
1. 문제 발생
특정 조건에 맞는 데이터프레임만 출력하고 싶을 때는 df.query()를 사용하면 된다. 나는 데이터프레임 df2020에서 '항목'(컬럼명)이 '식당'인 데이터프레임을 출력하고 싶어 [사진 1-1]처럼 df.query()를 이용하여 작성했지만 아무것도 나오지 않았다.
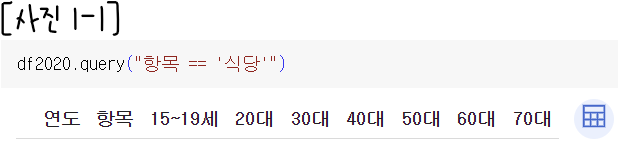
그러면 df2020의 '항목'에 '식당'이 없는 것 아니냐는 합리적 의심이 들 수도 있다. 하지만 [사진 1-2]에서 확인할 수 있듯이 전혀 아니다.
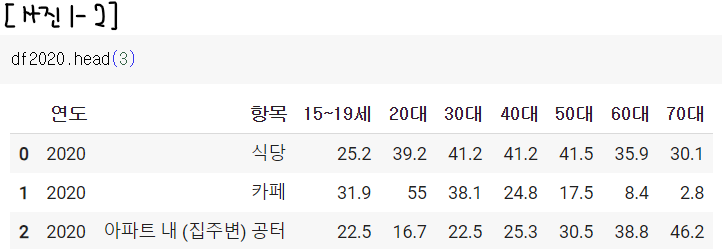
그다음에는 df.query()가 한국어를 지원하지 않나? 라는 생각이 들었지만 검색해 본 결과 전혀 아니었다. 그냥 나만 안 되는 거였다....
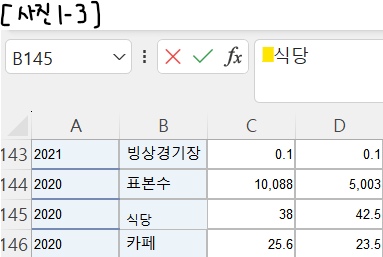
그러나 바로 포기할 내가 아니다. 이것저것 고민하다 '애초에 처음부터 그러니까 엑셀에서부터 뭔가 잘못된 것이 아닐까?' 라는 결론이 나왔다. [사진 1-3]을 보면 B145셀에는 '식당'이 적혀 있는 것이 아니라 ' 식당'이 적혀 있다. 이 띄어쓰기를 삭제하면 정상적으로 출력이 될 것 같은 느낌이 들었다.
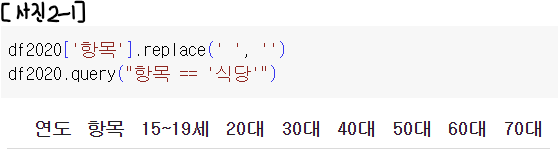
2. 공백 제거
공백 제거는 replace()를 활용하여 replace(' ', '')로 작성하면 된다.
어라 근데 왜 안 될까...?
3. \xa0 발견
설마 공백이 아닌 다른 불순물(?)이 value값에 있는 것인가? 하고 value값을 확인(특정 컬럼의 value값을 확인할 때는 df['컬럼명'].values를 실행하면 됨)해보니 \xa0가 있었다. 결론은 공백이 아닌 \xa0이 있어서 df.query()가 작동되지 않았던 것이다.

\xa0를 ''로 대체하면 되기때문에 replace("\xa0", '')를 활용하면 된다. 다만 나는 바꿀 게 여러 개이기 때문에 for문 안에 replace()를 작성했다.
⭐ 4. 해결방법
for i in range(len(df2020['항목'])):
a = df2020['항목'].values[i]
b = a.replace("\xa0", "")
df2020['항목'].values[i] = b
df2020['항목'].values[코드 설명]
| 행 | 설명 |
|---|---|
| 1행 | df2020['항목']에 있는 모든 value값에는 \xa0이 있기 때문에 범위(range)는 0에서 df2020['항목']의 개수만큼 즉 0 ~len(df2020['항목'])이다. |
| -- | -- |
| 2행 | [사진 3-1]을 보면 df2020['항목'].values는 배열로 되어 있다. 그래서 df2020['항목'].values[0]을 출력하면 '식당'이 출력된다. |
| -- | -- |
| 3행 | b는 replace()를 활용해 a(df2020['항목'].values의 i번째 값)에 있는 \xa0을 ""으로 대체해 대입한 값이다. |
| -- | -- |
| 4·6행 | 3행에서 대체해서 대입한 값인 b를 본래의 값인 df2020['항목'].values[i] 번째에 넣어서 출력하면 [사진 4-2]처럼 나온다.  |
5. df.query() 출력
df2020에서 '항목'(컬럼명)이 '식당'인 데이터프레임을 출력해보니 정상적으로 출력된다!
😭 어려웠던 점
솔직히 말하면 탈모 오는 줄 알았다... \xa0을 제거하는 방법은 인터넷에 검색하면 나오지만 데이터프레임에서 \xa0을 제거하는 방법은 아무리 검색해도 나오지 않았다.(내 검색 능력이 부족한 걸수도 ㅠㅠ) df2020['항목']의 각 행 모두 \xa0을 제거하는 반복 작업이니 반복문을 사용하면 어떨까 생각했다. 이 방법이 신의 한 수였다. 인터넷에 나와있다 한들 검색 능력이 부족하면 얻지 못하는 것이고 만약 나와 있지 않는데 스스로 해결할 능력이 부족하면 영원히 해결하지 못하는 법이다. 먼저 내 스스로 해결해보고 나서 안 되면 인터넷에 검색하는 것이 좋다. 그래야 해결방법을 온전히 내 것으로 만들 수 있고 오류를 해결할 능력이 한층 성장한다.
