
정말...오랜만에...밤을 샜다...
1.번
지금까지의 상황을 본다면 아마도 서울시의 구를 선택하는 화면까지는 셀레니움으로 진행을 해야할 지도
모릅니다.
그리고 난 후 구별 매장의 위치는 beautiful soup으로 가지고 올 수 있을 것 같습니다.
여러분들은 서울시의 스타벅스 매장의 이름과 주소, 구 이름을 pandas data frame으로 정리해 두세요.
- 스타벅스
#페이지 접근
url = 'https://www.starbucks.co.kr/store/store_map.do'
driver = webdriver.Chrome(executable_path='../driver/chromedriver.exe')
driver.get(url)# 서울 매장 검색까지 가기
import time
# 지역 클릭
driver.find_element(
By.CSS_SELECTOR,
'#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search > h3 > a'
).click()
time.sleep(1)
# 서울 클릭
driver.find_element(
By.CSS_SELECTOR,
'#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a'
).click()
time.sleep(1)
# 전체 클릭
driver.find_element(
By.CSS_SELECTOR,
'#mCSB_2_container > ul > li:nth-child(1) > a'
).click()
# bs4로 데이터 불러오기
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
print(soup.prettify)# 매장별 데이터(정보) 가져오기
sido_contents = soup.select('.quickResultLstCon')
sido_contents, len(sido_contents)# 어떤 콘텐츠/텍스트가 들어가 있는지 확인
sido_contents[3].select_one('p').text, sido_contents[3].select_one('strong').text# 전화번호 텍스트 분리
a = sido_contents[3].select_one('p').text.split(' ')
ab = sido_contents[3].select_one('p').text[:-9]
b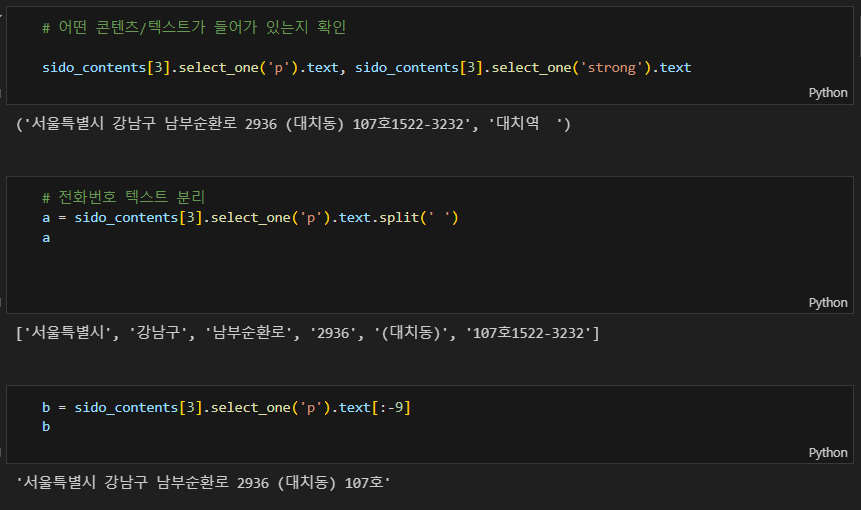
# 주소, 구, 이름 - pandas DataFrame 만들기
from tqdm import tqdm_notebook
address_list =[]
gu_list =[]
name_list =[]
for idx in tqdm_notebook(sido_contents):
address = idx.select_one('p').text[:-9]
gu = idx.select_one('p').text.split(' ')[1]
name = idx.select_one('strong').text
address_list.append(address)
gu_list.append(gu)
name_list.append(name)
df = pd.DataFrame(
{
'brand' : '스타벅스',
'gu' : gu_list,
'name' : name_list,
'address' : address_list
}
)
df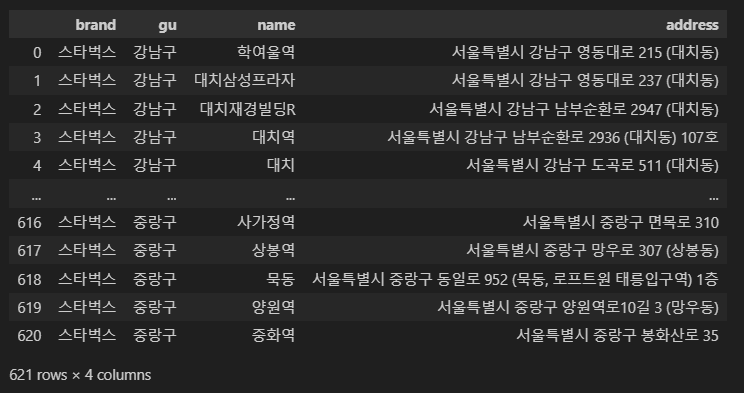
# 전화번호 보기 싫어서 위에서 텍스트 분리 진행
# 후 다시 저장
starbucks = pd.DataFrame(df)
starbucks.to_csv('[DS]eda1_sta_location.csv', index = False, encoding='utf-8')driver.quit()2.번
여러분들은서울시의이디야커피매장의이름과주소,구이름을pandasdataframe으로정리해두세요.
- 이디야
#페이지 접근
url = 'https://ediya.com/contents/find_store.html'
driver = webdriver.Chrome(executable_path='../driver/chromedriver.exe')
driver.get(url)# 스벅의 구 리스트 가져와서 검색시키기
# 스벅 구 리스트 만 뽑아오기
e_gu_list = df['gu'].unique()
e_gu_list# 구 검색 시키기
import time
from tqdm import tqdm_notebook
# 주소탭 클릭
driver.find_element(
By.CSS_SELECTOR,
'#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a'
).click()
# 검색창(searchTab) 클릭
searchTab = driver.find_element(By.CSS_SELECTOR, '#keyword').click()
# searchTab 클릭 + 기존 검색어 삭제 + e_gu_list 리스트 돌아가면서 입력 + 클릭 해야 할것 같음
# 반복문이 필요
# 검색어 입력 때마다 기존꺼 삭제할 수 있는 명령이 필요
# 수업 : keyword = driver.find_element(By.CSS_SELECTOR,'#query') / keyword.clear()
edi_list =[]
for gu in tqdm_notebook(e_gu_list):
#검색창 xpath
driver.find_element(By.XPATH, '//*[@id="keyword"]')
#기존 검색 삭제
driver.find_element(By.XPATH, '//*[@id="keyword"]').clear()
#e_gu_list 하나씩 넣기
driver.find_element_by_xpath('//*[@id="keyword"]').send_keys('서울 {}'.format(gu))
# 검색탭 클릭
driver.find_element_by_xpath('//*[@id="keyword_div"]/form/button').click()
# bs4로 데이터 읽기
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
contents = soup.select('#placesList li')
for idx in contents:
name = idx.select_one('dt').text
address = idx.select_one('dd').text
edi_list.append({
'brand' : '이디야',
'gu' : gu,
'name' : name,
'address' : address
})
df_ediya = pd.DataFrame(edi_list)
df_ediya
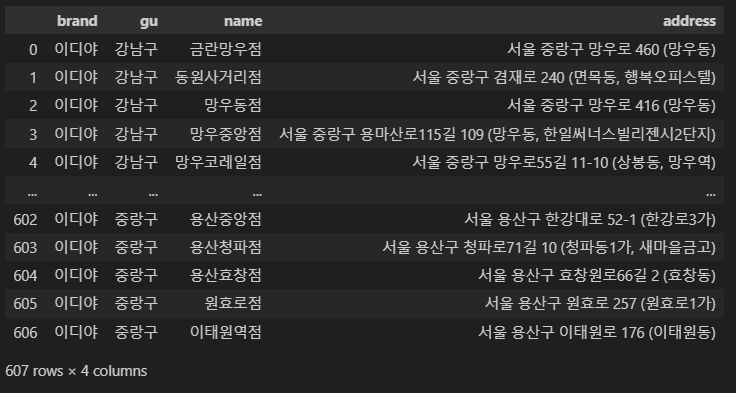
ediya = pd.DataFrame(df_ediya)
ediya.to_csv('[DS]eda1_edi_location.csv', index = False, encoding='utf-8') driver.quit()3.번
문제1과2의결과를가지고이제이디야커피는스타벅스커피매장근처에있는지를분석해보세요.
이과정은여러분의몫입니다.
예를들어모든커피매장의주소에서위도/경도정보를가져와서물리적인거리를측정하려고노력하는것도있을수
있겠죠.혹은도로명주소를가지고단순히유추하는방법도,또혹은folium으로시각화한후육안으로확인하는
방법도있습니다.
방법에는정답이없습니다.
여러분들이수행해야할미션은이디야커피는과연스타벅스커피주변에위치해있는가를검증하는것입니다.
같은데이터를놓고판단하는사람에따라그분석결과는다를수있습니다.그것도상관없습니다.
여러분의분석결과(예를들어이디야는스타벅스매장근처에위치한것이전략적이라고볼수없다)는여러분만의
논리적근거가있으면됩니다.
그래서그렇게분석한결과를여러분의jupyternotebook에markdown으로설명해두세요.
import pandas as pd
# from glob import glob, 엑셀로 안함
# 두 데이터 불러오기
df_sta = pd.read_csv('[DS]eda1_sta_location.csv', encoding='utf-8')
df_edi = pd.read_csv('[DS]eda1_edi_location.csv', encoding='utf-8')# 브랜드 컬럼 추가 + 단일 자료
df_sta['brand'] = '스타벅스'
df_sta.columns = ['브랜드', '구', '지점명', '주소']
df_edi['brand'] = '이디야'
df_edi.columns = ['브랜드', '구', '지점명', '주소']
#합치고
df_list = pd.concat([df_sta, df_edi])
#인덱스 초기화(리셋)의 중요함을 깨달음!
#인덱스 초기화를 하지 않는 경우, folium 시각화에서 이디야만 marking됨.
df_list = df_list.reset_index(drop = True)
df_list
import folium
import googlemaps
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
gmaps_key = 'AIzaSyALyv5xMRzF_RJUIeJ84qh25GgNWoIJ8LM'
gmaps = googlemaps.Client(key = gmaps_key)# 경도/위도 추가
# Location values cannot contain NaNs 오류...
# 해결을 위해 주소 없는 값들 print
for idx, rows in df_list.iterrows():
tmp = gmaps.geocode(rows['주소'], language = 'ko')
if tmp:
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
df_list.loc[idx, '위도'] = lat
df_list.loc[idx, '경도'] = lng
else:
print(idx, rows['주소'])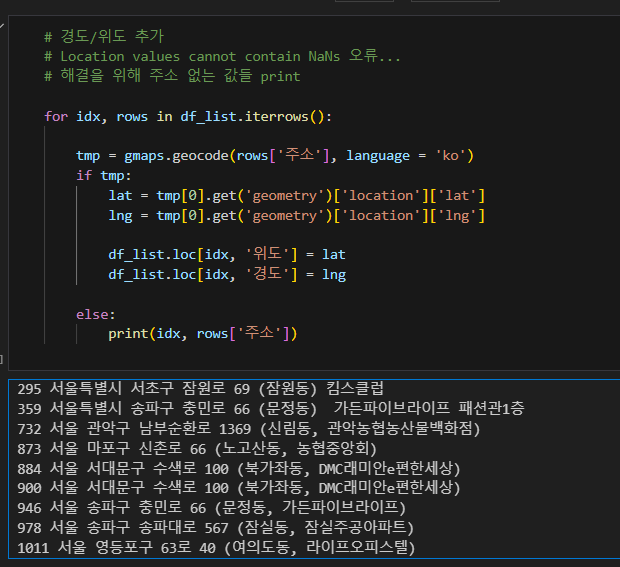
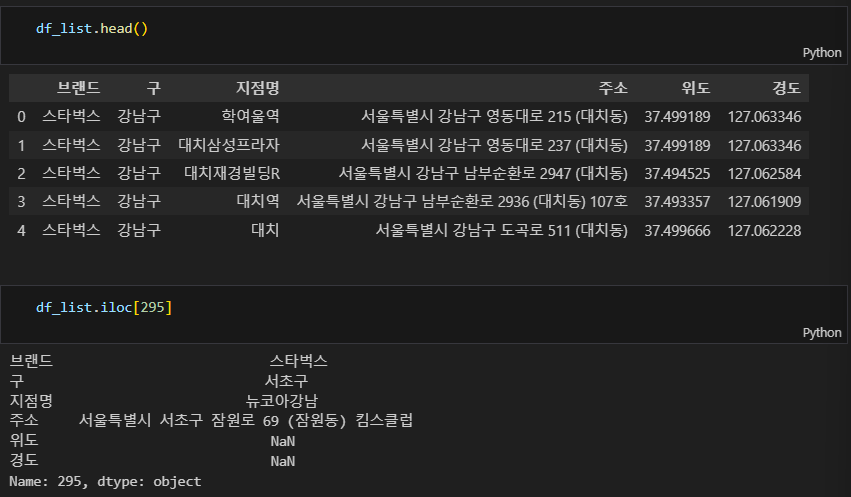
# 주소 없는 값들 수기 입력
# nan 값도 채워줘야 함!
# 295 서울특별시 서초구 잠원로 69 (잠원동) 킴스클럽
df_list.loc[295, '위도'] = 37.5096
df_list.loc[295, '경도'] = 127.0077
# 359 서울특별시 송파구 충민로 66 (문정동) 가든파이브라이프 패션관1층
df_list.loc[359, '위도'] = 37.4777
df_list.loc[359, '경도'] = 127.1250
#732 서울 관악구 남부순환로 1369 (신림동, 관악농협농산물백화점)
df_list.loc[732, '위도'] = 37.4801
df_list.loc[732, '경도'] = 127.9029
# 873 서울 마포구 신촌로 66 (노고산동, 농협중앙회)
df_list.loc[873, '위도'] = 37.5560
df_list.loc[873, '경도'] = 126.9331
# 884 서울 서대문구 수색로 100 (북가좌동, DMC래미안e편한세상)
df_list.loc[884, '위도'] = 37.5725
df_list.loc[884, '경도'] = 126.9104
# 900 서울 서대문구 수색로 100 (북가좌동, DMC래미안e편한세상)
df_list.loc[900, '위도'] = 37.5725
df_list.loc[900, '경도'] = 126.9104
# 920 서울 서초구 서초대로 108 (방배동, 삼보빌딩)
df_list.loc[920, '위도'] = 37.4874
df_list.loc[920, '경도'] = 126.9943
# 946 서울 송파구 충민로 66 (문정동, 가든파이브라이프)
df_list.loc[946, '위도'] = 37.477535
df_list.loc[946, '경도'] = 127.125089
# 978 서울 송파구 송파대로 567 (잠실동, 잠실주공아파트)
df_list.loc[978, '위도'] = 37.5152
df_list.loc[978, '경도'] = 127.0949
# 1011 서울 영등포구 63로 40 (여의도동, 라이프오피스텔)
df_list.loc[1011, '위도'] = 37.5198
df_list.loc[1011, '경도'] = 126.9389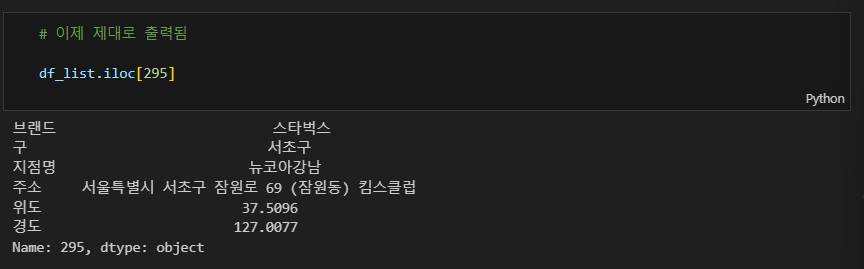
- 1) folium marker
- 용산구의 경우 스타벅스 밀집이 높음에도 이디야가 위치하고 있지 않음
- 영등포의 경우 이디야가 더 많이 위치하고 있음
- 대략적인 매장수만 확인됨
import json
geo_path = "../data/02. skorea_municipalities_geo_simple.json"
geo_str = json.load(open(geo_path, encoding="utf-8"))
cafe_map = folium.Map(location=[37.5502, 126.982], zoom_start=11)
for idx, row in df_list.iterrows():
if row['브랜드'] == '스타벅스':
folium.Marker(
location=[row["위도"], row["경도"]],
tooltip=row["브랜드"],
icon=folium.Icon(
icon="star",
color="green",
)
).add_to(cafe_map)
else:
folium.Marker(
location = [row["위도"], row["경도"]],
tooltip = row["브랜드"],
icon = folium.Icon(
icon = "coffee",
color = "blue",
icon_color = "white",
prefix = "fa"
)
).add_to(cafe_map)
cafe_map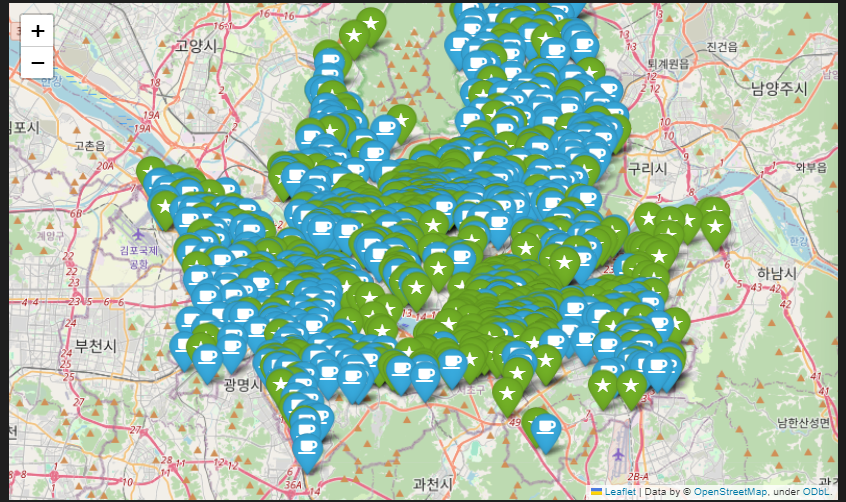
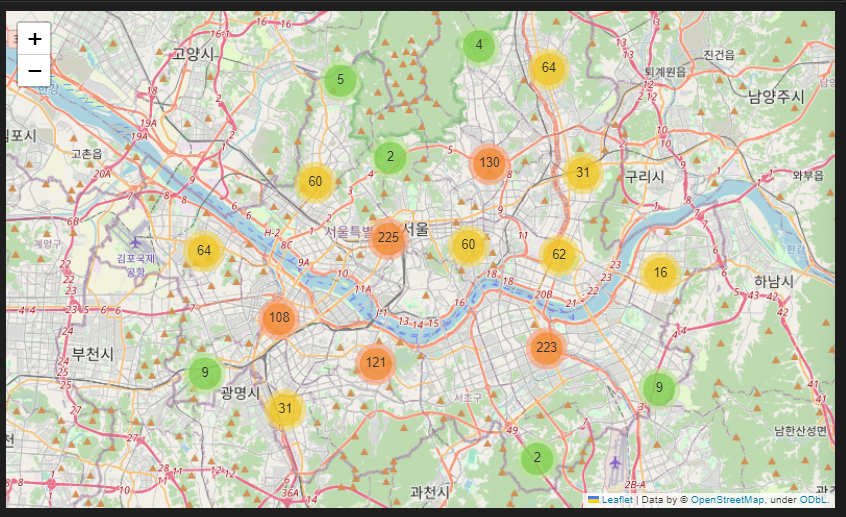
- 2) folium markercluster
- 지역별로 어디에 많이 밀집되어 있는지 확인하고 싶어 활용함
from folium.plugins import MarkerCluster
lib_map = folium.Map(location=[37.5502, 126.982],zoom_start=11)
# Add points to the map
mc=MarkerCluster()
# _ : 인덱스값을 저장.변수명(이긴 한데 이 프로그램에선 사용하진 않음). 변수명을 i, a 등등으로 사용 가능
# row : 한 개의 레코드 값
# library.iterrows() : library 데이터 중 한개의 레코드씩 조회.
for _, row in df_list.iterrows() :
mc.add_child(
folium.Marker(location = [row['위도'],row['경도']],popup=row['브랜드'],
tooltip = row['브랜드']
)
)
lib_map.add_child(mc)
3) barplot
- 구/브랜드 별로 어떻게 분포되어 있는지 확인이 필요
cafe_cnt = df_list.groupby(['구', '브랜드'])['지점명'].count().reset_index(name = '매장수')
cafe_cnt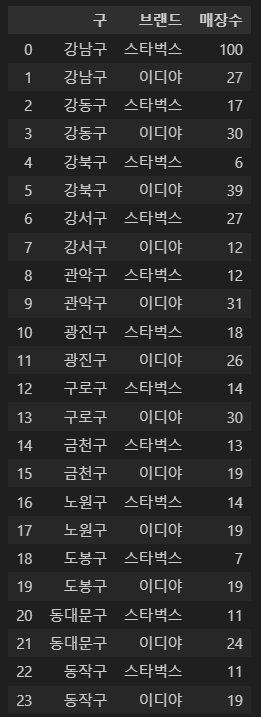
plt.figure(figsize=(20,10))
sns.barplot(data=cafe_cnt, x='구', y='매장수', hue='브랜드', palette="Set1")
plt.xlabel("서울시 구")
plt.show()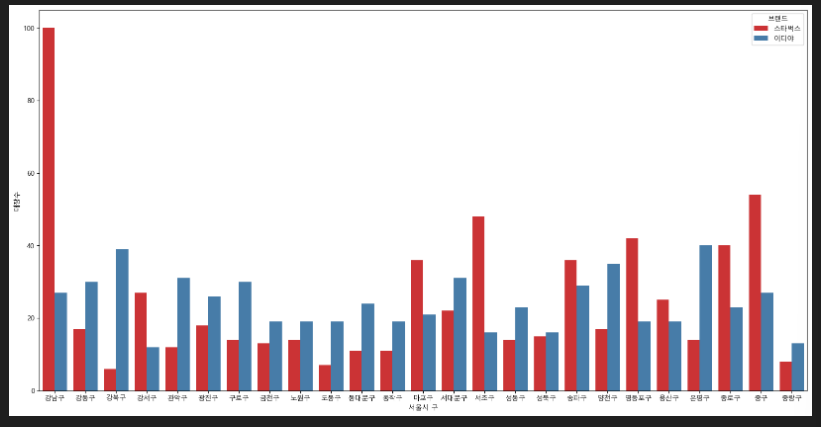
결론

제로베이스 데이터 스쿨

비전공자의 데이터 공부법