Data Science
1.데이터 개념

data is facts or materials obtained by observation, experiment or investigation.data is in the form of letters, numbers, sounds, pictures, etc. that a
2.데이터 구조와 종류
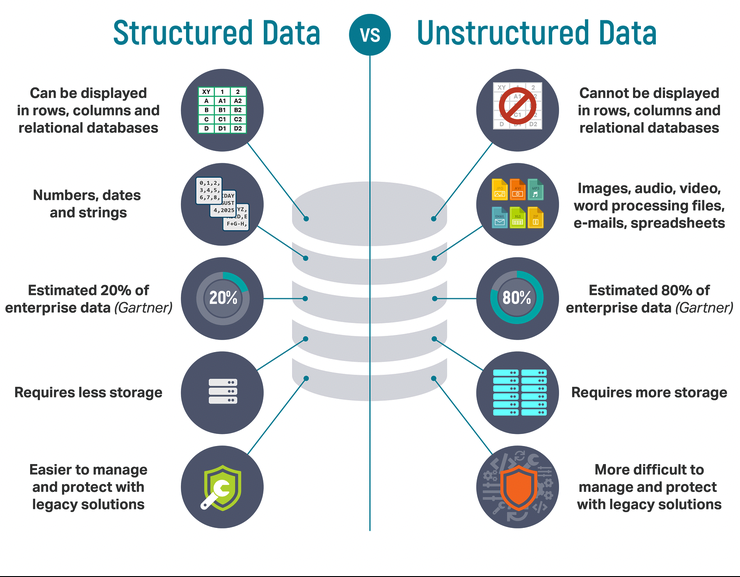
데이터 개체들의 집합❓데이터 개체 : 레코드(record), 점(point), 벡터(vector), 패턴(pattern), 사례(case), 사건(event), 샘플(sample), 관찰(observation), 개체(entity)등을 포함데이터 개체는 여러 속성(at
3.오픈 데이터의 종류와 형식

많은 정부기관이 엑세과 같은 스프레드시트로 정보를 관리스프레드시트는 서로 다른 컬람의 의미를 올바르게 기술하기 위해 사용 가능스프레드시트안에 다루기 어려운 매크로와 공식이 있기 때문에, 사용자가 읽기 쉽도록 해당 스프레드시트와 함께 계산 공식을 제공하는 것이 바람직CS
4.데이터 시대와 데이터 과학

데이터에 접근하고 활용할 수 있도록 협업하는 과정에서 데이터 생산, 인프라제공, 연구조사, 데이터 소비 등 서로 다른 역할을 담덩하는 구성원으로 이루어진 생태계정형, 반정형, 비정형, raw데이터 처리다양한 종류의 데이터를 결합저장 후에 정의되는 스키마저비용 스토리지
5.인코딩과 스케일링
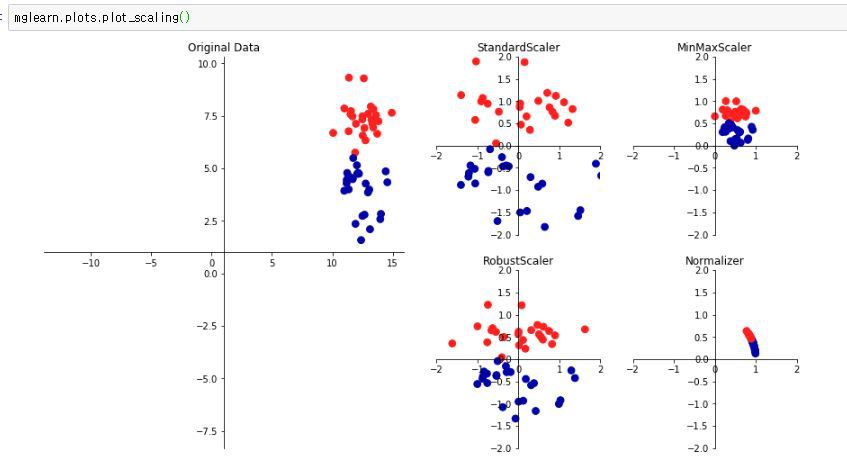
특성들의 범위를 정규화 해주는 작업특성마다 다른 범위를 가지는 경우 머신러닝 모델들이 제대로 학습되지 않을 가능성이 있다.(KNN, SVM, Nerual network모델, Clustering모델 등)특성들을 비교 분석하기 쉽게 만들어 준다.Linear Model, N
6.교차 검증과 앙상블
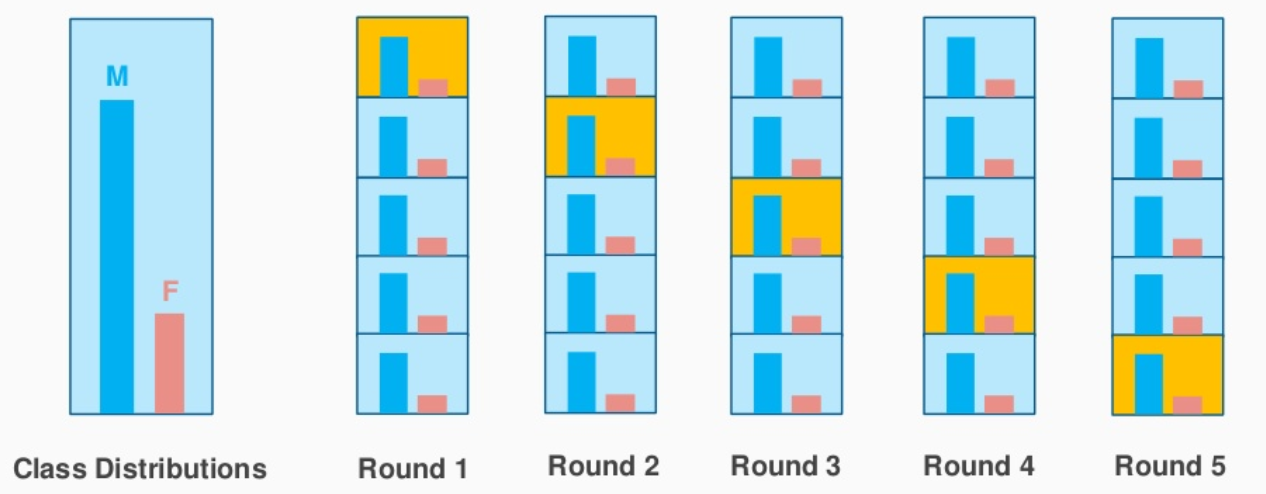
보통은 훈련 세트와 평가 세트로 나누어서 모델을 학습하고 평가그러나 고정된 평가 세트로 모델을 검증하면 평가 세트에 과적합되는 단점이를 방지하기 위해 교차검증은 훈련 세트를 평가 세트와 검증 세트로 분리한뒤 검증 세트를 사용해 검증하는 방식데이터의 여러부분을 학습하고
7.평가 지표
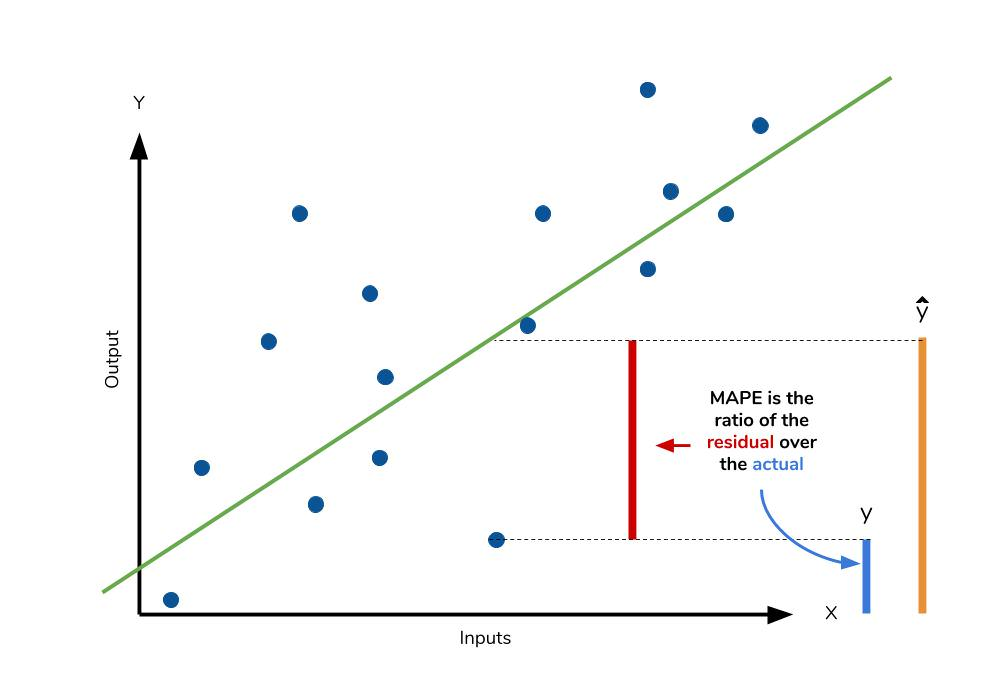
전체 데이터 중에서 예측 결과와 실제 값이 동일한 비율(TP+TN) / (TP+TN+FP+FN)양성으로 예측한 데이터 중 맞춘 양성 데이터의 비율정밀도는 음성을 양성으로 판단하는 것이 더 손해인 경우 사용(깐깐하게 봐야할 때 사용)TP / (TP+FP)실제 양성 데이터
8.머신러닝
머신러닝 명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게하는 연구분야 머신러닝은 데이터를 통해 다양한 패턴을 감지하고, 스스로 학습할 수 있는 모델 개발에 초점 머신러닝 분류 지도학습 지도학습은 주어진 입력으로부터 출력 값을 예측하고자 할 때 사용 입력과 정
9.지도 학습 알고리즘
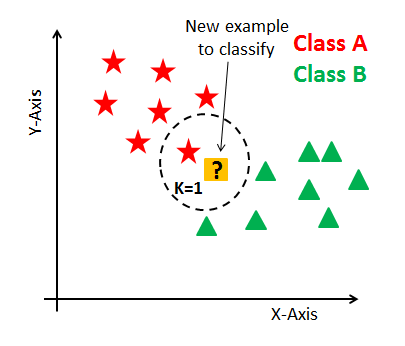
단순 성형 회귀(특성이 1개) : y=Wx+b다중 선형 회귀(특성이 여러개) : y=W1x1+W2x2+...+Wnxn+b 입력된 특성들로 선형함수를 만들어 예측경사하강법을 통해 훈련 데이터셋으로 부터 나타나는 오차를 최소화 할 수 있는 선 결정특성이 적은 경우 다른 모
10.통계 검정
관측 대상의 특성을 수량화 하기위해 단위나 규칙을 가지고특성에 숫자를 부여한 것(질적 자료 ➡️ 양적 자료)명목 척도 : 관찰하는 대상의 속성에 따라 그 값에 숫자 부여한 것 (라벨 인코딩)서열 척도 : 관찰하는 대상의 특성을 측정해서 그 값을 순위로 나타낸 것 등간