0. 핵심개념 및 사이킷런 알고리즘 API 링크
DBSCAN (밀도기반 클러스터링, Density-based saptial clustering of applications with noise)은 케이스가 집중되어 있는 밀도(density)에 초점을 두어 밀도가 높은 그룹을 클러스터링 하는 방식이다. 중심점을 기준으로 특정한 반경 이내에 케이스가 n개 이상 있을 경우 하나의 군집을 형성하는 알고리즘이다.
DBSCAN에서 분석자가 설정해야 하는 파라미터(parameter)는 다음과 같다.
- epsilon : 근접 이웃점을 찾기 위해 정의 내려야 하는 반경 거리
- minPts (minimum amount of points) : 하나의 군집을 형성하기 위해 필요한 최소한의 케이스 수
여기서 데이터의 케이스(포인트)는 3가지로 분류한다.
- Core point : 엡실론 반경 내에 최소점 이상을 갖는 점
- Border point : 코어 포인트의 엡실론 반경 내에 있으나 그 자체로는 최소점을 갖지 못하는 점
- Noise point: 코어 포인트도 아니고 보더 포인트도 아닌 점
1. 분석 데이터 불러오기 및 확인
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
iris = pd.read_csv("iris.csv")
iris_data=iris[iris.columns[0:4]]
iris_data.head()
sepal_length sepal_width petal_length petal_width
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.22. DBSCAN 모델 적용
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.5, metric='euclidean', min_samples=5)
dbscan
DBSCAN()
dbscan.fit(iris_data)
DBSCAN()
dbscan.labels_
array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 1,
1, 1, 1, 1, 1, 1, -1, 1, 1, -1, 1, 1, 1, 1, 1, 1, 1,
-1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, -1, 1, 1, 1, 1, 1, -1, 1, 1, 1, 1, -1, 1, 1, 1,
1, 1, 1, -1, -1, 1, -1, -1, 1, 1, 1, 1, 1, 1, 1, -1, -1,
1, 1, 1, -1, 1, 1, 1, 1, 1, 1, 1, 1, -1, 1, 1, -1, -1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
dtype=int64)
pred=dbscan.fit_predict(iris_data)
pred=pd.DataFrame(pred)
pred.columns=['predict']
pred.head()
predict
0 0
1 0
2 0
3 0
4 0
match_data = pd.concat([iris,pred],axis=1)
match_data.tail(5)
sepal_length sepal_width petal_length petal_width class predict
100 6.3 3.3 6.0 2.5 Iris-virginica 1
101 5.8 2.7 5.1 1.9 Iris-virginica 1
102 7.1 3.0 5.9 2.1 Iris-virginica 1
103 6.3 2.9 5.6 1.8 Iris-virginica 1
104 6.5 3.0 5.8 2.2 Iris-virginica 1
cross = pd.crosstab(match_data['class'],match_data['predict'])
cross
predict -1 0 1
class
Iris-setosa 1 49 0
Iris-versicolor 6 0 44
Iris-virginica 10 0 403. 시각화
from sklearn.decomposition import PCA
pca = PCA(n_components=2).fit(iris_data)
pca_2d = pca.transform(iris_data)
for i in range(0, pca_2d.shape[0]):
if dbscan.labels_[i] == 0:
c1 = plt.scatter(pca_2d[i,0],pca_2d[i,1],c='r', marker='+')
elif dbscan.labels_[i] == 1:
c2 = plt.scatter(pca_2d[i,0],pca_2d[i,1],c='g', marker='o')
elif dbscan.labels_[i] == -1:
c3 = plt.scatter(pca_2d[i,0],pca_2d[i,1],c='b', marker='*')
plt.legend([c1, c2, c3], ['Cluster 1', 'Cluster 2', 'Noise'])
plt.title('DBSCAN finds 2 clusters and noise')
plt.show()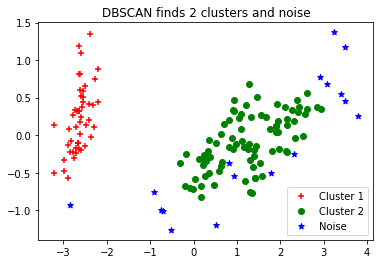
pca_2d