VideoMAE 리뷰 [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training]
Video AI
요약
- ViT backbone을 가져와서, MAE에서 흔히 쓰는 pixel reconstruction loss를 활용하여 Training 한다.
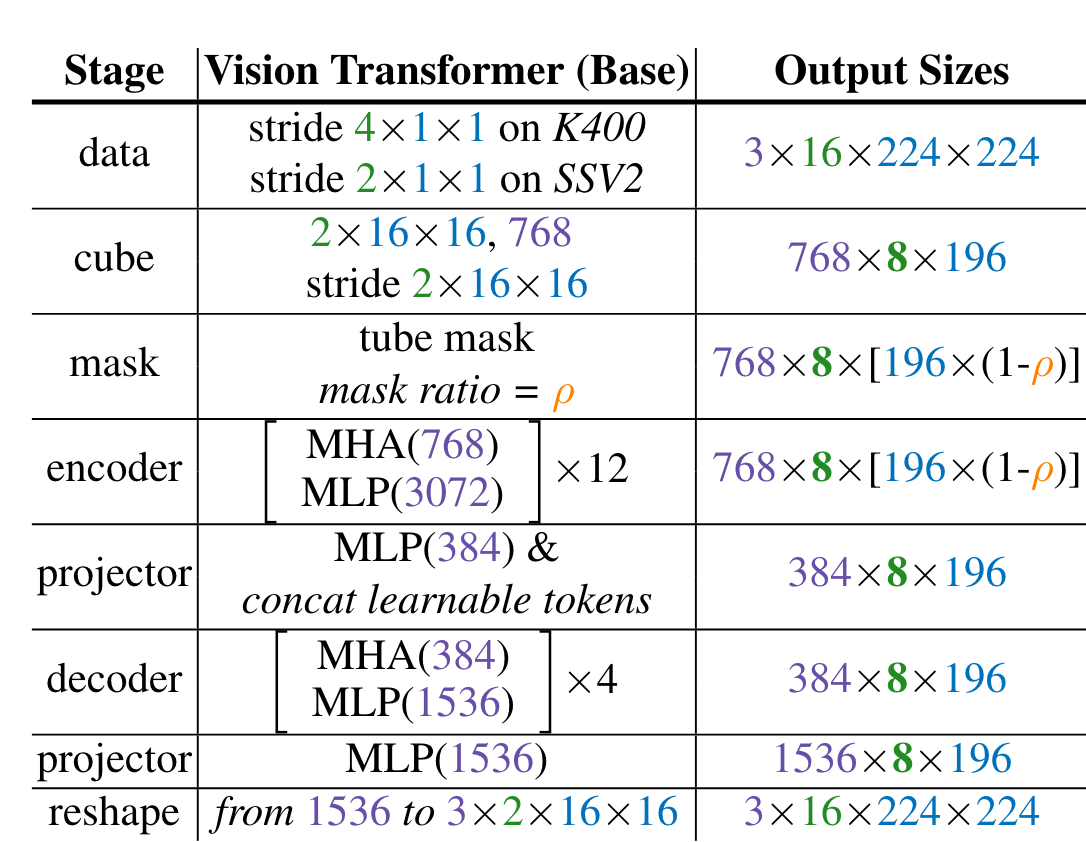
- 원본 데이터에서 적절한 frame stride를 통해서 16프레임을 한 단위로 묶어 학습하며, 21616 픽셀을 한 큐브로 삼아 큐브 임베딩을 한다. 그 다음 Tube Mask라는 이 논문에서 제시된 마스킹 기법을 활용하여 마스킹하고 ViT Encoder - Decoder 태워서 원본으로 복구한다.
- 64GPU on pretraining, 64GPU for finetuning on ststv2, kinetics400, 8GPUs for UCF101, HMD51, 32GPUs for AVA dataset. 코스트가 만만치 않다.
- Reconstruction 결과를 보면, 토큰 내부에서도 별로 콘텐츠 선명도가 없고, 토큰 끼리 분절도 심한 것 같다. Reconstruction을 그리 잘하는 것 같지는 않다.

문제의식
이 논문에서 풀고자 한 문제는 다음 한 문장으로 요약이 가능하다.
how to effectively and efficiently train a vanilla vision transformer on the video dataset itself without using any pre-trained model or extra image data?
풀어 보면 다음과 같다.
- Vanilla Vision Transformer를 Video Dataset에서 Pretrain하는 것이 목표이다.
- Training은 효과적 (High performance) 그리고 효율적 (Low cost)이어야 한다.
- Pretrained model을 사용하거나, 비디오 데이터가 아닌 Extra Image 데이터를 사용하지 않아야 한다.
3번 제약 조건이 비디오 모델의 궁극적 성능에 어떤 영향을 미치는지 궁금해진다.
방법론
동영상은 이미지의 시퀀스로 표현이 된다. 이는 실제 세계를 Temporal domain에서나 Spatial Domain에서나 Discrete한 Sampling을 취한 것이다. 우선 Temporal한 면만 생각해 보면, 동영상 데이터 이전에 있는 실제 물리적 세계는 그렇게 빠른 속도로 변화하지 않는다. 신호처리 이론을 생각해보면, Sampling frequency가 실제 신호의 최대 주파수의 두 배를 넘는다면 원래 신호를 손실 없이 복구할 수 있다. 그런데 동영상에서는 Spatial Structure의 변화의 빠르기가 그렇게 빠르지 않기 때문에, 1초에 수십 프레임이나 하는 sampling rate는 우리가 관심 있는 동영상 신호의 정보에 비해 너무 Redundant한 데이터 표현일 수 있다.
복잡하게 적었지만 동영상에서는 연속적인 프레임 사이에 중복되는 정보가 너무 많다는 말로 요약할 수 있다. 이는 다음과 같은 문제를 야기한다.
- 연속되는 프레임 사이 겹치는 정보가 너무 많고, Sampling rate는 너무 빠르다. 그래서 일단 Pretraining 단계에서 Temporal subsampling 없이 이미지 프레임들을 집어 넣어 주면 데이터의 비효율이 발생한다. 그리고 제한된 메모리 하에서 상대적으로 짧은 시간 단위만 볼 수 있다. 그래서 Scenery의 변화를 거의 모델이 보지 못할 것이다. 그래서 동영상에서 매우 정적인 피처만 추출할 수 있다. 그리고 정보가 Redundant하니 Pixel reconstruction task는 그냥 주변 픽셀 적절히 베끼면 풀 수 있다. 그래서 Task 난이도가 너무 떨어져서, Training에서도 비효율이 발생한다.
- 일반적인 방식으로 마스킹을 한다고 생각해보자. 이러면 마스킹을 하고 나서도 Temporally 인접한 프레임의 마스킹 안 된 토큰으로부터 단순히 베껴서 Pixel reconstruction을 할 수 있게 된다. 그래서 전체 3D cube Tokens를 단순히 random masking하면 안되고, Tube masking이라는 마스킹 전략을 사용해야 한다.

그래서 VideoMAE는 (1) Temporal subsampling, (2) Tube masking 을 사용하여 위 문제를 해결하려고 시도한다.
논문의 주요 내용은 위가 다이고, 전체적으로 단순하다.
바로 전체 알고리듬을 설명한다.
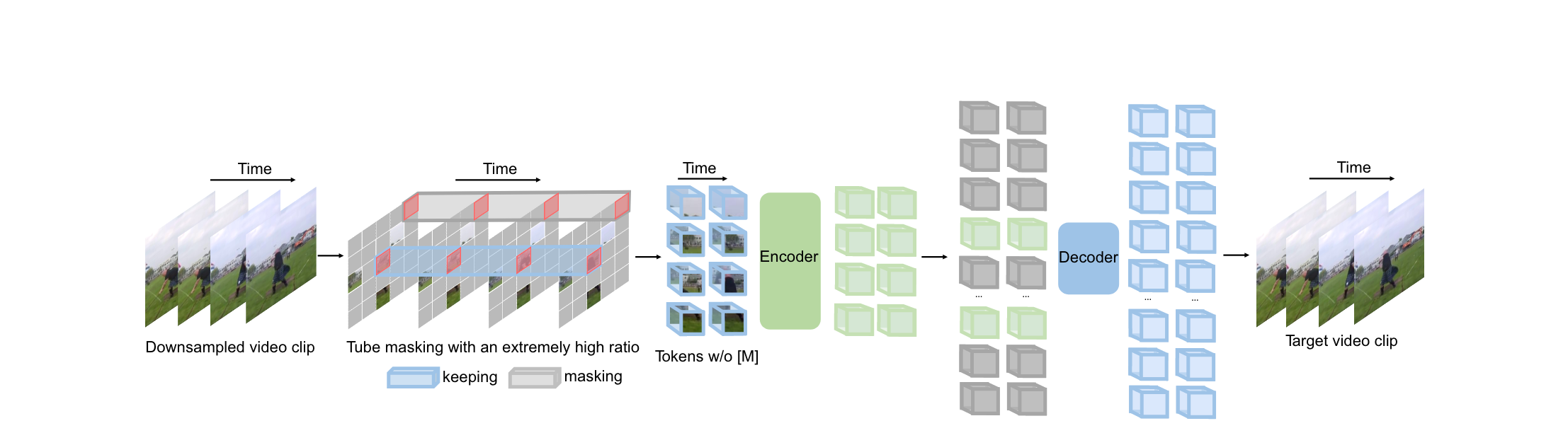
Tube masking
튜브 마스킹은 동영상에서 대부분의 이미지 장면이 변하지 않는다는 점을 고려하여 information leakage를 줄일 수 있도록 고안된 마스킹 기법이다. 바로 위의 그림을 참고하면 이해가 잘 될 것이다. 이미지가 n개의 토큰으로 쪼개졌다고 하면, 그 중 k개를 masking할 토큰으로 선정한다. 그러면 이 k개의 토큰은 전체 이미지 시퀀스에서 다 masking되고, 나머지 n-k개의 토큰은 전체 이미지 시퀀스에서 마스킹되지 않는다.
토큰들의 Temporal correlation을 잘 반영하는 마스킹 기법이라 할 수 있겠다.
아키텍처
ViT block으로 Encoder Decoder를 만든다.

- 동영상에서 Frame을 downsampling한다.
이미지 프레임은 224*224 사이즈로 잘라서 본다.
K400에서는 stride = 4로 뒀고, SSV2에서는 stride = 2로 두어서 frame downsampling을 하였다. 동영상에서 이미지프레임의 변화가 느릴수록 stride를 많이 두어도 괜찮을 것 같다.
이렇게 하여 16프레임을 뽑는다. 만큼의 시간 단위에서 inference 및 Training을 한다고 보면 되겠다. 더 긴 단위의 시간을 보려면 어떻게 해야하는지 궁금하다.
위의 샘플링을 하고 나면 의 블럭이 만들어진다. 3은 RGB channels이고, 16은 프레임 수, 224*224는 이미지의 height, width이다.
- Cube embedding
Transformer를 사용하려면 input 데이터를 Sequence of tokens로 만들어야 한다. 1단계에서 만든 커다란 블록을 사이즈의 더 작은 subblock블록으로 쪼갠다. 3은 채널 수, 2는 프레임 수이고, 16은 width, height값이다. 이러면 전체 블록은 81414 개의 subblock으로 쪼개질 것이다. 물론 채널 별로 따로 따로 쪼개진다.
그리고 이 subblock을 Linear cube embedding module로 768차원으로 임베딩한다. 당연히 이 cube embedding도 learnable할 것이다.
그러면 이 단계가 마무리될 때 7688196 차원으로 데이터가 처리될 것이다. 이는 768차원 토큰이 8*196 차원으로 배열된 것과 같고, 이때 8은 시간축으로 쌓인 차원, 196은 Spatial 축에서 펼쳐진 차원이다. 이제 이 Token의 2차원 sequence를 joint space-time attention ViT를 활용하여 처리한다.
- Tube masking
Tube masking startegy를 이용해 Input Token sequence를 masking한다. 그리고 Unmasked token만 모델에 넣어준다.
당연하지만 아마도 space-time encoding을 태워주겠지? 코드 확인해봐야 할 것 같다.
- Joint Space-Time attention을 사용한 ViT Encoder로 Input sequence를 Encoding한다.
- Encoding된 토큰 시퀀스의 알맞은 자리에 Learnable token을 끼워 넣어 주고 디코더 모듈에 요구하는 차원으로 Encodded vector sequence를 embedding한다.
- 인코더와 차원 수만 다른 Decoder를 활용하여 디코딩한다.
- 디코딩된 벡터를 FF network를 활용하여 Projection한다.
- Reshape하여 원래 이미지의 pixel을 복구한다.
위가 전체 알고리듬이고, Pixel reconstruction loss (MSE loss)를 learning objective로 사용하여 모델을 학습시킨다.
결과
벤치 결과 SOTA라고 말한다. SomethingSomethingV2에서의 벤치만 보자
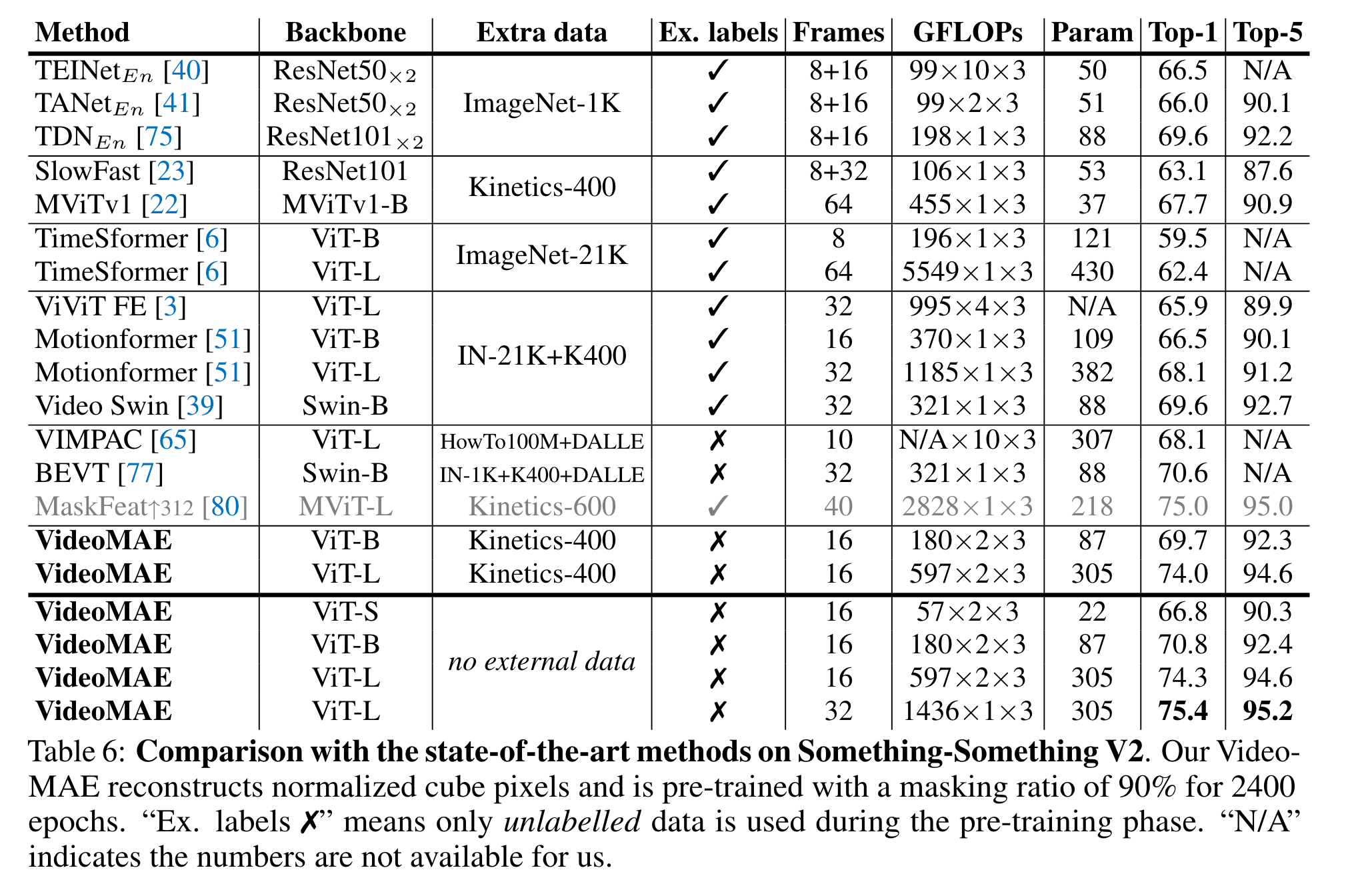
성능이 꽤 괜찮다. External data, image pretrained backbone 없이 오직 비디오를 활용한 프리트레이닝만으로 위와 같은 SOTA를 찍었다는 게 중요한 것 같다. 그나저나 위처럼 비교를 딱 해놓고 보니, 비디오 모델들의 연산량은 정말 어마무지한 것 같다.
나의 생각
인간이 보는 거의 모든 시각 정보는 Temporal sequence이다. 자연 세계에서 주어지는 데이터를 생각해보면 주로 어떤 continuous하게 변화하는 세상의 Latent state가 있고, 이 Latent state로부터 생성된 observation data를 처리하는 것이 인간이자 모든 물리적 entity가 해야할 것이다. 원래 자연으로부터 생성된 데이터는 무릇 그러하니깐.
그래서 내 생각은, 비디오 모델이 동물이 하는 시각 정보 처리와 더 비슷할 것이라는 점이다. 비디오를 잘하면 이미지를 잘 처리하는 능력은 자연스럽게 따라 나오지 않을까? 그리고 이미지를 처리할 때에도 Temporal dynamics를 고려하여 맥락 추론을 할 수 있을 것이다. 예를 들어 다음 이미지를 생각해 보라. 적당한 캡션은 “남자가 하늘을 날고 있다 또는 떨어지고 있다” 정도가 될 것이다. 그런데 만약 이 남자가 떨어지고 있는 것이라면, 이 남자는 보이는 주변 건물보다 훨씬 높은 위치에서 떨어지고 있으니깐, 비행기 또는 헬리콥터에서부터 떨어진 것이 물리적으로 상상 가능한 설명이 될 것이다. 즉 이 그림만 보고 시간적으로 전과 후를 상상해서 더 정확한 추론이 가능해지는 것이다. 물론 지금 든 생각이기 때문에 정리도 안 되어 있는 것 같고, 다양한 반론의 여지가 있을 수 있겠다.

어쨌거나 결론은, 더 자연스러워 보이는 동영상 데이터로부터 vision model을 pretrain하는 좋은 논문이므로, 의미가 깊다고 생각한다.
