
💡내가 만들고자 하는 꺾은선그래프
0. 사용할 라이브러리와 엑셀 파일 불러오기
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
dfsm = pd.read_excel('/content/drive/MyDrive/데이터분석 레포트/11월 보고서/스마트폰_과의존위험군_2016to2022.xlsx')#오류 메시지 ➡️ /usr/local/lib/python3.10/dist-packages/openpyxl/styles/stylesheet.py:226: UserWarning: Workbook contains no default style, apply openpyxl's default warn("Workbook contains no default style, apply openpyxl's default")
import warnings
warnings.simplefilter("ignore")1. 필요한 열과 행으로만 데이터프레임 재구성
dfsm2 = dfsm.iloc[[2,4,5,6,7,8,9,10], [0,2,3,4,9]]
dfsm2| 시점 | 과의존위험군.1 | 과의존위험군.2 | 과의존위험군.3 | 과의존위험군.8 |
|---|---|---|---|---|
| 2 | 시점 | 유아동(만3~9세) | 청소년(만10~19세) | 성인(만20~59세) |
| 4 | 2016 | 17.9 | 30.6 | 16.1 |
| 5 | 2017 | 19.1 | 30.3 | 17.4 |
| 6 | 2018 | 20.7 | 29.3 | 18.1 |
| 7 | 2019 | 22.9 | 30.2 | 18.8 |
| 8 | 2020 | 27.3 | 35.8 | 22.2 |
| 9 | 2021 | 28.4 | 37 | 23.3 |
| 10 | 2022 | 26.7 | 40.1 | 22.8 |
2. 컬럼명 변경
dfsm2.columnsIndex(['시점', '과의존위험군.1', '과의존위험군.2', '과의존위험군.3', '과의존위험군.8'], dtype='object')
dfsm2.columns = ['시점', '유아동(만3~9세)','청소년(만10~19세)','성인(만20~59세)','60대(만60~69세)']
dfsm2| 시점 | 유아동(만3~9세) | 청소년(만10~19세) | 성인(만20~59세) | 60대(만60~69세) |
|---|---|---|---|---|
| 2 | 시점 | 유아동(만3~9세) | 청소년(만10~19세) | 성인(만20~59세) |
| 4 | 2016 | 17.9 | 30.6 | 16.1 |
| 5 | 2017 | 19.1 | 30.3 | 17.4 |
| 6 | 2018 | 20.7 | 29.3 | 18.1 |
| 7 | 2019 | 22.9 | 30.2 | 18.8 |
| 8 | 2020 | 27.3 | 35.8 | 22.2 |
| 9 | 2021 | 28.4 | 37 | 23.3 |
| 10 | 2022 | 26.7 | 40.1 | 22.8 |
3. 불필요한 행 삭제
#행 ➡️ axis = 0
#열 ➡️ axis = 1
#inplace = True ➡️ 원본 데이터프레임 덮어쓰기
dfsm2.drop([2], axis=0, inplace=True)
dfsm2| 시점 | 유아동(만3~9세) | 청소년(만10~19세) | 성인(만20~59세) | 60대(만60~69세) |
|---|---|---|---|---|
| 4 | 2016 | 17.9 | 30.6 | 16.1 |
| 5 | 2017 | 19.1 | 30.3 | 17.4 |
| 6 | 2018 | 20.7 | 29.3 | 18.1 |
| 7 | 2019 | 22.9 | 30.2 | 18.8 |
| 8 | 2020 | 27.3 | 35.8 | 22.2 |
| 9 | 2021 | 28.4 | 37 | 23.3 |
| 10 | 2022 | 26.7 | 40.1 | 22.8 |
➕같이 보면 좋을 자료 ➡️ inplace = True 작성 유무
4. 인덱스 값 변경
dfsm2 = dfsm2.set_index("시점")
dfsm2| 유아동(만3~9세) | 청소년(만10~19세) | 성인(만20~59세) | 60대(만60~69세) |
|---|---|---|---|
| 시점 | |||
| 2016 | 17.9 | 30.6 | 16.1 |
| 2017 | 19.1 | 30.3 | 17.4 |
| 2018 | 20.7 | 29.3 | 18.1 |
| 2019 | 22.9 | 30.2 | 18.8 |
| 2020 | 27.3 | 35.8 | 22.2 |
| 2021 | 28.4 | 37 | 23.3 |
| 2022 | 26.7 | 40.1 | 22.8 |
5. 꺾은선그래프
plt.figure(figsize=(12,5))
plt.plot(dfsm2, marker='o')
plt.xlabel('연도', labelpad=15) #labelpad: 여백 크기
plt.xticks(fontsize=13)
plt.ylabel('과의존위험도(%)', labelpad=15) #labelpad: 여백 크기
plt.yticks(fontsize=13)
plt.title('연령대별 스마트폰 과의존위험도(2016~2022)', pad=15) #pad: 여백 크기
plt.legend()
plt.show()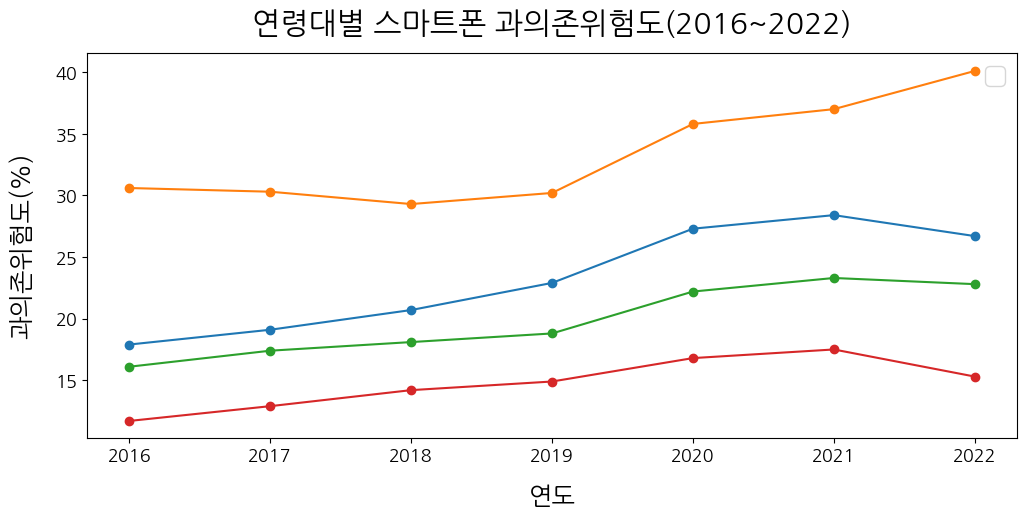
😭 어려웠던 점
데이터프레임 dfsm2의 값을 기반으로 그래프를 만들었기 때문에 plt.legend()를 작성하면 알아서 범례가 나올 줄 알았다. 그런데 괄호 안에 아무것도 적지 않았기 때문에 빈칸으로 된 범례 네모박스만 생성되었다. '어떻게 해야 정상적으로 출력이 될까'를 엄청 고민했다. 이것저것 해보고 오랜시간 고민한 결과 범례와 컬럼명이 같다라는 사실을 알게되었다. 컬럼 리스트를 어떤 변수에 대입해 plt.legend()에 넣으면 되지 않을까? 한번 시도해보았다.
5. 컬럼 리스트 출력
dfsm2_col = dfsm2.columns.to_list()
dfsm2_col #['유아동(만3~9세)', '청소년(만10~19세)', '성인(만20~59세)', '60대(만60~69세)']6. 꺾은선그래프(수정한 코드만, 나머지는 동일)
plt.plot(dfsm2, marker='o', label=dfsm2_col)
plt.legend(fontsize=12, loc='upper left')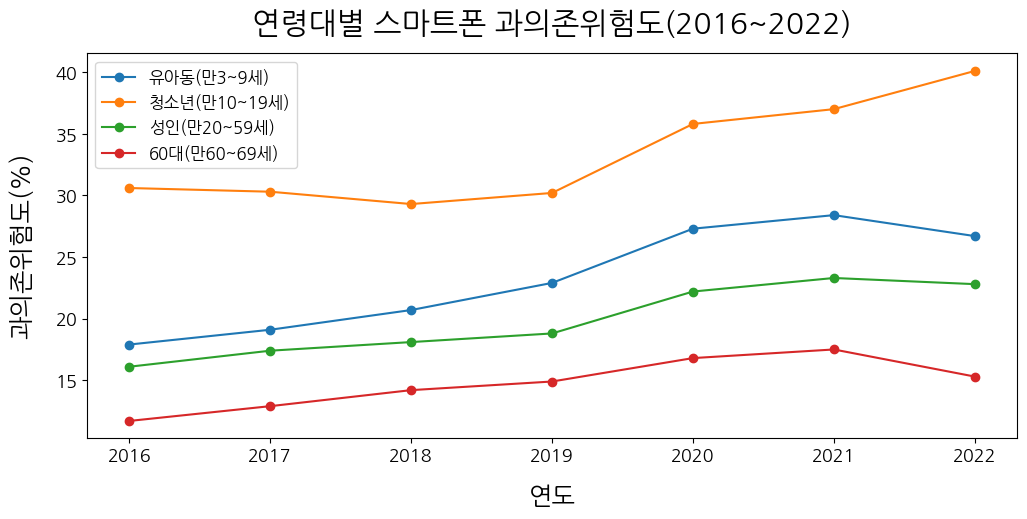
💡떠오른 아이디어
이 게시물을 작성하다가 갑자기 한 아이디어가 떠올랐다. 굳이 컬럼 리스트를 생성하지 말고 dfsm2.columns를 대신 사용하면 작성할 코드 양이 더 줄어들지 않을까? 왜냐하면 위에서 컬럼명을 변경하려고 dfsm2.columns를 불러내면 리스트(['시점', '과의존위험군.1', '과의존위험군.2', '과의존위험군.3', '과의존위험군.8'])로 결과값이 출력되었기 때문이다.
5. 꺾은선그래프(수정한 코드만, 나머지는 동일)
plt.plot(dfsm2, marker='o', label=dfsm2.columns)
😮 새롭게 알아낸 점
동일한 결과가 나온다!!!

은서는 오늘도 개발 중💻
제가 수행평가를 하는데, 위에 처럼하는데도 잘 안되는데 혹시 "C:\Users\User\Downloads\CO2 CH4 기체량.xlsx" 파일을 사용해서 만들어 주실 수 있나요 아니면 방법이라도
아 그 엑셀에 행 두 개 이름을 제가 바꿔놨는데 그거는 4번 행은 CO2고 5번 행은 CH4에요