사이킷런 Sklearn
1.머신러닝 프로세스 A to Z

2.로지스틱 회귀모델 (Logistic Regression)

1. 분석 데이터 준비 2. 기본모델 적용 3. Grid Search 4. Random Search
3.K최근접이웃법 (KNN, K-Nearest Neighbor)

Part1. 분류(Classification) 1. 분석 데이터 준비 2. 기본모델 적용 3. Grid Search 4. Random Search Part2. 회귀(Regression) 1. 분석 데이터 준비 2. 기본모델 적용 3. Grid Search
4.나이브 베이즈 (Naive Bayes)
Part1. 분류(Classification) 1. 분석 데이터 준비 2. 기본모델 적용 3. Grid Search 4. Random Search Part2. 회귀(Regression) 1. 분석 데이터 준비 2. 기본모델 적용 3. Grid Search
5.인공신경망 (ANN, Artificial Neural Network)
Part1. 분류(Classification) 1. 분석 데이터 준비 2. 기본모델 적용 3. Grid Search 4. Random Search Part2. 회귀(Regression) 1. 분석 데이터 준비 2. 기본모델 적용 3. Grid Search
6.서포트 벡터 머신 (support vector machine, SVM)
Part1. 분류(Classification) 1. 분석 데이터 준비 2. 기본모델 적용 3. Grid Search 4. Random Search Part2. 회귀(Regression) 1. 분석 데이터 준비 2. 기본모델 적용 3. Grid Search
7.의사결정나무 (Decision Tree)
Part1. 분류(Classification) 1. 분석 데이터 준비 2. 기본모델 적용 3. Grid Search 4. Random Search Part2. 회귀(Regression) 1. 분석 데이터 준비 2. 기본모델 적용 3. Grid Search
8.랜덤 포레스트 (Random Forest)
Part1. 분류(Classification) 1. 분석 데이터 준비 2. 기본모델 적용 3. Grid Search 4. Random Search Part2. 회귀(Regression) 1. 분석 데이터 준비 2. 기본모델 적용 3. Grid Search
9.앙상블 (Ensemble)
Part1. 분류(Classification) 1. 분석 데이터 준비 2. 강한 학습기: hard learner 3. 약한 학습기: soft learner 4. Random Search Part2. 회귀(Regression) 1. 분석 데이터 준비 2. 모
10.배깅(Bagging)
Part1. 분류(Classification) 1. 분석 데이터 준비 2. 모델적용 Part2. 회귀(Regression) 1. 분석 데이터 준비 2. 모델적용
11.부스팅 (Boosting)
Part1. 분류(Classification) 1. 분석 데이터 준비 2. 모델적용 2-1. AdaBoosting 2-2. Gradient Boosting Part2. 회귀(Regression) 1. 분석 데이터 준비 2. 모델적용 2-1. AdaBoos
12.스태킹 (Stacking)
Part1. 분류(Classification) 1. 분석 데이터 준비 2. 모델적용 Part2. 회귀(Regression) 1. 분석 데이터 준비 2. 모델적용
13.선형회귀(Linear)모델
1. 분석 데이터 준비 2. Statmodel 적용 3. Scikit-learn 적용
14.릿지(Ridge) 회귀모델
1. 분석 데이터 준비 2. 기본 모델 적용 3. Grid Search 4. Random Search
15.라쏘(Lasso) 회귀모델
1. 분석 데이터 준비 2. 기본 모델 적용 3. Grid Search 4. Random Search
16.엘라스틱넷 (Elsatic-net)
1. 분석 데이터 준비 2. 기본 모델 적용 3. Grid Search 4. Random Search
17.군집분석 (Clustering)
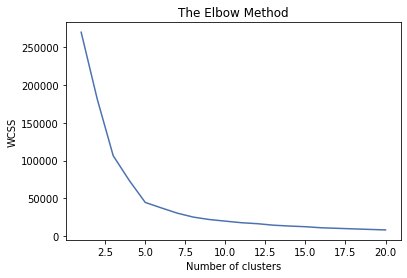
1. Clustering 이해 2. k-mean Clustering 3. Hierarchical Clustering
18.DBSCAN (밀도기반 클러스터링)
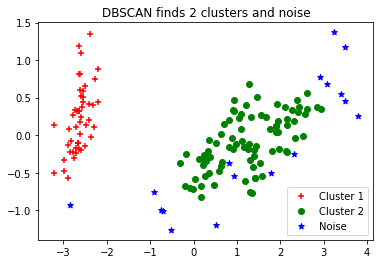
1. 분석 데이터 불러오기 및 확인 2. DBSCAN 모델 적용 3. 시각화
19.연관규칙분석 (association rule, Apriori Algorithm)
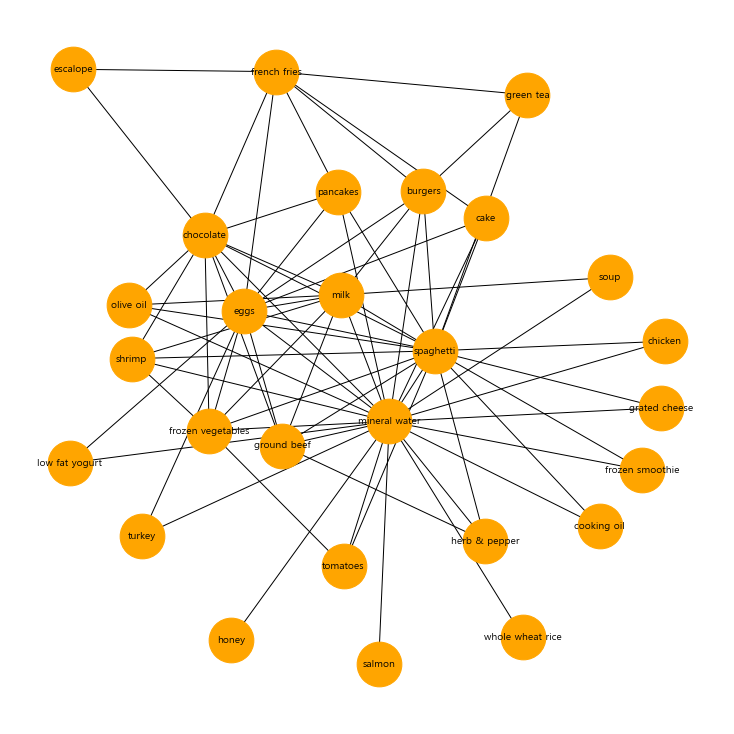
1. 분석 데이터 불러오기 및 확인 2. apriori 모델 적용 3. 연관품목의 시각화