

파일명 : [DS]edatest 1_honggildong.ipynb
1단계: DataFrame 불러오기 & 전처리
1-1
** 0, 1, 2번 index의 row를 제거하고 index를 초기화 하세요(기존 index는 삭제(drop)하세요 (10점)
# 1-1
# 파일명.drop([삭제값], axis=0/1, inplace=True) : 컬럼 삭제
# reset_index() : 행 인덱스 초기화, 0부터 시작하는 정수형 인덱스로 초기화, 기존 인덱스 컬럼은 컬럼으로 밀려남
raw_data = 'datas/report.txt'
df = pd.read_table(raw_data, encoding='utf-8')
df.drop([0, 1, 2], axis = 0, inplace = True)
df = df.reset_index(drop = True)
df.head()1-2
현재의 컬럼명(current_columns)을 아래 new_columns와 같이 변경하세요 (10점)
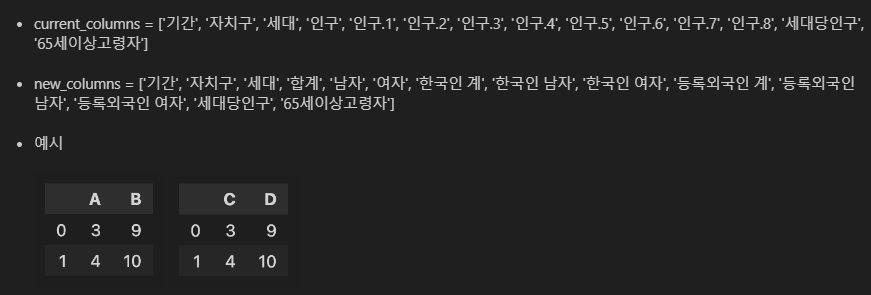
# 1-2
df.columns = ['기간', '자치구', '세대', '합계', '남자', '여자', '한국인 계', '한국인 남자', '한국인 여자', '등록외국인 계', '등록외국인 남자', '등록외국인 여자', '세대당인구', '65세이상고령자']
df.tail()
1-3
단위 구분자 " , "를 제거하고, data의 type을 int 또는 float으로 변경하세요. (10점)

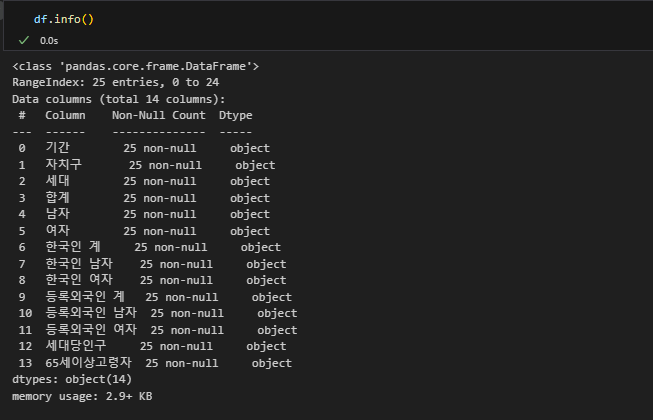
# 1-3
# 변수.replace(바뀔것, 바뀐것)
# .astype : 데이터 형태 변환 in 유가분석 mini project
change_type = ['세대', '합계', '남자', '여자', '한국인 계', '한국인 남자', '한국인 여자', '등록외국인 계', '등록외국인 남자', '등록외국인 여자', '세대당인구','65세이상고령자']
for col in change_type:
if col == '세대당인구':
df[col] = df[col].str.replace(',','').astype('float')
else:
df[col] = df[col].str.replace(',','').astype('int')
check_01_03(df)
2단계: 원하는 정보 얻기
2-1
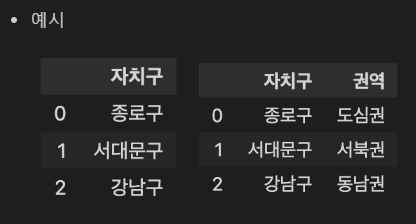
1단계에서 구한 DataFrame에 '권역' column을 추가하여 해당 구에 맞는 권역을 입력하세요. (5점)
# 2-1
# 컬럼을 추가, 추가한 값은 nan으로 전부 채워줌
# 반복문으로 nan 채우기
import numpy as np
region_dict_key = list(region_dict.keys())
region_dict_value = list(region_dict.values())
df['권역'] = np.nan
for i in range(len(df)):
for j in range(len(region_dict_key)):
if df['자치구'][i] in region_dict_value[j]:
df['권역'][i] = region_dict_key[j]
else:
continue
check_02_01(df)
2-2
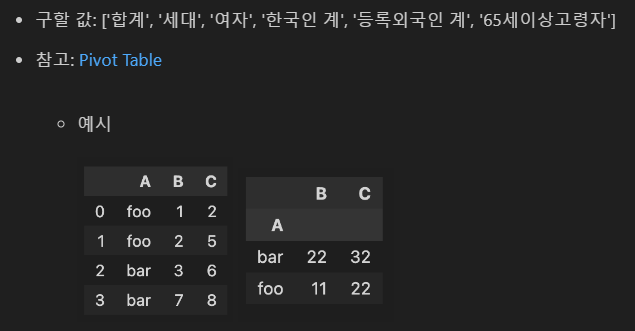
2-1에서 만든 DataFrame을 이용하여 Pandas의 pivot_table 메소드를 활용하여 각 권역별 아래 값의 합을 구하고, '합계'를 기준으로 내림차순 정렬하세요. (5점)
- 구할 값: ['합계', '세대', '여자', '한국인 계', '등록외국인 계', '65세이상고령자']
# 2-2
# aggfunc=np.sum : 합계 기능 추가
# sort_values() : '특정 컬럼' 만 보기
# ascending = False : 내림차순
import numpy as np
import pandas as pd
Values = ['합계', '세대', '여자', '한국인 계', '등록외국인 계', '65세이상고령자']
df_pivot = pd.pivot_table(data = df, index= '권역', values= Values, aggfunc=np.sum).sort_values(by='합계',ascending = False)
check_02_02(df_pivot)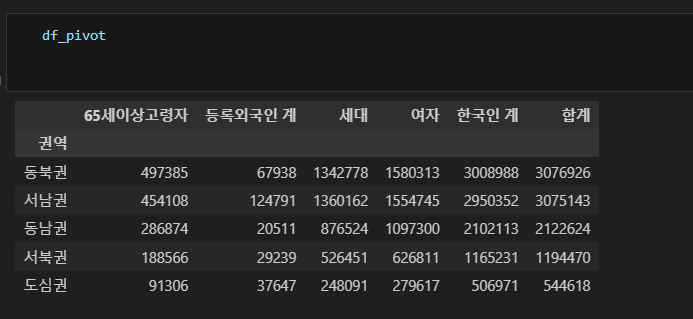
2-3
2-2에서 만든 Pivot Table을 이용하여 각 권역별 ['고령자비율', '외국인비율', '여성비율', '세대당인구'] 컬럼을 만들어 아래와 같이 값을 입력하고 '외국인비율'을 기준으로 오름차순 정렬하세요. (5점)
-
고령자비율: 65세이상고령자 / 합계 * 100
-
외국인비율: 등록외국인 계 / 합계 * 100
-
여성비율: 여자 / 합계 * 100
-
세대당인구: (합계 - 등록외국인 계) / 세대

# 2-3
df_pivot['고령자비율'] = df_pivot['65세이상고령자'] / df_pivot['합계'] * 100
df_pivot['외국인비율'] = df_pivot['등록외국인 계'] / df_pivot['합계'] * 100
df_pivot['여성비율'] = df_pivot['여자'] / df_pivot['합계'] * 100
df_pivot['세대당인구'] = (df_pivot['합계'] - df_pivot['등록외국인 계']) / df_pivot['세대']
df_pivot.sort_values('외국인비율', ascending=True, inplace=True)
check_02_03(df_pivot)
2-4
2-1에서 만든 DataFrame을 이용하여 각 구별 ['고령자비율', '외국인비율', '여성비율'] 컬럼을 만들어 아래와 같이 값을 입력하고 '세대당인구'을 기준으로 내림차순 정렬하세요. (5점)
- 고령자비율: 65세이상고령자 / 합계 * 100
- 외국인비율: 등록외국인 계 / 합계 * 100
- 여성비율: 여자 / 합계 * 100
# 2-4
df['고령자비율'] = df['65세이상고령자'] / df['합계'] * 100
df['외국인비율'] = df['등록외국인 계'] / df['합계'] * 100
df['여성비율'] = df['여자'] / df['합계'] * 100
df.sort_values('세대당인구', ascending = False, inplace = True)
check_02_04(df)
2-5
2-3에서 만든 DataFrame을 이용하여 ['고령자비율', '외국인비율', '여성비율', '세대당인구']간의 피어슨 상관계수 행렬(Correlation matrix)를 구하세요. (10점)
-
참고
- 상관계수(correlation coefficient): 두 변수가 함께 변하는 정도를 -1 ~ +1 범위의 수로 나타낸 것 - 피어슨 상관계수: 칼 피어슨(Karl Pearson)이 개발한 상관계수로, 일반적으로 상관계수라고 하면 피어슨 상관계수를 말함 - Standard Correlation Coefficient - r(상관계수) = X와 Y가 함께 변하는 정도 / X와 Y가 각각 변하는 정도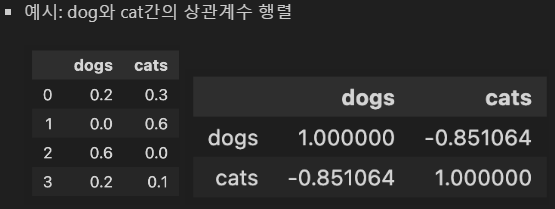
# 2-5
# corr() : 컬럼을 기준으로 값들 사이의 상관관계 연산
pivot_corr = df_pivot[['고령자비율', '외국인비율', '여성비율', '세대당인구']].corr()
check_02_05(pivot_corr)
pivot_corr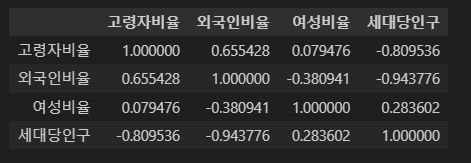
3단계: 시각화
3-1
# 3-1: barh
def drawGraph():
df.sort_values(by='고령자비율', ascending=True).plot(x='자치구', y='고령자비율', kind='barh', grid=True, figsize=(8,8))
plt.ylabel('자치구')
plt.legend(labels=['고령자비율'])
plt.scatter(x=df['고령자비율'], y= df['자치구'])
drawGraph()3-2
# 3-2: Pie
def drawGraph():
df_pivot
plt.figure(figsize = (8,8))
plt.ylabel('등록외국인계')
plt.pie(
df_pivot['등록외국인 계'],
labels = df_pivot.index
)
plt.legend(title = '권역')
drawGraph() 3-3
# 3-3: Boxplot
import seaborn as sns
df.boxplot(column='외국인비율', by='권역', figsize=(8,8))
3-4

# 3-4: scatterplot + regression
plt.figure(figsize = (8, 8))
sns.lmplot(data = df, x = '외국인비율', y = '세대당인구')
plt.grid(False)제로베이스 데이터 스쿨
