Decision Tree
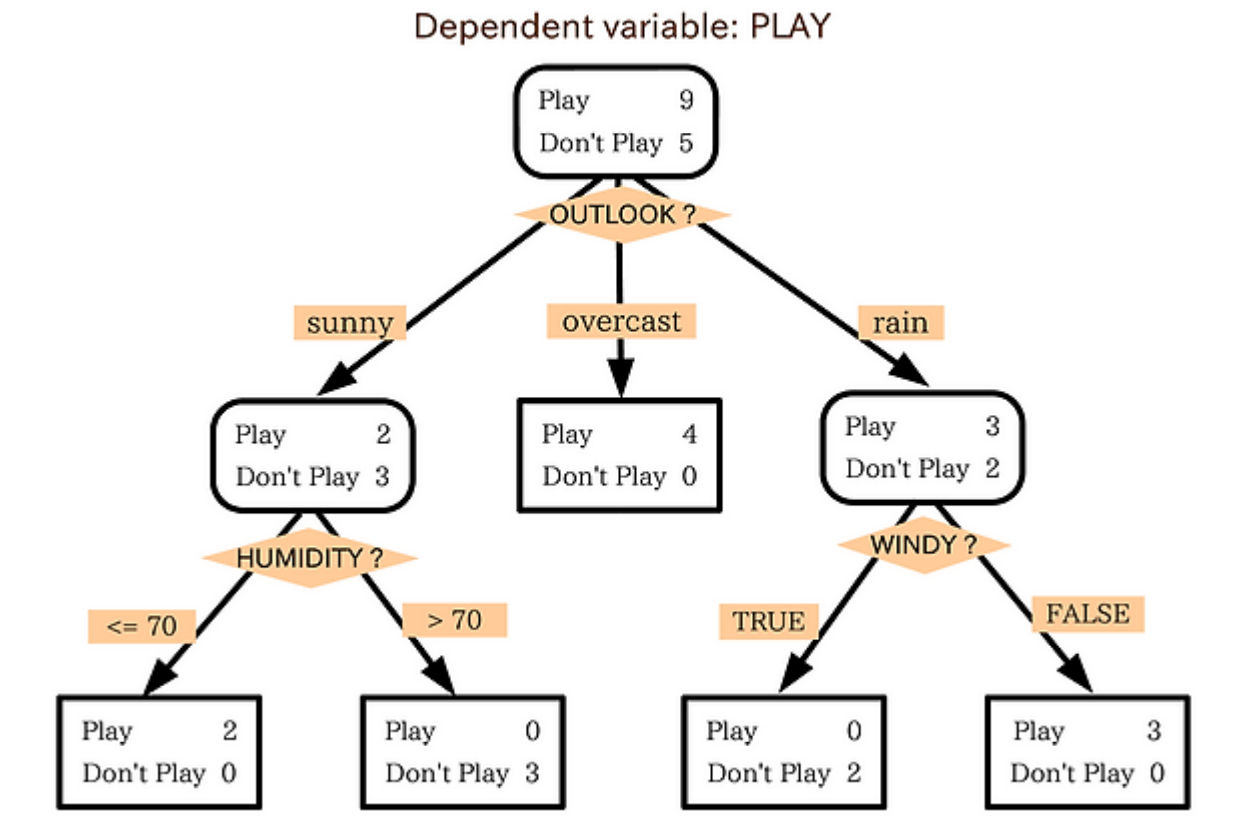
이진분류 문제
정리
- 데이터를 분석하여 데이터 속에 존재하는 패턴을 예측 가능한 규칙들의 조합으로 나타내는 방법
- 분류, 회귀 모두 가능: 범주형, 연속형 수치 모두 예측할 수 있음
용어
Root node: 처음 시작하는 노드
Intermediate node: 첫 노드와 끝 노드 사이의 모든 노드
Terminal node: 마지막 노드
Terminal node 간 교집합이 없도록 해야함
학습 방법
- information gain: homogeneity 증가, impurity를 감소 시키는 방향으로 학습
- 지표
- Entropy
- Gini index
- misclassification error: 미분이 되지 않아 자주 쓰지 않음
- 지표
- Recursive Partitioning + Pruning
- Pruning: 과적합 방지를 위함 (오분류률이 오히려 올라가는 경우를 방지)
- Cost Fuction: 이것을 최소화하는 분기를 찾도록 학습됨
CC(T) = Err(T)+α×L(T)
- CC(T) = 의사결정나무의 비용 복잡도(=오류와 terminal node 수가 적은 단순한 모델일 수록 작은 값)
- ERR(T) = 검증데이터에 대한 오분류율
- L(T) = terminal node의 수(구조가 얼마나 복잡한가)
- Alpha = ERR(T)와 L(T)를 결합하는 가중치(사용자에 의해 부여됨, 보통 0.01~0.1의 값을 씀)
sklearn.DecisionTreeClassifier
| 파라미터 | 설명 |
|---|---|
| max_depth | 트리의 최대 깊이, 지정하지 않을 경우 모든 라벨이 같은 것만 있을 때까지, 즉 균일하게 분류할 때까지 분류 |
| max_leaf_nodes | 리프 노드의 최대 개수 |
| min_samples_split | 노드를 분할하기 위해 최소 몇 개의 데이터(=샘플 수)를 사용할 것인지. 과적합을 제어하는 데 사용. 샘플의 수가 지정 값에 도달하면 분할을 멈춤. 기본 값은 2 |
| min_samples_leaf | 리프 노드가 되기 위해 최소한 몇 개의 데이터(=샘플 수)가 필요한지. 과적합을 제어하는데 사용됨 분할 과정 중 리프 노드에서 데이터 수가 지정한 값에 도달하도록 조건을 설정해주는 것 |
| max_features | 최적의 분할을 위해 고려할 최대 Feature 개수 기본 값은 None으로 모든 Feature가 많은 경우 조절 필요 int형으로 지정할 경우: 대상 Feature의 개수 float형으로 지정할 경우: 전체 Feature 중 target feature의 비율 sqrt (또는 auto): 전체 Feature 수의 제곱근 만큼 설정 log: 전체 feature의 log2 만큼 설정 |
Random Forest
Bootstrap sampling을 사용하는 기존 배깅의 이점을 살리고 변수를 랜덤으로 선택하는 과정을 추가해 개별 나무 간의 상관성을 줄임으로써 예측력을 향상시킨 앙상블 모델
-
Bootstrap sampling: 하나의 데이터 셋으로 여러 개의 데이터 셋을 이용하는 효과를 보여준다. 분산을 낮출 수 있다.
- 배깅의 이점: bias를 유지하면서 분산을 낮춤
-
개별 나무 간의 상관성이 줄어들면 랜덤 포레스트의 Generalized Error 가 작아진다.
-
상관성을 낮추는 방법: 개별 나무를 분리하는 샘플을 랜덤으로 선택할 경우 개별 나무끼리 같아질 가능성이 줄어든다.

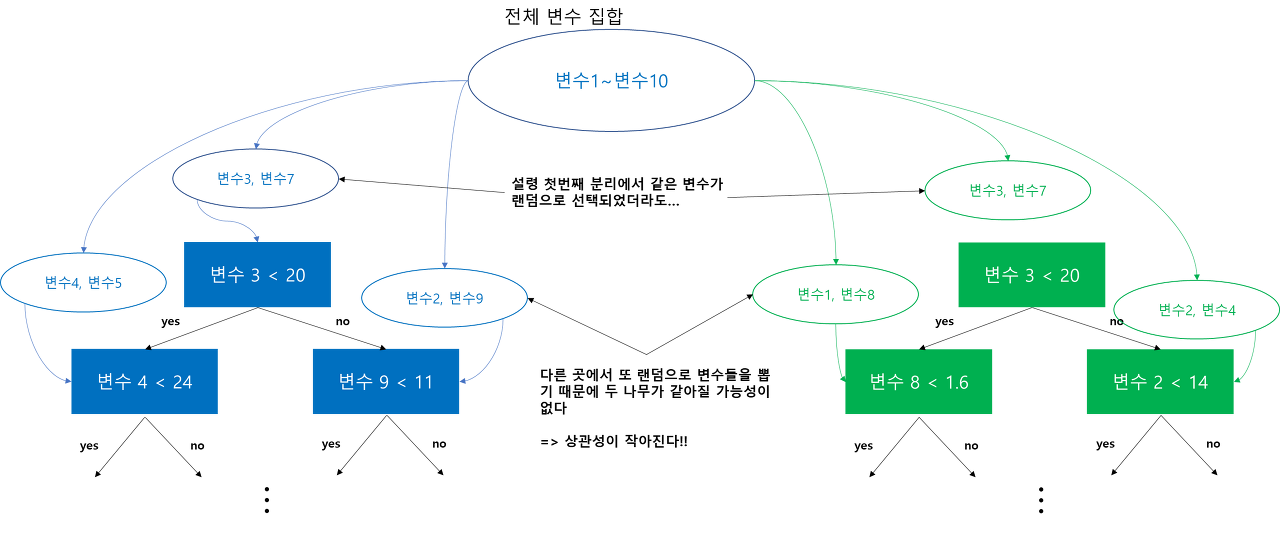
-
장단점
- 장점
- 출력 변수와 입력 변수 사이 복잡한 관계도 모델링 가능
- 예측력이 좋음
- Robust
- 단점
- 모형의 해석이 어려움: 출력 변수와 입력 변수 사이 관계를 해석하기 어렵다.
- 의사결정 나무 외에 다른 예측 모형 적용 불가
- 계산량, 학습에 소요되는 시간이 DT에 비해 많음.
sklearn.RandomForestClassifier
- 주요 파라미터는 DT와 같다.
| n_estimators | 모델에서 이용할 트리의 수(학습시 생성하는 트리의 수) |
|---|
정리
| 모델 | 특징 | 학습 방법 |
|---|---|---|
| Decision Tree | 분류, 회귀에 모두 사용 가능 | impurity를 감소시키는 방향으로 학습 |
| RandomForest | 배깅의 이점을 살림 | 샘플을 랜덤으로 추출해 나무 간 상관성을 줄이는 방식 |
출처 및 참고자료
의사결정 나무(Decision Tree)
[ML] 분류 - 결정 트리 (Decision Tree)
24. 랜덤 포레스트에 대해서 알아보자
Bootstrap Sampling 쉽게 이해하기
- variance를 잘 근사할 수 있다
- 복원 추출

🐬 파이썬 / 인공지능 / 머신러닝