SVM
- 서포트 벡터 머신
- 주어진 데이터의 카테고리를 판단하는 이진 선형 분류 모델
- 적절한 Decision Boundary는
- 데이터를 정확하게 나누면서
- 서포트 벡터와의 거리가 커야함 = Robustness가 더 크다.
- outlier는 적절한 선에서 무시한다.
Kernel Trick
low dimensional space를 high dimensional space로 매핑해주는 작업
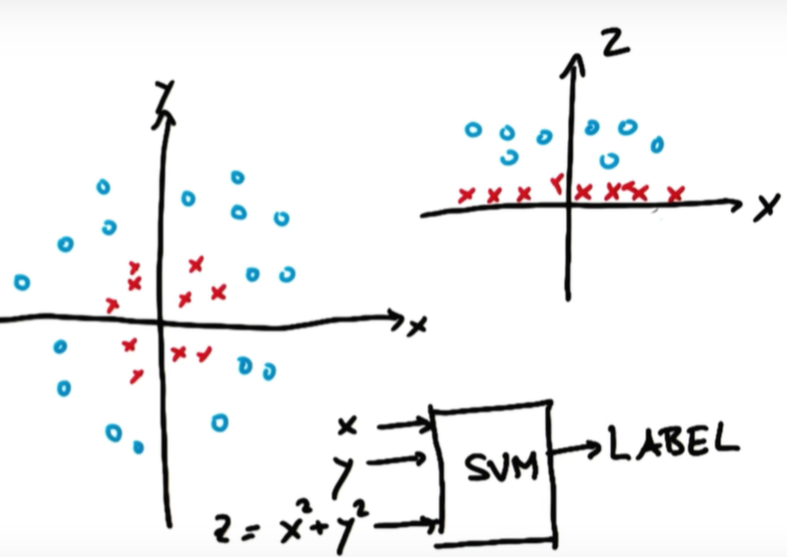
출처: Udacity, 머신러닝 - 2. 서포트 벡터 머신 (SVM) 개념
왼쪽 그림과 같이 두 카테고리로 나눌 수 있는 linear line이 없을 경우 오른쪽과 같이 차원을 바꿔 decision boundary를 그리는 방법.
여기서 z = x^2 + y^2 (원점으로부터 떨어진 거리의 제곱)
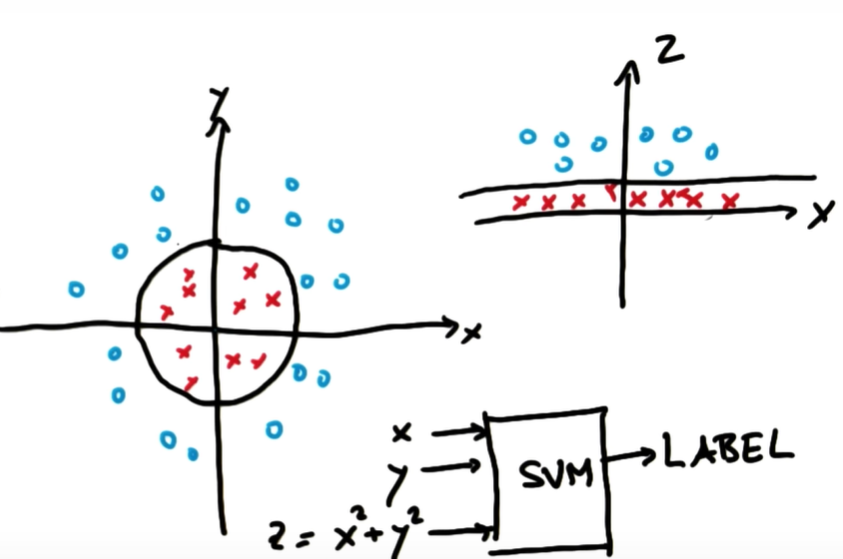
출처: Udacity, 머신러닝 - 2. 서포트 벡터 머신 (SVM) 개념
decision boundary는 차원이 달라서 구분선 모양만 달라진 것일 뿐, 같음
sklearn.SVM
- kernel: decision boundary의 모양을 결정. 선형일지 다항식형일지 정할 수 있음
- 종류: linear, polynomial, sigmoid, rbf 등
- C: training point를 얼마나 정확히 구분하느냐. C가 크면 decision boundary가 굴곡이 많이 생기고 C가 작으면 직선에 가까움.
- Gamma: 하나의 training point의 거리가 얼마나 영향을 주는지? (defines how far the influence of a single training point reaches)
- Gamma 값이 크면 reach가 좁음 = reach가 큰, 즉 거리가 먼 포인트는 decision boundary에 영향을 주지 않음. (아래 사진의 하늘색 원 안에 들어간 포인트들) = 굴곡 진다.

출처: Udacity, 머신러닝 - 2. 서포트 벡터 머신 (SVM) 개념 - 반대로 Gamma값이 작으면 대부분의 포인트가 영향을 준다. = 직선에 가깝다.
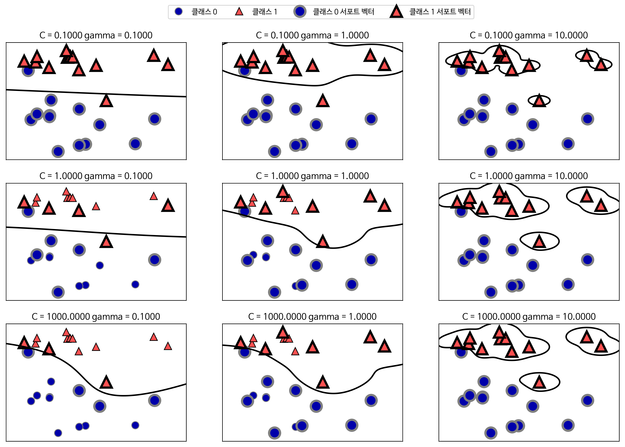
출처: tensorflow.blog
주의
- training time이 길어 사이즈가 큰 데이터 셋을 이용할 경우 적절하지 않음
- 노이즈가 많은 데이터 셋을 이용할 경우 오버피팅이 일어날 가능성이 있음 => 이땐 나이브 베이즈를 쓰는 것이 더 좋을 수 있다.
SGD
- Stochastic Gradient Descent
- 경사하강법(손실 함수의 global minimum을 찾기 위해 일정 크기만큼 기울기의 반대 방향으로 이동하는 방법)의 일종, 선형 분류 모델
- 전체 데이터(Batch) 대신 일부(Mini-Batch)만 사용해 계산 => Batch gradient descent에 비해 큰 데이터를 학습 시킬 때 효과적
- 기존 경사하강법에 비해 정확도는 떨어질 가능성이 있으나 계산 속도가 빠름
- 여러 번 반복할 경우 전체 데이터를 사용했을 때의 결과로 수렴
- local minimum에 빠지지 않고 global minimum을 찾을 가능성이 높음
- 계산 값을 기준으로 0보다 작으면 -1, 0보다 크면 1로 분류한다.
다른 모델과의 비교
| SGD | LR | SVM | |
|---|---|---|---|
| 손실함수 최소값의 계산 여부 | O | X | - |
| RAM에 기록 저장이 필요 | X | O | O |
-
LR은 직접 계산 불가, SGD는 직접 계산 가능 => 손실 함수를 최소값에 가깝게 조정 가능
-
RAM에 계속 기록을 저장하지 않아도 수행 가능
sklearn.SGDclassifier
- loss: 손실함수
- hinge: SVM 방식 / log: Logistic Regression
- max_iter: 반복 횟수, 너무 크면 과적합
- tol: loss 값을 정함. 이 값에 도달할 때까지만 반복.
- penalty: l2 or l1 (regularization에 사용)
- alpha: 값이 클수록 강력한 regularization 설정
- learning rate: 학습 속도
Logistic Regression
- 회귀, 분류 모두 사용 가능
- 회귀: 종속변수가 특정 범위 내에만 있을 경우
- 독립변수가 연속형, 종속변수가 범주형인 경우
- 시그모이드 함수를 이용해 결과값이 0 또는 1만 나올 수 있도록 조정
참고 및 출처
머신러닝 - 2. 서포트 벡터 머신 (SVM) 개념
[ML] 사이킷런 클래스 SGDClassifier: 선형분류
6.1 로지스틱 회귀분석
로지스틱 회귀분석(Logistic Regression) 설명

🐬 파이썬 / 인공지능 / 머신러닝