타겟 데이터 분포 확인 및 조정
sns.kdeplot(y)
plt.show()y = np.log1p(y)
sns.kdeplot(y)
plt.show()| 원본 | 로그 변환 |
|---|---|
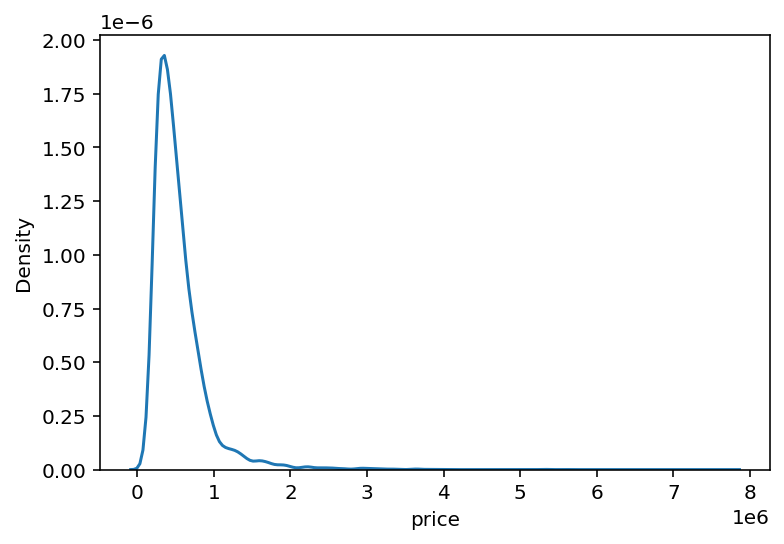 |  |
분포가 0과 1 사이에 밀집되어 있는 것을 볼 수 있음(왼쪽) 이를 조정하기 위해 log를 사용(오른쪽)
로그 변환
데이터 분포 변환 방법 중 하나. 설명 및 종속 변수가 정규분포가 유사할 경우 성능이 높아지기 때문에, 로그를 취하는 경우 분포가 정규 분포에 가깝게 바뀔 때 사용(로그 정규 분포, log-normal distribution)
- 국가 별 수출액
- 사람의 통증 정도
- 개별 주식의 가격 변동성 분석
평가 지표
def rmse(y_test, y_pred):
return np.sqrt(mean_squared_error(np.expm1(y_test), np.expm1(y_pred)))- RMSE: 평균 제곱근 오차, Root Mean Squared Error
- 회귀 모델의 성과 지표 중 하나
- 예측 모델에서 예측한 값과 실제 값 사이의 평균의 차이를 측정
- MSE와 비교했을 때 이상치에 덜 민감하다.
- MAE와 비교했을 때 오차에 대한 다른 가중치를 갖는다.
Gradient Boost
-
XGBoost
- 한 개의 예측 모델에 대한 error를 줄이는 방식인 boosting ansemble로 구현된 모델
- Extreme Gradient Boost: 기존 Gradient Tree Boosting 알고리즘에 과적합 방지를 위한 기법(필요 이상의 가지를 치는 것을 막아주는 식)이 추가된 지도 학습 알고리즘
- 병렬 학습이 지원되어 더 빠른 학습이 가능
-
LGBM
- Light Gradient Boost
- XGBoost의 학습 속도를 개선하기 위한 알고리즘
- Leaf wise: 층에 상관없이 가지를 뻗는 방식.
Level wise Leaf wise 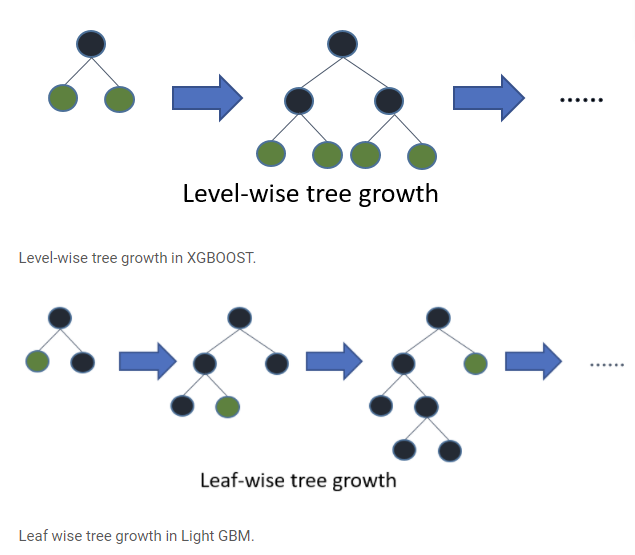
- 적은 메모리 사용 가능, 빠른 모델 생성, 상대적으로 높은 성능
- 과적합에 취약 => 데이터가 적은 경우 XGBoost가 낫다.
Grid 탐색
모델의 성능을 최대화하는 하이퍼 파라미터를 찾는 방법
참고 및 출처
빅데이터 탐색 - 데이터 전처리 - 변수 변환
04-3. 데이터 전처리
언제 MSE, MAE, RMSE를 사용하는가?
21. XGBoost에 대해서 알아보자
RandomForest, XGBoost, LGBM, CatBoost 뭐가 다를까?

🐬 파이썬 / 인공지능 / 머신러닝