데이터 분석&시각화
1.[파이썬] 2개 이상의 꺾은선그래프 + 범례

0. 사용할 라이브러리와 엑셀 파일 불러오기 1. 필요한 열과 행으로만 데이터프레임 재구성 2. 컬럼명 변경 3. 불필요한 행 삭제 4. 인덱스 값 변경 5. 꺾은선그래프 5. 컬럼 리스트 출력
2.[파이썬] 막대그래프 + 꺾은선그래프 + 범례
0. 미리 작업해 놓은 데이터프레임 1. 막대그래프 + 꺾은선그래프 2. 데이터프레임 리스트로 추출(딕셔너리로 변환 후 가져오기) 1. 각 행 값의 합계를 구한 후 데이터프레임으로 만들어 기존의 데이터프레임에 추가 ⭐ .sum()과 .drop()에서 axis=0과
3.[파이썬] 이중y축 꺾은선그래프 + 그래프에 텍스트 추가
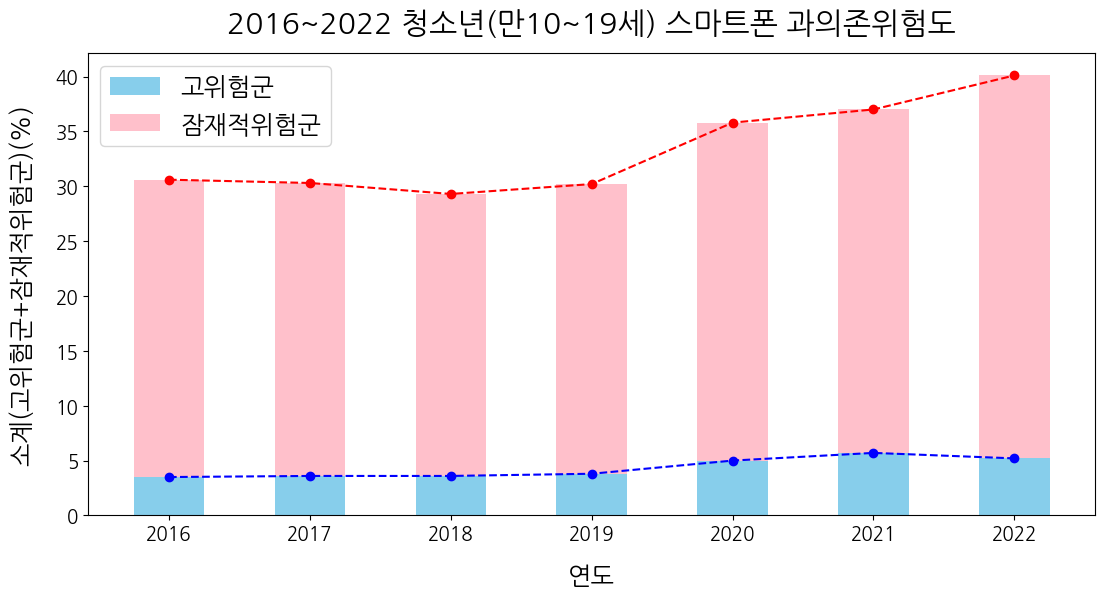
💡 내가 만들고자 하는 꺾은선그래프노션 0. 미리 작업해 놓은 데이터프레임 | | 죄종별 | 소계 | | --- | --- | --- | | 시점 | | | | 2011 | 계 | 86616 | | 2011 | 강력범죄 | 3209 | | 2011 | 폭력범
4.[파이썬] 그래프 y축값 간격 설정 2가지 방법
기본 그래프만약 y축 값을 10씩 증가하고 싶다면 위 코드에서 plt.yticks(fontsize=13.5) 대신 plt.yticks(np.arange(60,91,10), fontsize=13.5)를 작성하면 된다. 또한 import numpy as np도 추가해야 한
5.[파이썬] df.query() 주의사항(1) - \xa0

특정 조건에 맞는 데이터프레임만 출력하고 싶을 때는 df.query()를 사용하면 된다. 나는 데이터프레임 df2020에서 '항목'(컬럼명)이 '식당'인 데이터프레임을 출력하고 싶어 [사진 1-1]처럼 df.query()를 이용하여 작성했지만 아무것도 나오지 않았다.
6.[파이썬] df.query() 주의사항(2) - 컬럼명

이전 글에서는 df.query()을 사용해 조건에 맞는 데이터프레임을 출력하고자 할 때 df'컬럼'.values에 \\xa0이 포함되어 원하는 결과가 출력되지 않을 때의 해결방법에 대해 포스팅했다. df.query()의 주의사항은 한 가지 더 있는데 이것이 오늘 포스
7.[파이썬] 데이터프레임 - 가공, 파생변수, 그룹화 등

1. 특정 조건에 맞는 결과 출력 > 조건 → 항목이 '식당'이거나 '카페'이거나 '커피숍'인 데이터프레임 | | 시점 | 항목 | 15~19세 | 20대 | 30대 | 40대 | 50대 | 60대 | 70세 이상 | | --- | --- | --- | --- |