인코딩
데이터 인코딩이 필요한 이유
- 사이킷런의 머신러닝 알고리즘은 입력값으로 문자열을 받지 않는다.
- 따라서 모든 문자열은 숫자형으로 인코당돼야한다.
레이블 인코딩 vs 원-핫 인코딩
레이블 인코딩
- 카테고리 피처를 코드형 숫자 값으로 변환한 것이다.
- 변환된 숫자의 크고 작음은 특성과 관계없이 단지 순서에 기인할 뿐이다.
- 그러나 알고리즘에 따라서 숫자의 크고 작음에 의미를 부여하는 경우 성능이 떨어지게된다.
- ❗️트리계열의 알고리즘의 경우에는 숫자의 크고 작음에 영향을 받지 않는다.
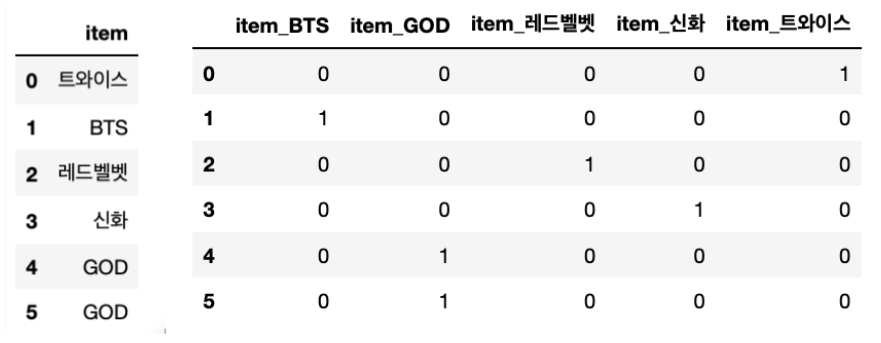
원-핫 인코딩
- 선형 알고리즘 처럼 인코딩된 숫자의 크고 작음이 알고리즘의 성능에 영향을 끼치는 모델에 사용된다.
- 피처 값의 유형에 따라 새로운 피처를 추가하고, 고유 값에 해당하는 칼럼에만 1을 표시하고 나머지에는 0을 표시한다.
스케일링
데이터 스케일링
- 특성들의 범위를 정규화 해주는 작업
- 특성마다 다른 범위를 가지는 경우 머신러닝 모델들이 제대로 학습되지 않을 가능성이 있다.
- 스케일링에 민감한 모델
경사하강법 기반 모델(Linear regression, Logistic Regression, Neural Network등)
거리 기반 모델(KNN, K-means, SVM등) - 스케일링에 비교적 덜 민감한 모델
논리기반 모델(decision tree, bagging, random forests, boosting등)
데이터 스케일링의 장점
- 특성들을 비교 분석하기 쉽게 만들어 준다.
- Linear Model, Neural network Model등에서 학습의 안정성과 속도를 개선시킨다.
- 하지만 특성에 따라 원래 범위를 유지하는게 좋을 경우는 scaling을 하지 않아도 된다.
데이터 스케일링의 종류
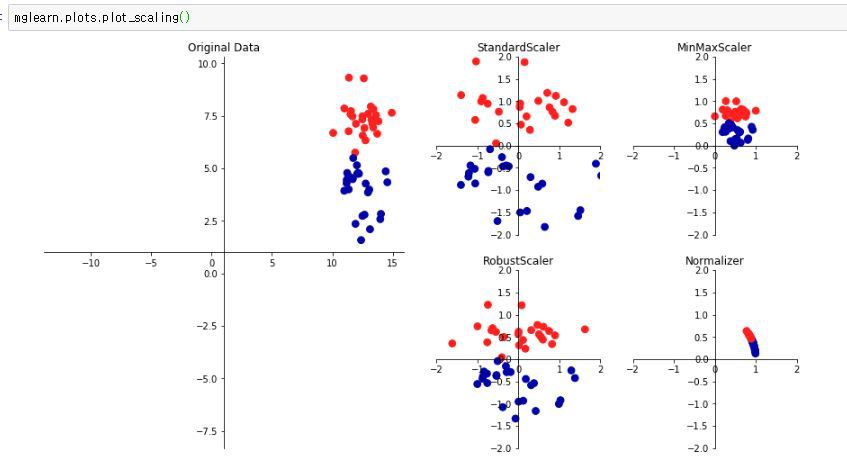
1. StandardScaler(표준화)
- 변수의 평균, 표준편차를 이용해 정규분포 형태로 변환(평균0,분산1)
- 이상치(Outlier)에 민감하게 영향을 받는다.
- 회귀보다 분류에 유용하다
2. RobustScaler
- 변수의 사분위수를 이용해 변환
- 이상치(Outlier)의 영향을 최소화 해준다.
3. MinMaxScaler(정규화)
- Max값, Min값을 이용해 0~1 사이값으로 변환
- 이상치(Outlier)에 민감하게 영향을 받는다.
- 분류보다 회귀에 유용하다.
4. MaxAbsScaler
- 각 특성을 절대값이 0과 1사이가 되도록 변환
- 모든 값은 -1과 1사이로 표현된다.(데이터가 양수일 경우 MinMaxScaler와 같다.)
5. Normalizer
- 특성 벡터의 길이가 1이 되도록 조정(행마다 정규화 진행)
- 특성 벡터의 길이는 상관 없고 데이터의 방향(각도)만 중요할 때 사용
- 주로 추천 시스템에서 사용
데이터 스케일링의 주의점
- 대부분의 경우 이상치를 먼저 제거하고 데이터 스케일링을 진행하는 것이 좋다.
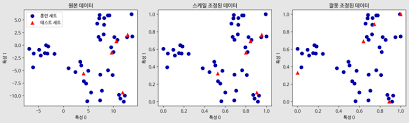
(이를 위해 IQR turkey나 outlier detection 알고리즘을 선행하면 좋다.) - 스케일러는 훈련 세트에 fit한 이후에 테스트 세트에 적용해야 한다.
(훈련 세트에는 fit_transform(), 테스트 세트에는 transfom()을 사용해야 데이터 누수 방지가능) - 훈련 세트와 테스트 세트에 같은 변환을 적용해야한다.
- 그러나 특성에 따라 다른 스케일러를 적용해도 된다.
- 로그화와 정규화 중 로그화를 먼저 진행하는 것이 좋다.
(로그화는 skewed 되어있는 데이터의 왜곡을 줄이기 위한 것이기 때문에 정규화 이전에 선행되어야 한다.) - 일반적으로 타겟에 대한 데이터 스케일링은 진행하지 않는다.
- StandardScaler의 경우, 훈련세트의 평균과 표준편차를 이용해 훈련세트를 변환하고, 테스트 세트의 평균과 표준편차를 이용해 테스트 세트를 변환하면 잘못된 결과가 나온다.

velog에는 이론을 주로 정리하고, 코드와 관련된 것은 Git-hub로 관리하고 있어요. 포트폴리오는 링크된 Yun Lab 홈페이지를 참고해주시면 감사하겠습니다!