Video AI
1.VideoMAE 리뷰 [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training]
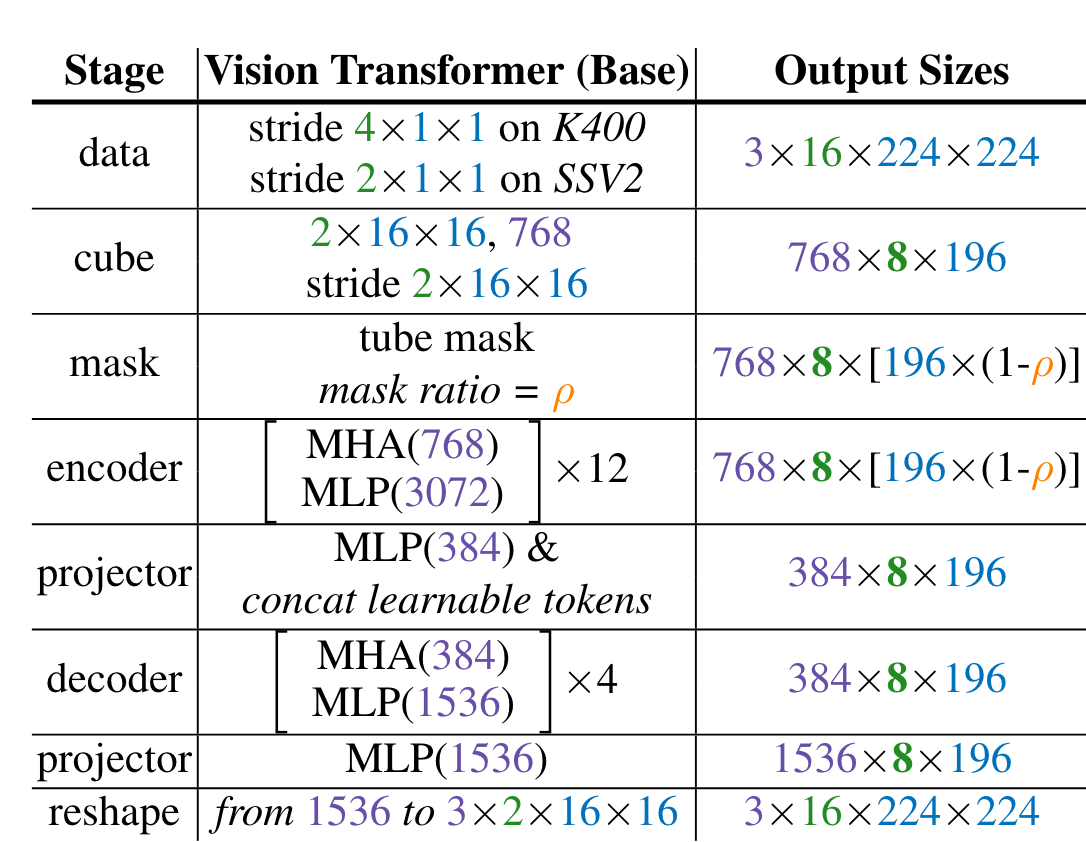
Pixel recontruction(MAE) 방식으로 vanilla ViT를 video data만으로 pretraining한다. Tube masking과 temporal subsampling을 활용한다. backbone에 joint space-time attention
2023년 10월 2일