유가분석 'selenium'
- Beautiful Soup 만으로 해결할 수 없는 것s
- 접근할 웹 주소를 알 수 없을 때
- 자바스크립트를 사용하는 웹페이지의 경우
- 웹 브라우저로 접근하지 않으면 안될 때
- 해결방안 >
Selenium
- 웹브라우저를 원격으로 조작하는 도구
자동으로 URL을 열고 클릭 등이 가능
스크롤, 문자의 입력, 화면 캡쳐 등등
설치
Selenium은
- Python 모듈도 설치하고 크롬 드라이버도 받아야 한다.
- Window :
conda install selenium - Mac(m1) :
pip install selenium - Chrome 버전에 맞춰 설치할 것
- Selenium 설치
!pip install selenium- chrome 드라이버 설치
from selenium import webdriver
driver = webdriver.Chrome('../driver/chromedriver.exe')
driver.get('https://www.naver.com')코드를 입력하세요기초
- 화면을 최대 크기로 설정하는 방법
- 함수 명령어로, ()괄호 까지 넣어줘야 동작
driver.maximize_window()- 화면 최소 크기 설정
driver.minimize_window()- 화면크기 설정
driver.set_window_size(600,600)- 새로고침
driver.refresh()- 뒤로 가기
driver.back()- 앞으로 가기
driver.forward()- 클릭하기
- 클릭을 하기 위한 tag값 이 필요
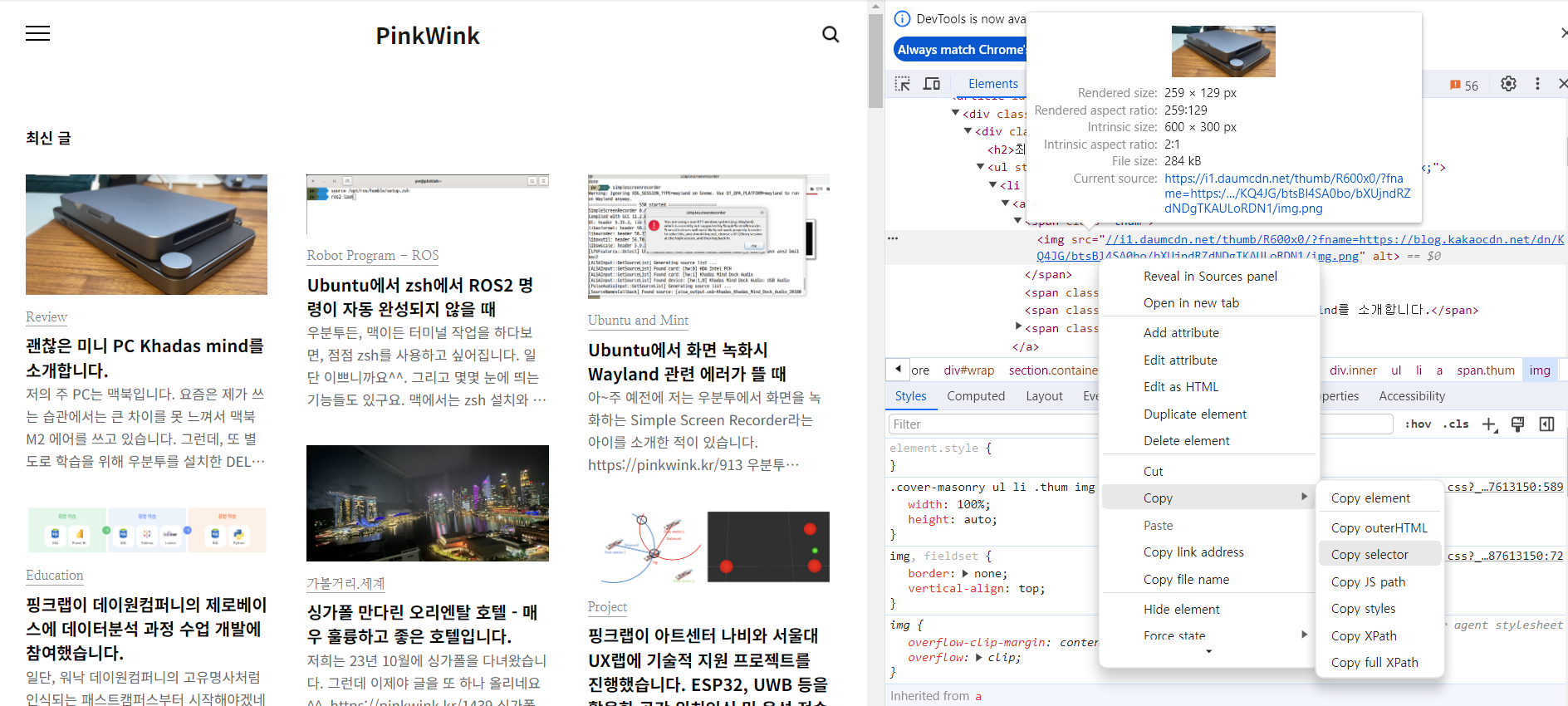
from selenium.webdriver.common.by import By
first_content = driver.find_element(
By.CSS_SELECTOR,
'#content > div.cover-masonry > div > ul > li:nth-child(1) > a > span.thum > img'
# id/ 바로 밑에/div태그를 가진/class 이름이 cover-masonry/바로 밑에/div태그가 있고/ul태그가 있고
# 바로 밑에/ li가 가진 콘텐츠 중 nth-child 첫번째 (내가 클릭하고 싶었던 콘텐츠)
)
first_content.click()- 새로운 탭 생성
driver.execute_script('window.open("https://www.naver.com")')
#드라이버에서 [자바스크립트 execute_script 기능]을 이용- 탭 이동
driver.switch_to.window(driver.window_handles[0])
# 다루고 싶은 탭 번호를 인덱스로 설정- 탭 닫기
- 하나씩 닫는 명령
driver.close()- 창 전체 종료
driver.quit()- 화면 스크롤 길이 확인
- 스크롤 가능한 길이(높이) 확인
- 자바 스크립트 명령어 사용
driver.execute_script('return document.body.scrollHeight')
5605- 하단 이동
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# 명령어(0부터 가장 아래까지)- 화면 스크린샷 저장
driver.save_screenshot('./last_height.png')
True- 상단 이동
driver.execute_script('window.scrollTo(0, 0)')
- 특정 태그 지점 까지 이동
from selenium.webdriver import ActionChains
some_tag = driver.find_element(By.CSS_SELECTOR, '#content > div:nth-child(5) > div > ul > li:nth-child(1) > a > figure > img')
action = ActionChains(driver)
- ActionChains 를 이용해서 현재 사용 중인 driver를 제어 하겠다
action.move_to_element(some_tag).perform()
#위 기능을 action 변수로 가져와서, move_to_element(내가 지정한 곳 = some_tag으로 이동) 기능을 이용해. 작동
검색어 입력
CSS.SELECTOR
우클릭 > copy > copy selector
- import webdriver
- selenium을 이용해 Chrome을 제어하기 위한 class
from selenium import webdriver- 태그를 선택하기 위해서 불러오는 class
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome(executable_path='../driver/Chromedriver.exe')
driver.get('https://www.naver.com')- 네이버 검색창 태그
keyword = driver.find_element(By.CSS_SELECTOR,'#query')
# 검색어 입력 때마다 기존꺼 삭제할 수 있는 명령
keyword.clear()
#파이썬을 검색할 수 있게 명령
keyword.send_keys('파이썬')
Selection deletedXPATH
- 우클릭 > copy > copy xpath
- // : 최상위
- : 자손 태그 (하위, 바로밑 보다 하나 밑~)
- / : 자식 태그 (바로 밑)
- div[1] : div 중에 1번째 태그
driver.find_element(By.XPATH, '//*[@id="query"]').send_keys('xpath')
driver.find_element(By.XPATH, '//*[@id="sform"]/fieldset/button').click()
driver.quit()검색 입력 연습
# selenium을 이용해 Chrome을 제어하기 위한 class
from selenium import webdriver
# 태그를 선택하기 위해서 불러오는 class
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome(executable_path='../driver/chromedriver.exe')
driver.get('https://pinkwink.kr')- 돋보기 버튼 선택
# 동적 검색인 경우 아래와 같이 진행해야 함
from selenium.webdriver import ActionChains
search_tag = driver.find_element(By.CSS_SELECTOR, '.search')
action = ActionChains(driver)
action.click(search_tag)
action.perform()- 검색어 입력
driver.find_element(By.CSS_SELECTOR, '#header > div.search.on > input[type=text]').send_keys('딥러닝')- 검색 버튼 클릭
driver.find_element(By.CSS_SELECTOR, '#header > div.search.on > button').click()selenium + BeautifulSoup
- selenium 을 이용해 이동하고
- BeautifulSoup 을 통해 데이터를 가져 옴
- 현재 화면의 html 코드 가져오기
driver.page_sourcefrom bs4 import BeautifulSoup
req = driver.page_source
# 가져오려는 html 코드를 담음
soup = BeautifulSoup(req, 'html.parser')
#코드, 읽어오는 옵션▲ BeautifulSoup 으로 읽어와서
▼ BeautifulSoup 을 이용해서 원하는 데이터를 뽑아올 수 있도록 제어
soup.select('.post-item')contesnts = soup.select('.post-item')
len(contesnts)contesnts[1]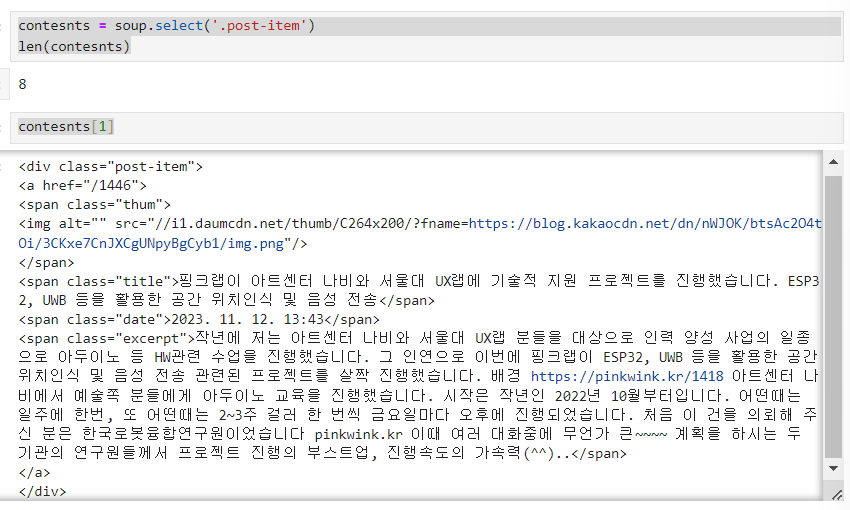
미니 프로젝트는 다음 자료에서...
제로베이스 데이터 스쿨

비전공자의 데이터 공부법