 |
yarn | Hadoop YARN Cluster 사용 HADOOP_CONF_DIR 설정 참조하여 처리 |
k8s://HOST:PORT | Kubernetes 사용 |
local | Local Mode에서 실행 |
local[N] | Local Mode에서 Core 갯수를 지정해서 실행 |
spark-submit 예시
| 예시 | 예시 명령 |
|---|---|
| Local 8 Core에서 Application 실행 | ./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master local[8] \/path/to/examples.jar \100 |
| Client 배포 모드로 Spark Standalone Cluster에서 실행 | ./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://207.184.161.138:7077 \--executor-memory 20G \--total-executor-cores 100 \/path/to/examples.jar \1000 |
Cluster 배포 모드로 Spark Standalone Cluster에서 실행--supervise : Driver 실패 시 재시작 (Standalone/Mesos 지원) | ./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://207.184.161.138:7077 \--deploy-mode cluster \--supervise \--executor-memory 20G \--total-executor-cores 100 \/path/to/examples.jar \1000 |
| Cluster 배포 모드로 YARN Cluster에서 실행 | export HADOOP_CONF_DIR=XXX./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn \--deploy-mode cluster \--executor-memory 20G \--num-executors 50 \/path/to/examples.jar \1000 |
| Spark Standalone Cluster에서 Python Application 실행 | ./bin/spark-submit \--master spark://207.184.161.138:7077 \examples/src/main/python/pi.py \1000 |
Cluster 배포 모드로 Mesos Cluster에서 실행--supervise : Driver 실패 시 재시작 (Standalone/Mesos 지원) | ./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master mesos://207.184.161.138:7077 \--deploy-mode cluster \--supervise \--executor-memory 20G \--total-executor-cores 100 \http://path/to/examples.jar \1000 |
| Cluster 배포 모드로 Kubernetes Cluster에서 실행 | ./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master k8s://xx.yy.zz.ww:443 \--deploy-mode cluster \--executor-memory 20G \--num-executors 50 \http://path/to/examples.jar \1000 |
Local Mode 실행 예시
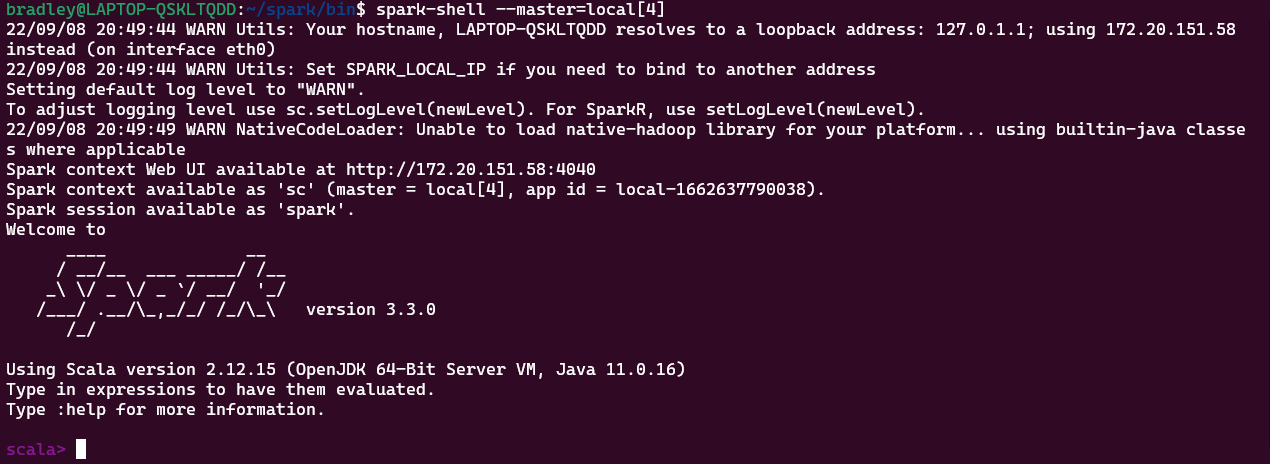
--master=local
default값으로, 별도로 명시하지 않아도 된다.
spark-shell 명령으로 간단히 실행해보자.
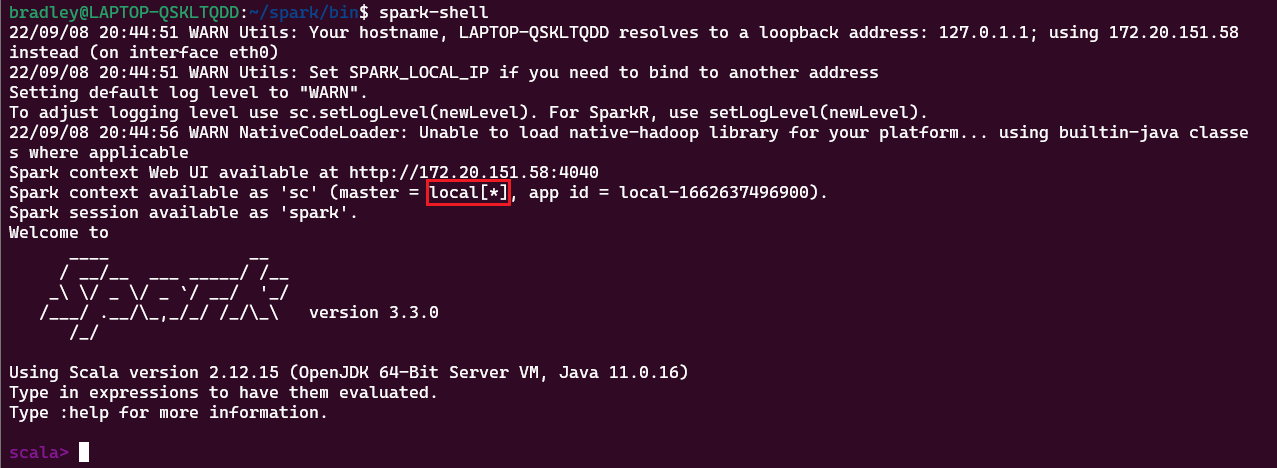
Core가 [*]로 할당되었다. 컴퓨터가 가진 Core 수로 할당된다.
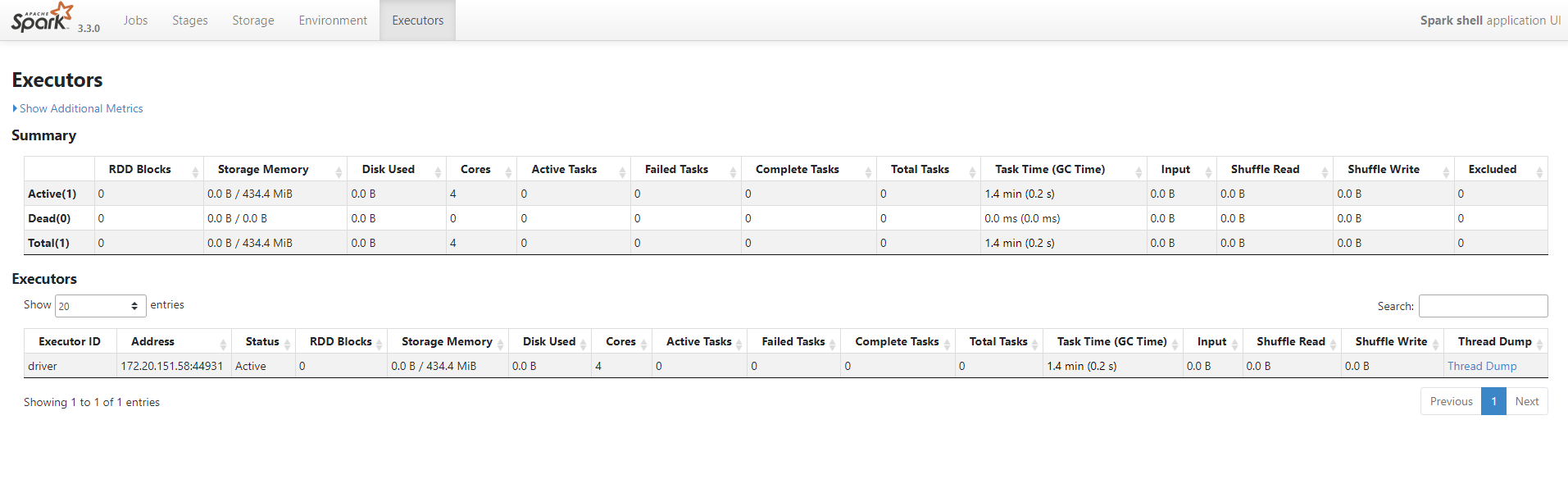
http://localhost:4040/executors/ 에 접속하면 할당된 Core를 확인할 수 있다.
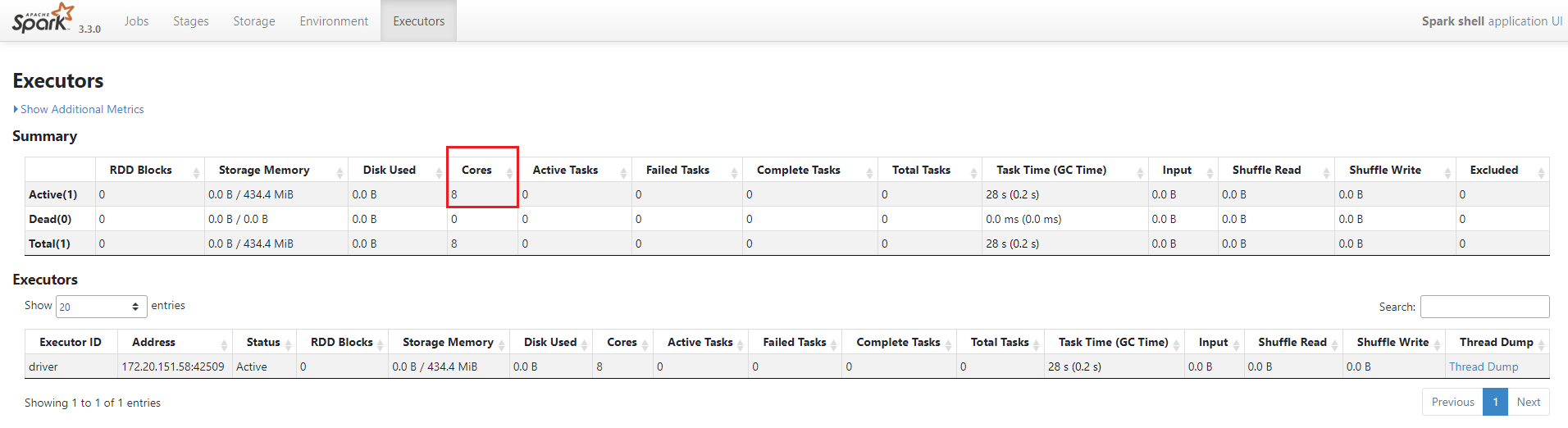
--master=local[N]
N개의 Core를 할당한다.
그림은 4개의 Core를 할당한 것을 보여준다.